 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottleneck Transformer-Based Approach for Improved Automatic STOI Score Prediction
Feb 17, 2026In this study, we have presented a novel approach to predict the Short-Time Objective Intelligibility (STOI) metric using a bottleneck transformer architecture. Traditional methods for calculating STOI typically requires clean reference speech, which limits their applicability in the real world. To address this, numerous deep learning-based nonintrusive speech assessment models have garnered significant interest. Many studies have achieved commendable performance, but there is room for further improvement. We propose the use of bottleneck transformer, incorporating convolution blocks for learning frame-level features and a multi-head self-attention (MHSA) layer to aggregate the information. These components enable the transformer to focus on the key aspects of the input data. Our model has shown higher correlation and lower mean squared error for both seen and unseen scenarios compared to the state-of-the-art model using self-supervised learning (SSL) and spectral features as inputs.
Tracing Linguistic Relations in Winning and Losing Sides of Explicit Opposing Groups
Mar 01, 2017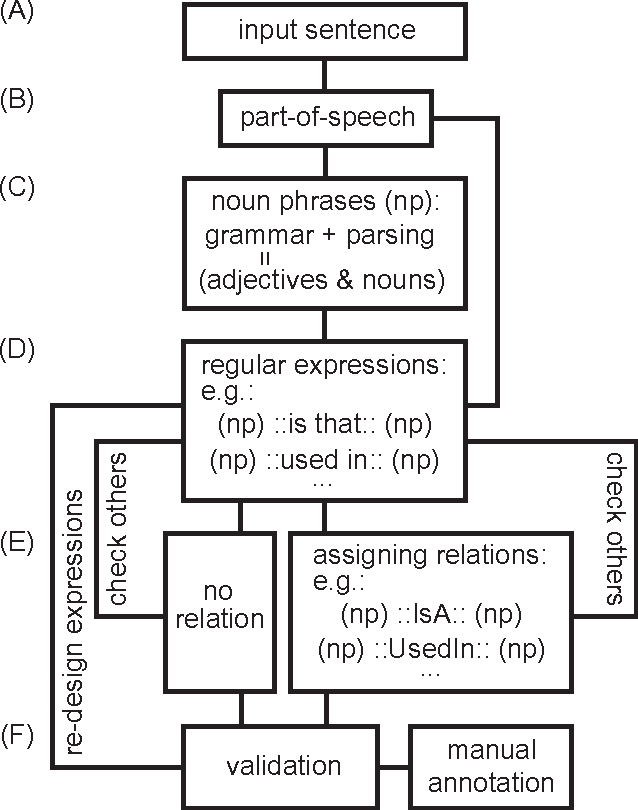
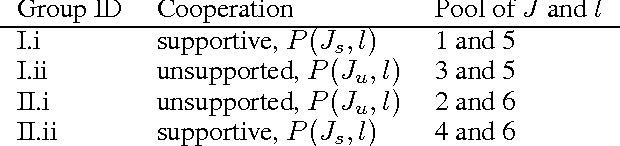
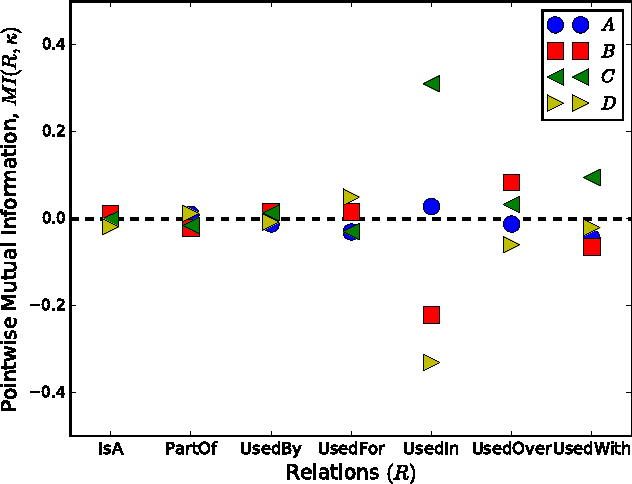
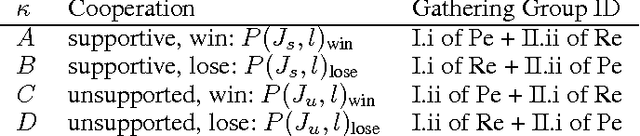
Linguistic relations in oral conversations present how opinions are constructed and developed in a restricted time. The relations bond ideas, arguments, thoughts, and feelings, re-shape them during a speech, and finally build knowledge out of all information provided in the conversation. Speakers share a common interest to discuss. It is expected that each speaker's reply includes duplicated forms of words from previous speakers. However, linguistic adaptation is observed and evolves in a more complex path than just transferring slightly modified versions of common concepts. A conversation aiming a benefit at the end shows an emergent cooperation inducing the adaptation. Not only cooperation, but also competition drives the adaptation or an opposite scenario and one can capture the dynamic process by tracking how the concepts are linguistically linked. To uncover salient complex dynamic events in verbal communications, we attempt to discover self-organized linguistic relations hidden in a conversation with explicitly stated winners and losers. We examine open access data of the United States Supreme Court. Our understanding is crucial in big data research to guide how transition states in opinion mining and decision-making should be modeled and how this required knowledge to guide the model should be pinpointed, by filtering large amount of data.