 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalking the Weight Manifold: a Topological Approach to Conditioning Inspired by Neuromodulation
May 29, 2025



One frequently wishes to learn a range of similar tasks as efficiently as possible, re-using knowledge across tasks. In artificial neural networks, this is typically accomplished by conditioning a network upon task context by injecting context as input. Brains have a different strategy: the parameters themselves are modulated as a function of various neuromodulators such as serotonin. Here, we take inspiration from neuromodulation and propose to learn weights which are smoothly parameterized functions of task context variables. Rather than optimize a weight vector, i.e. a single point in weight space, we optimize a smooth manifold in weight space with a predefined topology. To accomplish this, we derive a formal treatment of optimization of manifolds as the minimization of a loss functional subject to a constraint on volumetric movement, analogous to gradient descent. During inference, conditioning selects a single point on this manifold which serves as the effective weight matrix for a particular sub-task. This strategy for conditioning has two main advantages. First, the topology of the manifold (whether a line, circle, or torus) is a convenient lever for inductive biases about the relationship between tasks. Second, learning in one state smoothly affects the entire manifold, encouraging generalization across states. To verify this, we train manifolds with several topologies, including straight lines in weight space (for conditioning on e.g. noise level in input data) and ellipses (for rotated images). Despite their simplicity, these parameterizations outperform conditioning identical networks by input concatenation and better generalize to out-of-distribution samples. These results suggest that modulating weights over low-dimensional manifolds offers a principled and effective alternative to traditional conditioning.
Token-Level Uncertainty-Aware Objective for Language Model Post-Training
Mar 15, 2025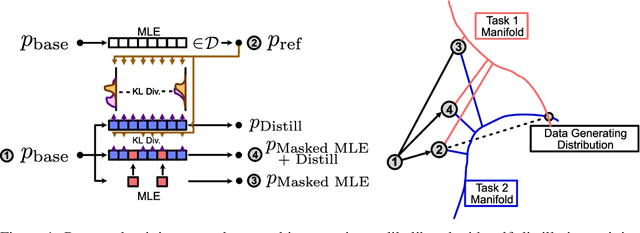
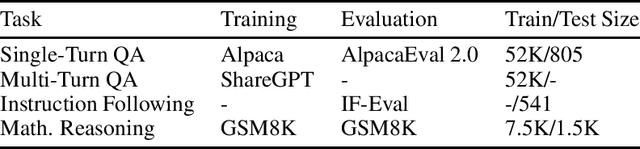
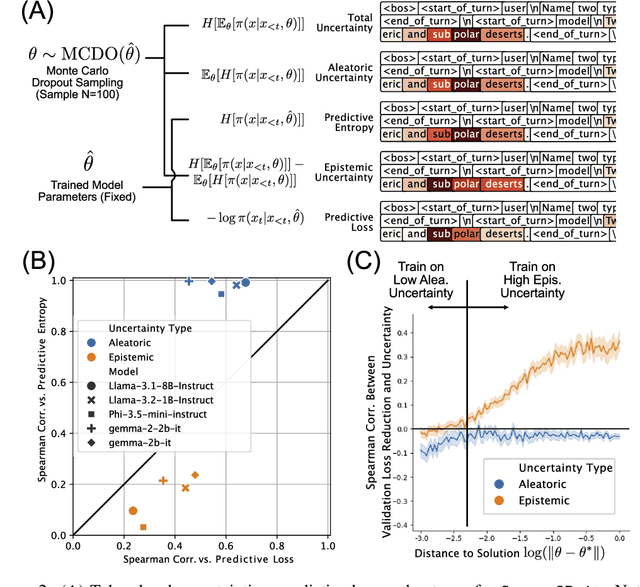
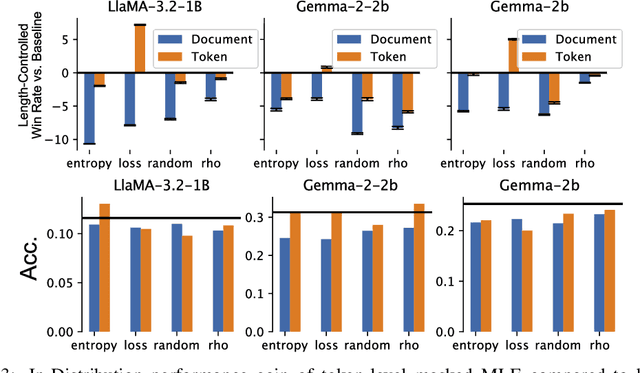
In the current work, we connect token-level uncertainty in causal language modeling to two types of training objectives: 1) masked maximum likelihood (MLE), 2) self-distillation. We show that masked MLE is effective in reducing epistemic uncertainty, and serve as an effective token-level automatic curriculum learning technique. However, masked MLE is prone to overfitting and requires self-distillation regularization to improve or maintain performance on out-of-distribution tasks. We demonstrate significant performance gain via the proposed training objective - combined masked MLE and self-distillation - across multiple architectures (Gemma, LLaMA, Phi) and datasets (Alpaca, ShareGPT, GSM8K), mitigating overfitting while maintaining adaptability during post-training. Our findings suggest that uncertainty-aware training provides an effective mechanism for enhancing language model training.
Neural Circuit Architectural Priors for Embodied Control
Jan 13, 2022



Artificial neural networks for simulated motor control and robotics often adopt generic architectures like fully connected MLPs. While general, these tabula rasa architectures rely on large amounts of experience to learn, are not easily transferable to new bodies, and have internal dynamics that are difficult to interpret. In nature, animals are born with highly structured connectivity in their nervous systems shaped by evolution; this innate circuitry acts synergistically with learning mechanisms to provide inductive biases that enable most animals to function well soon after birth and improve abilities efficiently. Convolutional networks inspired by visual circuitry have encoded useful biases for vision. However, it is unknown the extent to which ANN architectures inspired by neural circuitry can yield useful biases for other domains. In this work, we ask what advantages biologically inspired network architecture can provide in the context of motor control. Specifically, we translate C. elegans circuits for locomotion into an ANN model controlling a simulated Swimmer agent. On a locomotion task, our architecture achieves good initial performance and asymptotic performance comparable with MLPs, while dramatically improving data efficiency and requiring orders of magnitude fewer parameters. Our architecture is more interpretable and transfers to new body designs. An ablation analysis shows that principled excitation/inhibition is crucial for learning, while weight initialization contributes to good initial performance. Our work demonstrates several advantages of ANN architectures inspired by systems neuroscience and suggests a path towards modeling more complex behavior.