 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo we really need Self-Attention for Streaming Automatic Speech Recognition?
Jan 27, 2026Transformer-based architectures are the most used architectures in many deep learning fields like Natural Language Processing, Computer Vision or Speech processing. It may encourage the direct use of Transformers in the constrained tasks, without questioning whether it will yield the same benefits as in standard tasks. Given specific constraints, it is essential to evaluate the relevance of transformer models. This work questions the suitability of transformers for specific domains. We argue that the high computational requirements and latency issues associated with these models do not align well with streaming applications. Our study promotes the search for alternative strategies to improve efficiency without sacrificing performance. In light of this observation, our paper critically examines the usefulness of transformer architecture in such constrained environments. As a first attempt, we show that the computational cost for Streaming Automatic Speech Recognition (ASR) can be reduced using deformable convolution instead of Self-Attention. Furthermore, we show that Self-Attention mechanisms can be entirely removed and not replaced, without observing significant degradation in the Word Error Rate.
Supervised and Unsupervised Alignments for Spoofing Behavioral Biometrics
Aug 14, 2024



Biometric recognition systems are security systems based on intrinsic properties of their users, usually encoded in high dimension representations called embeddings, which potential theft would represent a greater threat than a temporary password or a replaceable key. To study the threat of embedding theft, we perform spoofing attacks on two behavioral biometric systems (an automatic speaker verification system and a handwritten digit analysis system) using a set of alignment techniques. Biometric recognition systems based on embeddings work in two phases: enrollment - where embeddings are collected and stored - then authentication - when new embeddings are compared to the stored ones -.The threat of stolen enrollment embeddings has been explored by the template reconstruction attack literature: reconstructing the original data to spoof an authentication system is doable with black-box access to their encoder. In this document, we explore the options available to perform template reconstruction attacks without any access to the encoder. To perform those attacks, we suppose general rules over the distribution of embeddings across encoders and use supervised and unsupervised algorithms to align an unlabeled set of embeddings with a set from a known encoder. The use of an alignment algorithm from the unsupervised translation literature gives promising results on spoofing two behavioral biometric systems.
Automatic Voice Identification after Speech Resynthesis using PPG
Aug 05, 2024Speech resynthesis is a generic task for which we want to synthesize audio with another audio as input, which finds applications for media monitors and journalists.Among different tasks addressed by speech resynthesis, voice conversion preserves the linguistic information while modifying the identity of the speaker, and speech edition preserves the identity of the speaker but some words are modified.In both cases, we need to disentangle speaker and phonetic contents in intermediate representations.Phonetic PosteriorGrams (PPG) are a frame-level probabilistic representation of phonemes, and are usually considered speaker-independent.This paper presents a PPG-based speech resynthesis system.A perceptive evaluation assesses that it produces correct audio quality.Then, we demonstrate that an automatic speaker verification model is not able to recover the source speaker after re-synthesis with PPG, even when the model is trained on synthetic data.
ASoBO: Attentive Beamformer Selection for Distant Speaker Diarization in Meetings
Jun 05, 2024



Speaker Diarization (SD) aims at grouping speech segments that belong to the same speaker. This task is required in many speech-processing applications, such as rich meeting transcription. In this context, distant microphone arrays usually capture the audio signal. Beamforming, i.e., spatial filtering, is a common practice to process multi-microphone audio data. However, it often requires an explicit localization of the active source to steer the filter. This paper proposes a self-attention-based algorithm to select the output of a bank of fixed spatial filters. This method serves as a feature extractor for joint Voice Activity (VAD) and Overlapped Speech Detection (OSD). The speaker diarization is then inferred from the detected segments. The approach shows convincing distant VAD, OSD, and SD performance, e.g. 14.5% DER on the AISHELL-4 dataset. The analysis of the self-attention weights demonstrates their explainability, as they correlate with the speaker's angular locations.
Channel-Combination Algorithms for Robust Distant Voice Activity and Overlapped Speech Detection
Feb 13, 2024



Voice Activity Detection (VAD) and Overlapped Speech Detection (OSD) are key pre-processing tasks for speaker diarization. In the meeting context, it is often easier to capture speech with a distant device. This consideration however leads to severe performance degradation. We study a unified supervised learning framework to solve distant multi-microphone joint VAD and OSD (VAD+OSD). This paper investigates various multi-channel VAD+OSD front-ends that weight and combine incoming channels. We propose three algorithms based on the Self-Attention Channel Combinator (SACC), previously proposed in the literature. Experiments conducted on the AMI meeting corpus exhibit that channel combination approaches bring significant VAD+OSD improvements in the distant speech scenario. Specifically, we explore the use of learned complex combination weights and demonstrate the benefits of such an approach in terms of explainability. Channel combination-based VAD+OSD systems are evaluated on the final back-end task, i.e. speaker diarization, and show significant improvements. Finally, since multi-channel systems are trained given a fixed array configuration, they may fail in generalizing to other array set-ups, e.g. mismatched number of microphones. A channel-number invariant loss is proposed to learn a unique feature representation regardless of the number of available microphones. The evaluation conducted on mismatched array configurations highlights the robustness of this training strategy.
Joint speech and overlap detection: a benchmark over multiple audio setup and speech domains
Jul 24, 2023



Voice activity and overlapped speech detection (respectively VAD and OSD) are key pre-processing tasks for speaker diarization. The final segmentation performance highly relies on the robustness of these sub-tasks. Recent studies have shown VAD and OSD can be trained jointly using a multi-class classification model. However, these works are often restricted to a specific speech domain, lacking information about the generalization capacities of the systems. This paper proposes a complete and new benchmark of different VAD and OSD models, on multiple audio setups (single/multi-channel) and speech domains (e.g. media, meeting...). Our 2/3-class systems, which combine a Temporal Convolutional Network with speech representations adapted to the setup, outperform state-of-the-art results. We show that the joint training of these two tasks offers similar performances in terms of F1-score to two dedicated VAD and OSD systems while reducing the training cost. This unique architecture can also be used for single and multichannel speech processing.
Multi-microphone Automatic Speech Segmentation in Meetings Based on Circular Harmonics Features
Jun 07, 2023



Speaker diarization is the task of answering Who spoke and when? in an audio stream. Pipeline systems rely on speech segmentation to extract speakers' segments and achieve robust speaker diarization. This paper proposes a common framework to solve three segmentation tasks in the distant speech scenario: Voice Activity Detection (VAD), Overlapped Speech Detection (OSD), and Speaker Change Detection (SCD). In the literature, a few studies investigate the multi-microphone distant speech scenario. In this work, we propose a new set of spatial features based on direction-of-arrival estimations in the circular harmonic domain (CH-DOA). These spatial features are extracted from multi-microphone audio data and combined with standard acoustic features. Experiments on the AMI meeting corpus show that CH-DOA can improve the segmentation while being robust in the case of deactivated microphones.
Evaluation of Speaker Anonymization on Emotional Speech
Apr 15, 2023Speech data carries a range of personal information, such as the speaker's identity and emotional state. These attributes can be used for malicious purposes. With the development of virtual assistants, a new generation of privacy threats has emerged. Current studies have addressed the topic of preserving speech privacy. One of them, the VoicePrivacy initiative aims to promote the development of privacy preservation tools for speech technology. The task selected for the VoicePrivacy 2020 Challenge (VPC) is about speaker anonymization. The goal is to hide the source speaker's identity while preserving the linguistic information. The baseline of the VPC makes use of a voice conversion. This paper studies the impact of the speaker anonymization baseline system of the VPC on emotional information present in speech utterances. Evaluation is performed following the VPC rules regarding the attackers' knowledge about the anonymization system. Our results show that the VPC baseline system does not suppress speakers' emotions against informed attackers. When comparing anonymized speech to original speech, the emotion recognition performance is degraded by 15\% relative to IEMOCAP data, similar to the degradation observed for automatic speech recognition used to evaluate the preservation of the linguistic information.
Are disentangled representations all you need to build speaker anonymization systems?
Aug 24, 2022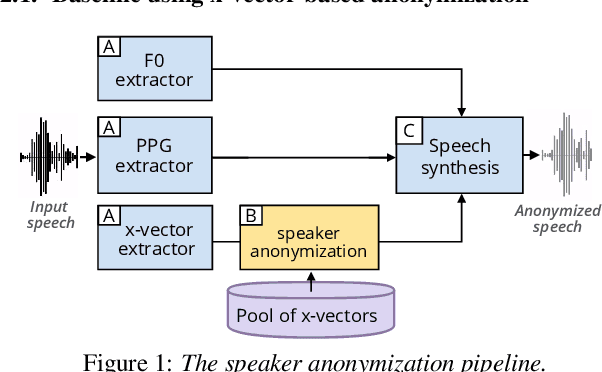
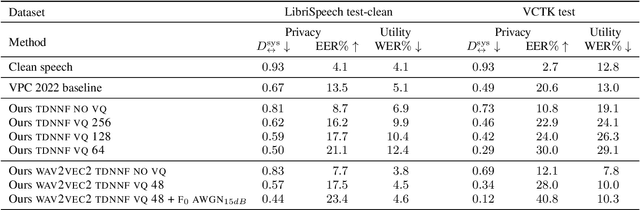
Speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns when speech data get collected. Speaker anonymization aims to transform a speech signal to remove the source speaker's identity while leaving the spoken content unchanged. Current methods perform the transformation by relying on content/speaker disentanglement and voice conversion. Usually, an acoustic model from an automatic speech recognition system extracts the content representation while an x-vector system extracts the speaker representation. Prior work has shown that the extracted features are not perfectly disentangled. This paper tackles how to improve features disentanglement, and thus the converted anonymized speech. We propose enhancing the disentanglement by removing speaker information from the acoustic model using vector quantization. Evaluation done using the VoicePrivacy 2022 toolkit showed that vector quantization helps conceal the original speaker identity while maintaining utility for speech recognition.
Privacy-Preserving Speech Representation Learning using Vector Quantization
Mar 15, 2022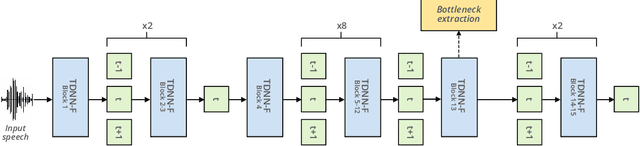

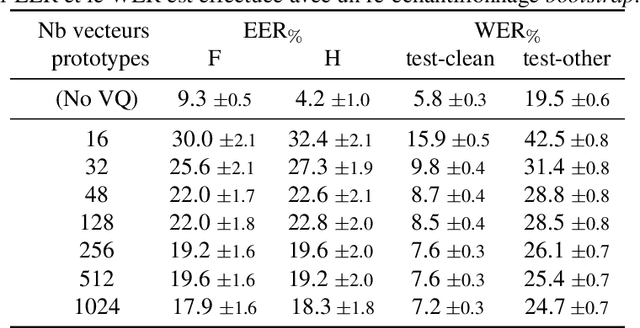
With the popularity of virtual assistants (e.g., Siri, Alexa), the use of speech recognition is now becoming more and more widespread.However, speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns.The presented experiments show that the representations extracted by the deep layers of speech recognition networks contain speaker information.This paper aims to produce an anonymous representation while preserving speech recognition performance.To this end, we propose to use vector quantization to constrain the representation space and induce the network to suppress the speaker identity.The choice of the quantization dictionary size allows to configure the trade-off between utility (speech recognition) and privacy (speaker identity concealment).