 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Driven Approach to Support Clinical Renal Replacement Therapy
Feb 26, 2026This study investigates a data-driven machine learning approach to predict membrane fouling in critically ill patients undergoing Continuous Renal Replacement Therapy (CRRT). Using time-series data from an ICU, 16 clinically selected features were identified to train predictive models. To ensure interpretability and enable reliable counterfactual analysis, the researchers adopted a tabular data approach rather than modeling temporal dependencies directly. Given the imbalance between fouling and non-fouling cases, the ADASYN oversampling technique was applied to improve minority class representation. Random Forest, XGBoost, and LightGBM models were tested, achieving balanced performance with 77.6% sensitivity and 96.3% specificity at a 10% rebalancing rate. Results remained robust across different forecasting horizons. Notably, the tabular approach outperformed LSTM recurrent neural networks, suggesting that explicit temporal modeling was not necessary for strong predictive performance. Feature selection further reduced the model to five key variables, improving simplicity and interpretability with minimal loss of accuracy. A Shapley value-based counterfactual analysis was applied to the best-performing model, successfully identifying minimal input changes capable of reversing fouling predictions. Overall, the findings support the viability of interpretable machine learning models for predicting membrane fouling during CRRT. The integration of prediction and counterfactual analysis offers practical clinical value, potentially guiding therapeutic adjustments to reduce fouling risk and improve patient management.
Binary Kernel Logistic Regression: a sparsity-inducing formulation and a convergent decomposition training algorithm
Dec 22, 2025Kernel logistic regression (KLR) is a widely used supervised learning method for binary and multi-class classification, which provides estimates of the conditional probabilities of class membership for the data points. Unlike other kernel methods such as Support Vector Machines (SVMs), KLRs are generally not sparse. Previous attempts to deal with sparsity in KLR include a heuristic method referred to as the Import Vector Machine (IVM) and ad hoc regularizations such as the $\ell_{1/2}$-based one. Achieving a good trade-off between prediction accuracy and sparsity is still a challenging issue with a potential significant impact from the application point of view. In this work, we revisit binary KLR and propose an extension of the training formulation proposed by Keerthi et al., which is able to induce sparsity in the trained model, while maintaining good testing accuracy. To efficiently solve the dual of this formulation, we devise a decomposition algorithm of Sequential Minimal Optimization type which exploits second-order information, and for which we establish global convergence. Numerical experiments conducted on 12 datasets from the literature show that the proposed binary KLR approach achieves a competitive trade-off between accuracy and sparsity with respect to IVM, $\ell_{1/2}$-based regularization for KLR, and SVM while retaining the advantages of providing informative estimates of the class membership probabilities.
Soft regression trees: a model variant and a decomposition training algorithm
Jan 10, 2025



Decision trees are widely used for classification and regression tasks in a variety of application fields due to their interpretability and good accuracy. During the past decade, growing attention has been devoted to globally optimized decision trees with deterministic or soft splitting rules at branch nodes, which are trained by optimizing the error function over all the tree parameters. In this work, we propose a new variant of soft multivariate regression trees (SRTs) where, for every input vector, the prediction is defined as the linear regression associated to a single leaf node, namely, the leaf node obtained by routing the input vector from the root along the branches with higher probability. SRTs exhibit the conditional computational property, i.e., each prediction depends on a small number of nodes (parameters), and our nonlinear optimization formulation for training them is amenable to decomposition. After showing a universal approximation result for SRTs, we present a decomposition training algorithm including a clustering-based initialization procedure and a heuristic for reassigning the input vectors along the tree. Under mild assumptions, we establish asymptotic convergence guarantees. Experiments on 15 wellknown datasets indicate that our SRTs and decomposition algorithm yield higher accuracy and robustness compared with traditional soft regression trees trained using the nonlinear optimization formulation of Blanquero et al., and a significant reduction in training times as well as a slightly better average accuracy compared with the mixed-integer optimization approach of Bertsimas and Dunn. We also report a comparison with the Random Forest ensemble method.
On multivariate randomized classification trees: $l_0$-based sparsity, VC~dimension and decomposition methods
Dec 15, 2021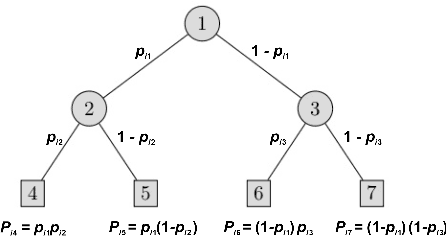
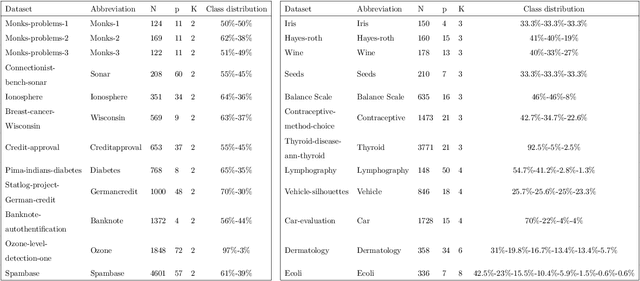
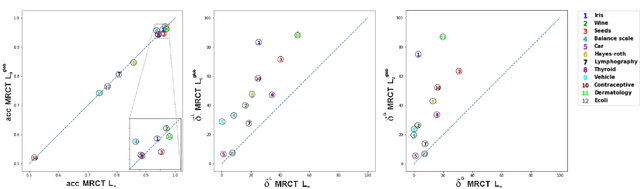
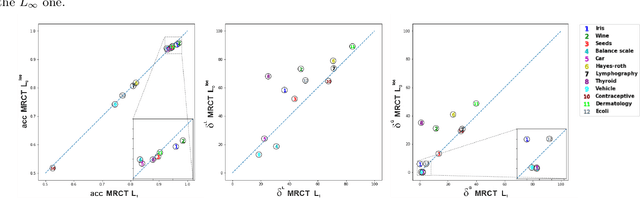
Decision trees are widely-used classification and regression models because of their interpretability and good accuracy. Classical methods such as CART are based on greedy approaches but a growing attention has recently been devoted to optimal decision trees. We investigate the nonlinear continuous optimization formulation proposed in Blanquero et al. (EJOR, vol. 284, 2020; COR, vol. 132, 2021) for (sparse) optimal randomized classification trees. Sparsity is important not only for feature selection but also to improve interpretability. We first consider alternative methods to sparsify such trees based on concave approximations of the $l_{0}$ ``norm". Promising results are obtained on 24 datasets in comparison with $l_1$ and $l_{\infty}$ regularizations. Then, we derive bounds on the VC dimension of multivariate randomized classification trees. Finally, since training is computationally challenging for large datasets, we propose a general decomposition scheme and an efficient version of it. Experiments on larger datasets show that the proposed decomposition method is able to significantly reduce the training times without compromising the accuracy.