 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking AI for low-resource contexts: Thinking beyond leaderboards
May 27, 2026Existing AI evaluation practices often fail to capture how systems actually perform in low-resource environments, where operational constraints shape usability as much as model quality. Through a structured analysis of existing benchmark families across speech, chat/RAG, and vision systems, we identify critical gaps between laboratory evaluation practices and real-world deployment conditions in low-resource environments. We argue that the meaningful unit of assessment is the deployed system rather than an isolated model and that effective evaluation frameworks must integrate task performance with deployment conditions such as noisy inputs, code-switching, intermittent connectivity, low-end hardware, and domain shift. At the same time, benchmarks should recognize that different application classes require distinct evaluation profiles rather than a single aggregate score that obscures operational differences. To support practical decision-making, we propose a shared reporting framework that preserves comparability across systems and application types while remaining sensitive to deployment context. Finally, we emphasize the need for concise and actionable reporting artifacts for policymakers, donors, and implementers, including standardized one-page benchmark cards, deployment profiles, and explicit documentation of failure handling procedures and human oversight mechanisms.
BOLLWM: A real-world dataset for bollworm pest monitoring from cotton fields in India
Apr 03, 2023



This paper presents a dataset of agricultural pest images captured over five years by thousands of small holder farmers and farming extension workers across India. The dataset has been used to support a mobile application that relies on artificial intelligence to assist farmers with pest management decisions. Creation came from a mix of organized data collection, and from mobile application usage that was less controlled. This makes the dataset unique within the pest detection community, exhibiting a number of characteristics that place it closer to other non-agricultural objected detection datasets. This not only makes the dataset applicable to future pest management applications, it opens the door for a wide variety of other research agendas.
A Case for Rejection in Low Resource ML Deployment
Aug 15, 2022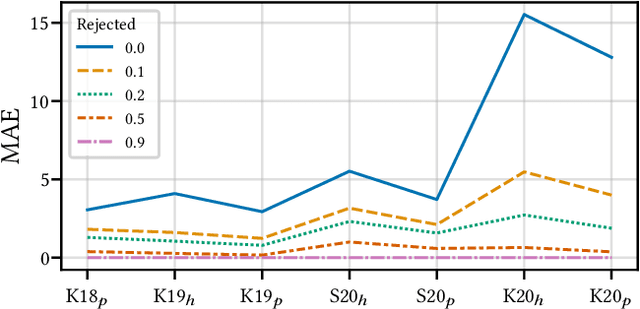
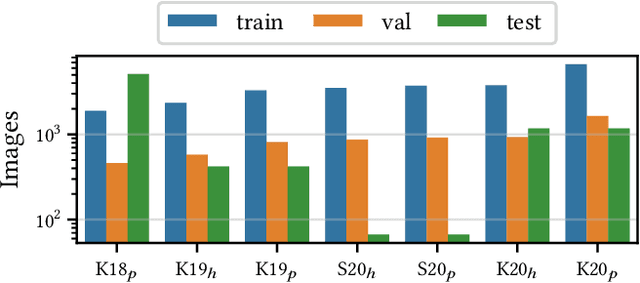
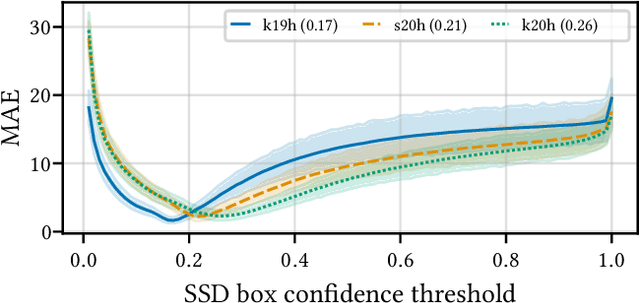
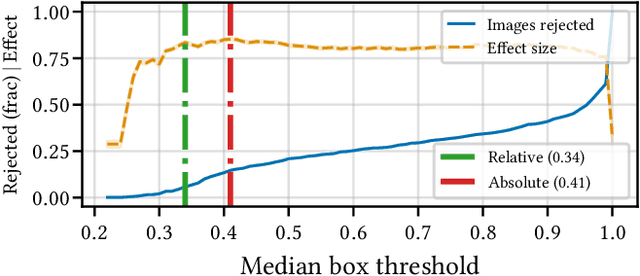
Building reliable AI decision support systems requires a robust set of data on which to train models; both with respect to quantity and diversity. Obtaining such datasets can be difficult in resource limited settings, or for applications in early stages of deployment. Sample rejection is one way to work around this challenge, however much of the existing work in this area is ill-suited for such scenarios. This paper substantiates that position and proposes a simple solution as a proof of concept baseline.