 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Reservoir: A Diagonalization-Based Optimization
Feb 23, 2026We introduce a diagonalization-based optimization for Linear Echo State Networks (ESNs) that reduces the per-step computational complexity of reservoir state updates from O(N^2) to O(N). By reformulating reservoir dynamics in the eigenbasis of the recurrent matrix, the recurrent update becomes a set of independent element-wise operations, eliminating the matrix multiplication. We further propose three methods to use our optimization depending on the situation: (i) Eigenbasis Weight Transformation (EWT), which preserves the dynamics of standard and trained Linear ESNs, (ii) End-to-End Eigenbasis Training (EET), which directly optimizes readout weights in the transformed space and (iii) Direct Parameter Generation (DPG), that bypasses matrix diagonalization by directly sampling eigenvalues and eigenvectors, achieving comparable performance than standard Linear ESNs. Across all experiments, both our methods preserve predictive accuracy while offering significant computational speedups, making them a replacement of standard Linear ESNs computations and training, and suggesting a shift of paradigm in linear ESN towards the direct selection of eigenvalues.
Transfer between long-term and short-term memory using Conceptors
Mar 11, 2020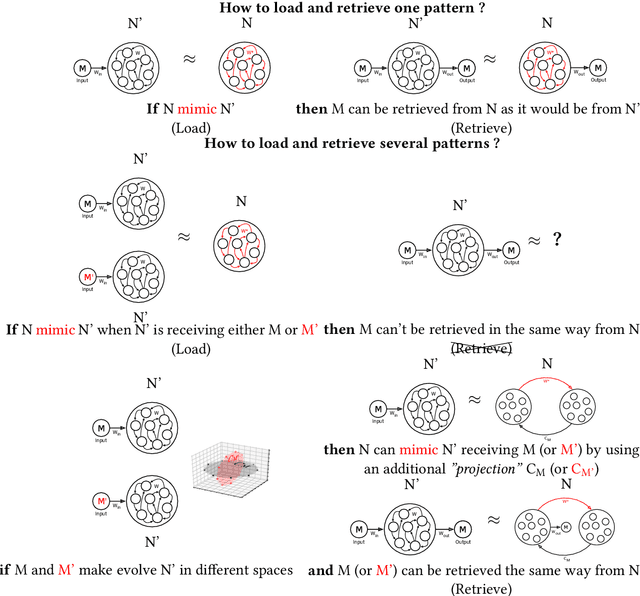

We introduce a recurrent neural network model of working memory combining short-term and long-term components. e short-term component is modelled using a gated reservoir model that is trained to hold a value from an input stream when a gate signal is on. e long-term component is modelled using conceptors in order to store inner temporal patterns (that corresponds to values). We combine these two components to obtain a model where information can go from long-term memory to short-term memory and vice-versa and we show how standard operations on conceptors allow to combine long-term memories and describe their effect on short-term memory.
A Simple Reservoir Model of Working Memory with Real Values
Jun 18, 2018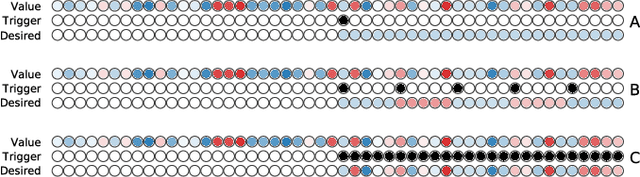
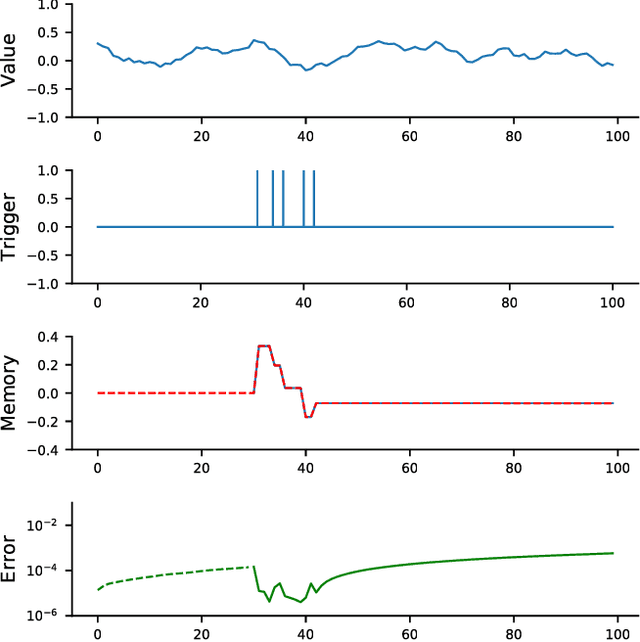
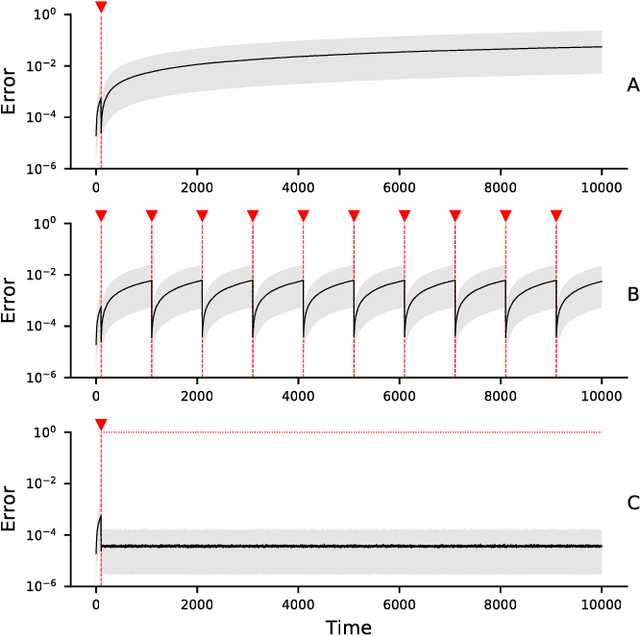
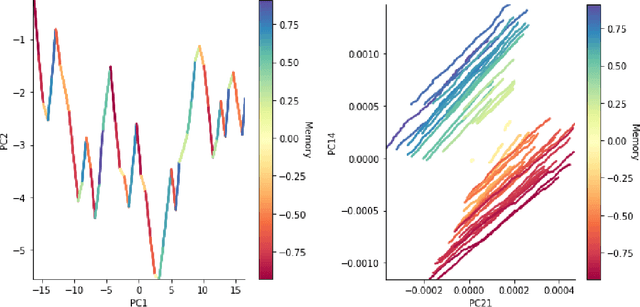
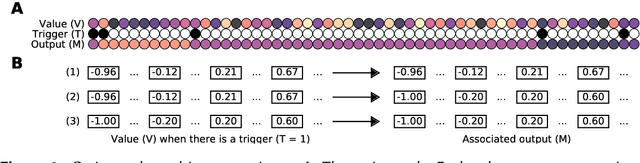
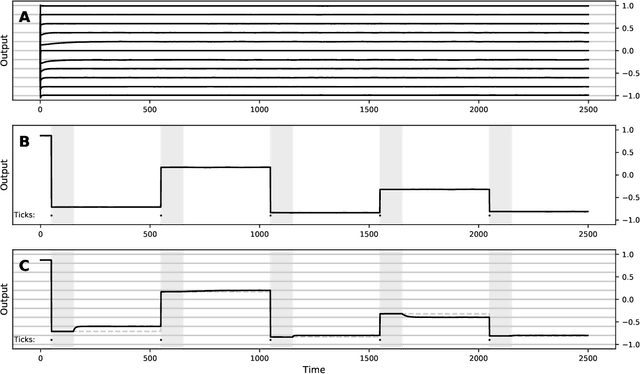
The prefrontal cortex is known to be involved in many high-level cognitive functions, in particular, working memory. Here, we study to what extent a group of randomly connected units (namely an Echo State Network, ESN) can store and maintain (as output) an arbitrary real value from a streamed input, i.e. can act as a sustained working memory unit. Furthermore, we explore to what extent such an architecture can take advantage of the stored value in order to produce non-linear computations. Comparison between different architectures (with and without feedback, with and without a working memory unit) shows that an explicit memory improves the performances.