 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Information Factorization
Sep 28, 2018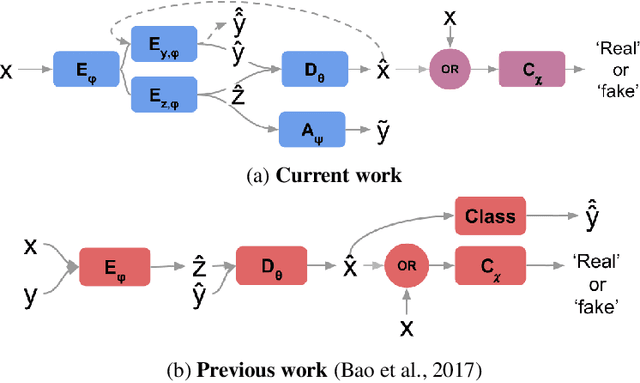
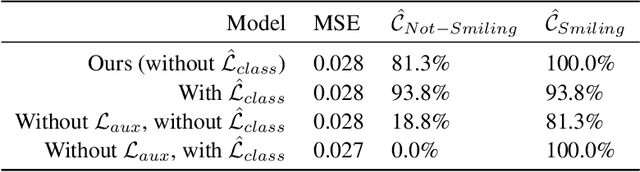
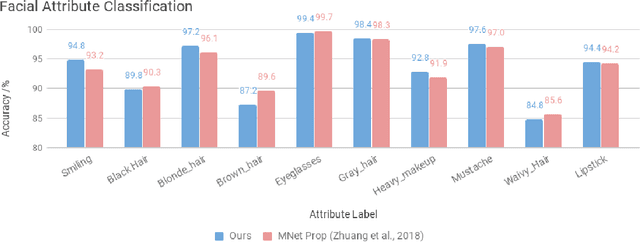

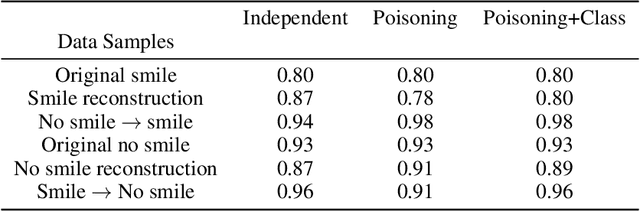
We propose a novel generative model architecture designed to learn representations for images that factor out a single attribute from the rest of the representation. A single object may have many attributes which when altered do not change the identity of the object itself. Consider the human face; the identity of a particular person is independent of whether or not they happen to be wearing glasses. The attribute of wearing glasses can be changed without changing the identity of the person. However, the ability to manipulate and alter image attributes without altering the object identity is not a trivial task. Here, we are interested in learning a representation of the image that separates the identity of an object (such as a human face) from an attribute (such as 'wearing glasses'). We demonstrate the success of our factorization approach by using the learned representation to synthesize the same face with and without a chosen attribute. We refer to this specific synthesis process as image attribute manipulation. We further demonstrate that our model achieves competitive scores, with state of the art, on a facial attribute classification task.
Inverting The Generator Of A Generative Adversarial Network (II)
Feb 15, 2018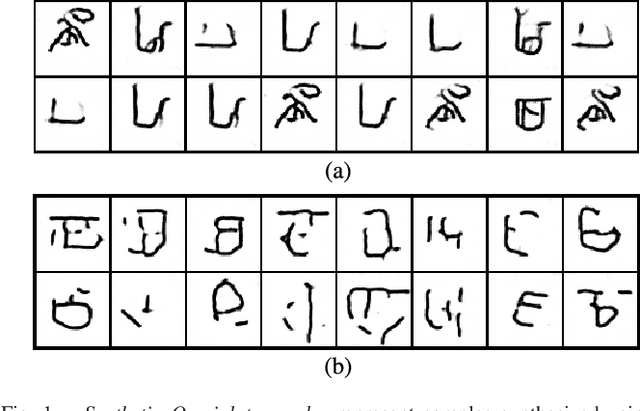


Generative adversarial networks (GANs) learn a deep generative model that is able to synthesise novel, high-dimensional data samples. New data samples are synthesised by passing latent samples, drawn from a chosen prior distribution, through the generative model. Once trained, the latent space exhibits interesting properties, that may be useful for down stream tasks such as classification or retrieval. Unfortunately, GANs do not offer an "inverse model", a mapping from data space back to latent space, making it difficult to infer a latent representation for a given data sample. In this paper, we introduce a technique, inversion, to project data samples, specifically images, to the latent space using a pre-trained GAN. Using our proposed inversion technique, we are able to identify which attributes of a dataset a trained GAN is able to model and quantify GAN performance, based on a reconstruction loss. We demonstrate how our proposed inversion technique may be used to quantitatively compare performance of various GAN models trained on three image datasets. We provide code for all of our experiments, https://github.com/ToniCreswell/InvertingGAN.
Denoising Adversarial Autoencoders
Jan 04, 2018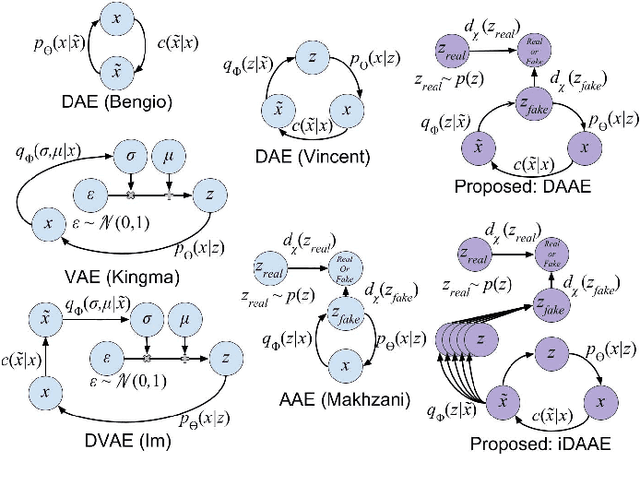
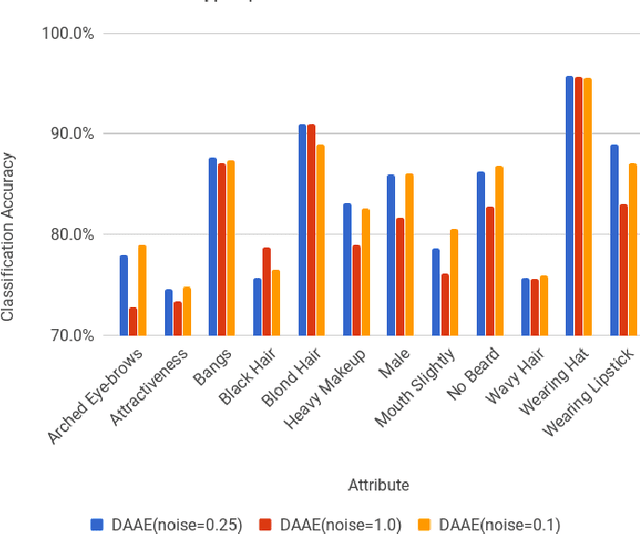

Unsupervised learning is of growing interest because it unlocks the potential held in vast amounts of unlabelled data to learn useful representations for inference. Autoencoders, a form of generative model, may be trained by learning to reconstruct unlabelled input data from a latent representation space. More robust representations may be produced by an autoencoder if it learns to recover clean input samples from corrupted ones. Representations may be further improved by introducing regularisation during training to shape the distribution of the encoded data in latent space. We suggest denoising adversarial autoencoders, which combine denoising and regularisation, shaping the distribution of latent space using adversarial training. We introduce a novel analysis that shows how denoising may be incorporated into the training and sampling of adversarial autoencoders. Experiments are performed to assess the contributions that denoising makes to the learning of representations for classification and sample synthesis. Our results suggest that autoencoders trained using a denoising criterion achieve higher classification performance, and can synthesise samples that are more consistent with the input data than those trained without a corruption process.
Denoising Adversarial Autoencoders: Classifying Skin Lesions Using Limited Labelled Training Data
Jan 02, 2018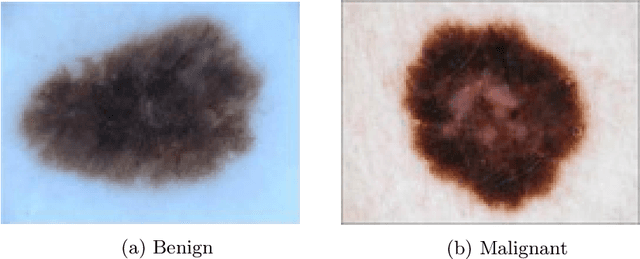


We propose a novel deep learning model for classifying medical images in the setting where there is a large amount of unlabelled medical data available, but labelled data is in limited supply. We consider the specific case of classifying skin lesions as either malignant or benign. In this setting, the proposed approach -- the semi-supervised, denoising adversarial autoencoder -- is able to utilise vast amounts of unlabelled data to learn a representation for skin lesions, and small amounts of labelled data to assign class labels based on the learned representation. We analyse the contributions of both the adversarial and denoising components of the model and find that the combination yields superior classification performance in the setting of limited labelled training data.
LatentPoison - Adversarial Attacks On The Latent Space
Nov 08, 2017
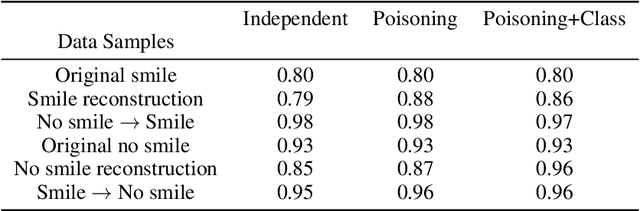
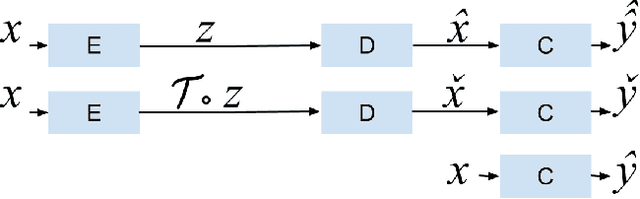
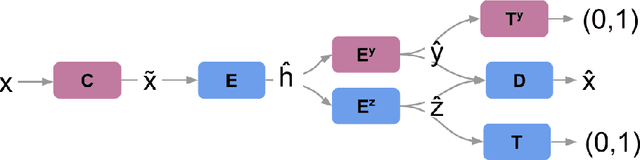
Robustness and security of machine learning (ML) systems are intertwined, wherein a non-robust ML system (classifiers, regressors, etc.) can be subject to attacks using a wide variety of exploits. With the advent of scalable deep learning methodologies, a lot of emphasis has been put on the robustness of supervised, unsupervised and reinforcement learning algorithms. Here, we study the robustness of the latent space of a deep variational autoencoder (dVAE), an unsupervised generative framework, to show that it is indeed possible to perturb the latent space, flip the class predictions and keep the classification probability approximately equal before and after an attack. This means that an agent that looks at the outputs of a decoder would remain oblivious to an attack.
Generative Adversarial Networks: An Overview
Oct 19, 2017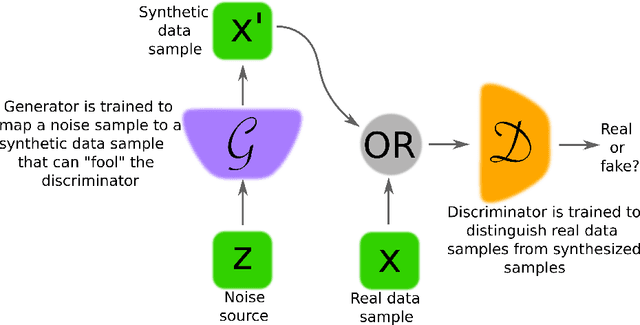
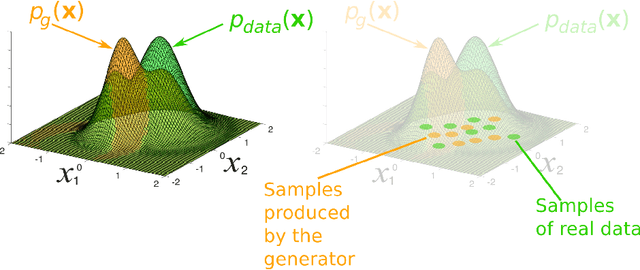
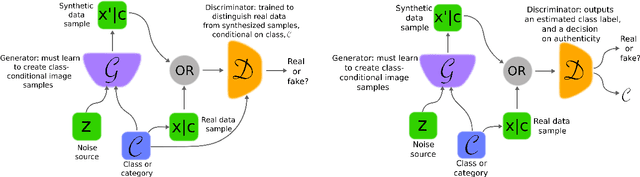
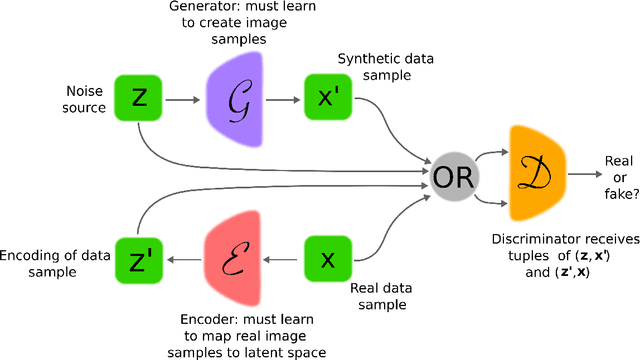
Generative adversarial networks (GANs) provide a way to learn deep representations without extensively annotated training data. They achieve this through deriving backpropagation signals through a competitive process involving a pair of networks. The representations that can be learned by GANs may be used in a variety of applications, including image synthesis, semantic image editing, style transfer, image super-resolution and classification. The aim of this review paper is to provide an overview of GANs for the signal processing community, drawing on familiar analogies and concepts where possible. In addition to identifying different methods for training and constructing GANs, we also point to remaining challenges in their theory and application.
On denoising autoencoders trained to minimise binary cross-entropy
Oct 09, 2017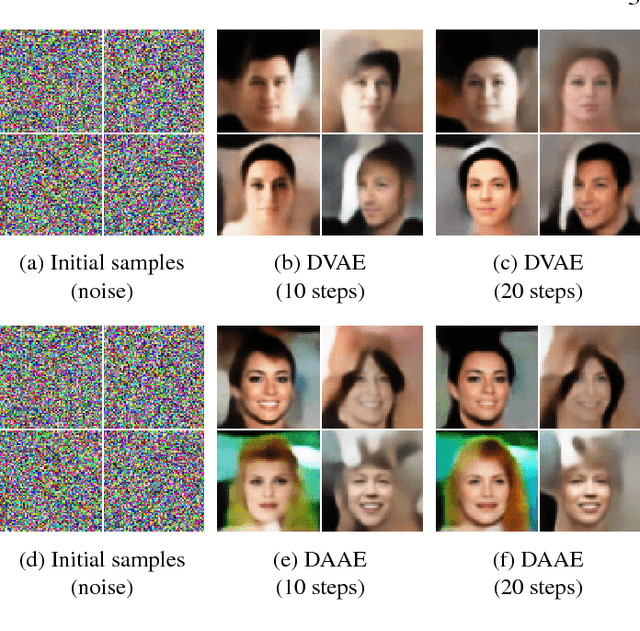


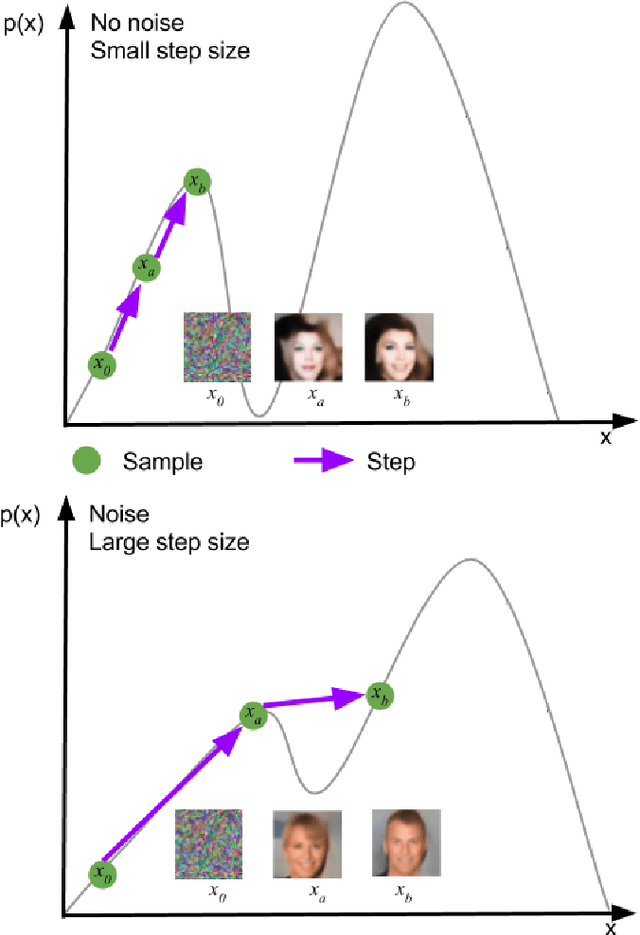
Denoising autoencoders (DAEs) are powerful deep learning models used for feature extraction, data generation and network pre-training. DAEs consist of an encoder and decoder which may be trained simultaneously to minimise a loss (function) between an input and the reconstruction of a corrupted version of the input. There are two common loss functions used for training autoencoders, these include the mean-squared error (MSE) and the binary cross-entropy (BCE). When training autoencoders on image data a natural choice of loss function is BCE, since pixel values may be normalised to take values in [0,1] and the decoder model may be designed to generate samples that take values in (0,1). We show theoretically that DAEs trained to minimise BCE may be used to take gradient steps in the data space towards regions of high probability under the data-generating distribution. Previously this had only been shown for DAEs trained using MSE. As a consequence of the theory, iterative application of a trained DAE moves a data sample from regions of low probability to regions of higher probability under the data-generating distribution. Firstly, we validate the theory by showing that novel data samples, consistent with the training data, may be synthesised when the initial data samples are random noise. Secondly, we motivate the theory by showing that initial data samples synthesised via other methods may be improved via iterative application of a trained DAE to those initial samples.
Improving Sampling from Generative Autoencoders with Markov Chains
Jan 12, 2017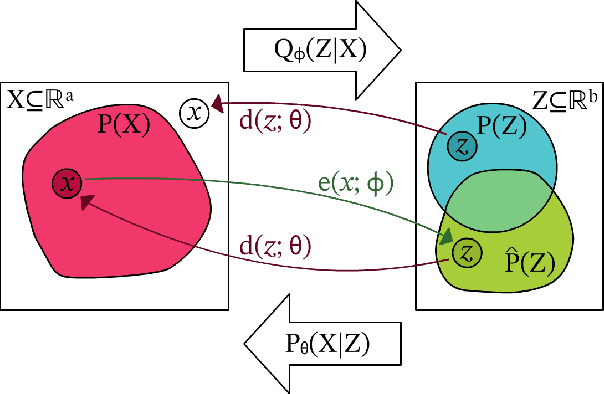



We focus on generative autoencoders, such as variational or adversarial autoencoders, which jointly learn a generative model alongside an inference model. Generative autoencoders are those which are trained to softly enforce a prior on the latent distribution learned by the inference model. We call the distribution to which the inference model maps observed samples, the learned latent distribution, which may not be consistent with the prior. We formulate a Markov chain Monte Carlo (MCMC) sampling process, equivalent to iteratively decoding and encoding, which allows us to sample from the learned latent distribution. Since, the generative model learns to map from the learned latent distribution, rather than the prior, we may use MCMC to improve the quality of samples drawn from the generative model, especially when the learned latent distribution is far from the prior. Using MCMC sampling, we are able to reveal previously unseen differences between generative autoencoders trained either with or without a denoising criterion.
Inverting The Generator Of A Generative Adversarial Network
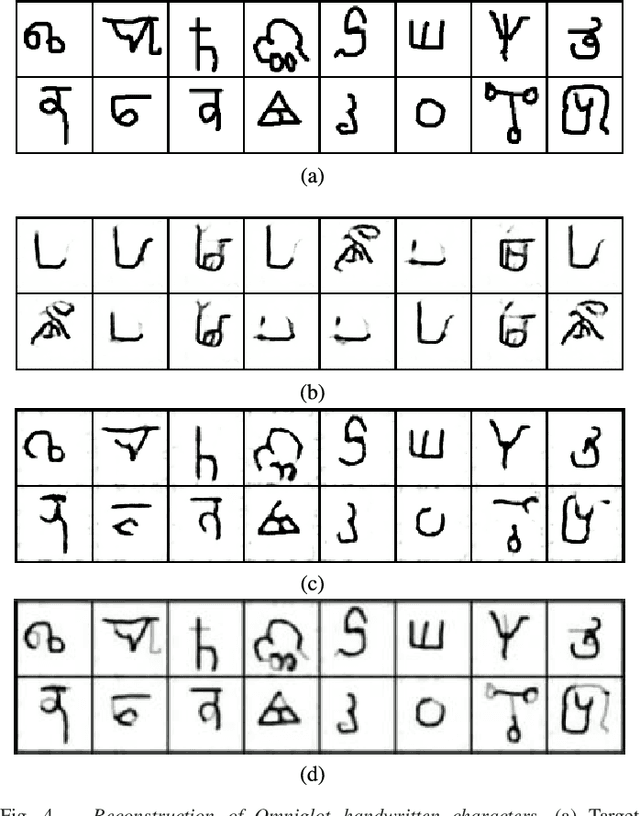
Nov 17, 2016Generative adversarial networks (GANs) learn to synthesise new samples from a high-dimensional distribution by passing samples drawn from a latent space through a generative network. When the high-dimensional distribution describes images of a particular data set, the network should learn to generate visually similar image samples for latent variables that are close to each other in the latent space. For tasks such as image retrieval and image classification, it may be useful to exploit the arrangement of the latent space by projecting images into it, and using this as a representation for discriminative tasks. GANs often consist of multiple layers of non-linear computations, making them very difficult to invert. This paper introduces techniques for projecting image samples into the latent space using any pre-trained GAN, provided that the computational graph is available. We evaluate these techniques on both MNIST digits and Omniglot handwritten characters. In the case of MNIST digits, we show that projections into the latent space maintain information about the style and the identity of the digit. In the case of Omniglot characters, we show that even characters from alphabets that have not been seen during training may be projected well into the latent space; this suggests that this approach may have applications in one-shot learning.
Task Specific Adversarial Cost Function
Sep 27, 2016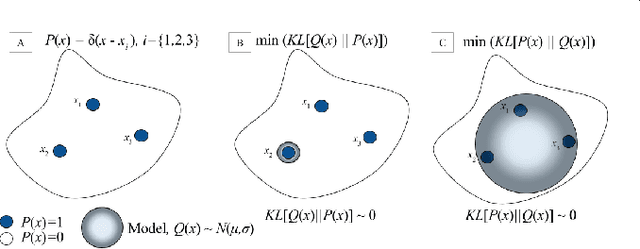

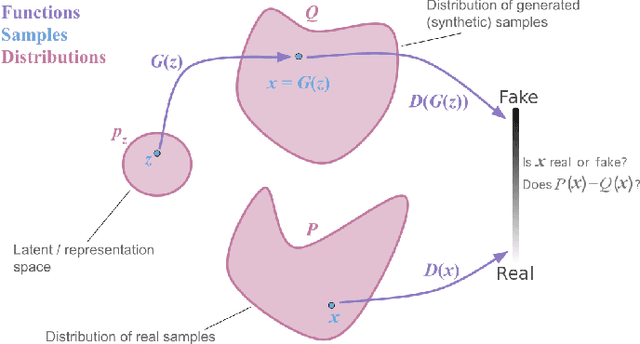
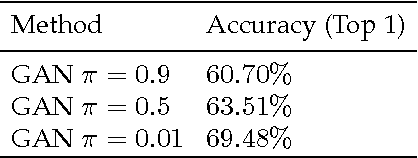
The cost function used to train a generative model should fit the purpose of the model. If the model is intended for tasks such as generating perceptually correct samples, it is beneficial to maximise the likelihood of a sample drawn from the model, Q, coming from the same distribution as the training data, P. This is equivalent to minimising the Kullback-Leibler (KL) distance, KL[Q||P]. However, if the model is intended for tasks such as retrieval or classification it is beneficial to maximise the likelihood that a sample drawn from the training data is captured by the model, equivalent to minimising KL[P||Q]. The cost function used in adversarial training optimises the Jensen-Shannon entropy which can be seen as an even interpolation between KL[Q||P] and KL[P||Q]. Here, we propose an alternative adversarial cost function which allows easy tuning of the model for either task. Our task specific cost function is evaluated on a dataset of hand-written characters in the following tasks: Generation, retrieval and one-shot learning.