 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Early and Red Team Often: A Framework for Assessing and Managing Dual-Use Hazards of AI Foundation Models
May 15, 2024



A concern about cutting-edge or "frontier" AI foundation models is that an adversary may use the models for preparing chemical, biological, radiological, nuclear, (CBRN), cyber, or other attacks. At least two methods can identify foundation models with potential dual-use capability; each has advantages and disadvantages: A. Open benchmarks (based on openly available questions and answers), which are low-cost but accuracy-limited by the need to omit security-sensitive details; and B. Closed red team evaluations (based on private evaluation by CBRN and cyber experts), which are higher-cost but can achieve higher accuracy by incorporating sensitive details. We propose a research and risk-management approach using a combination of methods including both open benchmarks and closed red team evaluations, in a way that leverages advantages of both methods. We recommend that one or more groups of researchers with sufficient resources and access to a range of near-frontier and frontier foundation models run a set of foundation models through dual-use capability evaluation benchmarks and red team evaluations, then analyze the resulting sets of models' scores on benchmark and red team evaluations to see how correlated those are. If, as we expect, there is substantial correlation between the dual-use potential benchmark scores and the red team evaluation scores, then implications include the following: The open benchmarks should be used frequently during foundation model development as a quick, low-cost measure of a model's dual-use potential; and if a particular model gets a high score on the dual-use potential benchmark, then more in-depth red team assessments of that model's dual-use capability should be performed. We also discuss limitations and mitigations for our approach, e.g., if model developers try to game benchmarks by including a version of benchmark test data in a model's training data.
Actionable Guidance for High-Consequence AI Risk Management: Towards Standards Addressing AI Catastrophic Risks
Jun 17, 2022Artificial intelligence (AI) systems can provide many beneficial capabilities but also risks of adverse events. Some AI systems could present risks of events with very high or catastrophic consequences at societal scale. The US National Institute of Standards and Technology (NIST) is developing the NIST Artificial Intelligence Risk Management Framework (AI RMF) as voluntary guidance on AI risk assessment and management for AI developers and others. For addressing risks of events with catastrophic consequences, NIST indicated a need to translate from high level principles to actionable risk management guidance. In this document, we provide detailed actionable-guidance recommendations focused on identifying and managing risks of events with very high or catastrophic consequences, intended as a risk management practices resource for NIST for AI RMF version 1.0 (scheduled for release in early 2023), or for AI RMF users, or for other AI risk management guidance and standards as appropriate. We also provide our methodology for our recommendations. We provide actionable-guidance recommendations for AI RMF 1.0 on: identifying risks from potential unintended uses and misuses of AI systems; including catastrophic-risk factors within the scope of risk assessments and impact assessments; identifying and mitigating human rights harms; and reporting information on AI risk factors including catastrophic-risk factors. In addition, we provide recommendations on additional issues for a roadmap for later versions of the AI RMF or supplementary publications. These include: providing an AI RMF Profile with supplementary guidance for cutting-edge increasingly multi-purpose or general-purpose AI. We aim for this work to be a concrete risk-management practices contribution, and to stimulate constructive dialogue on how to address catastrophic risks and associated issues in AI standards.
A Model of Pathways to Artificial Superintelligence Catastrophe for Risk and Decision Analysis
Jul 25, 2016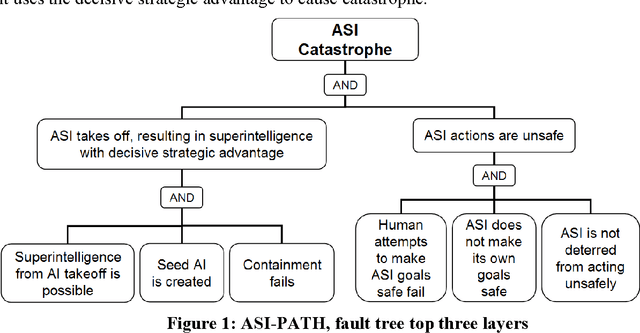
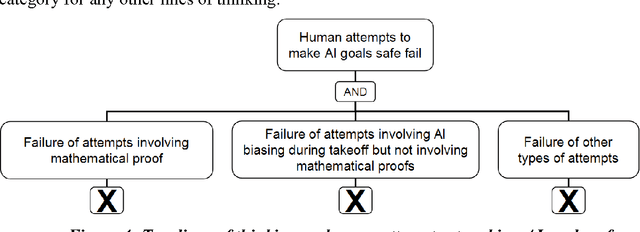
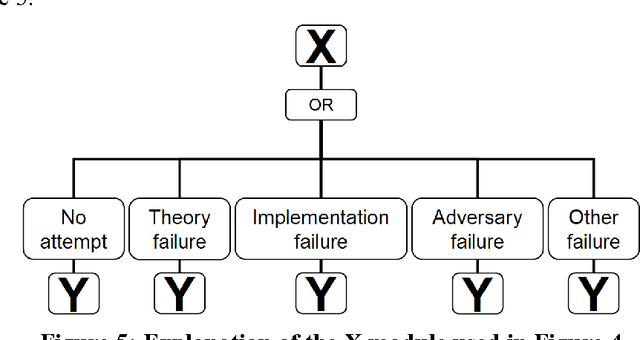
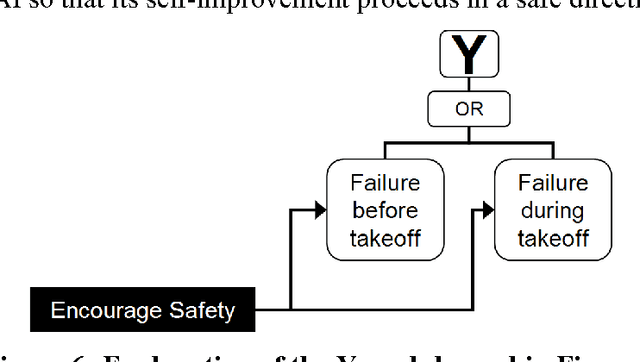
An artificial superintelligence (ASI) is artificial intelligence that is significantly more intelligent than humans in all respects. While ASI does not currently exist, some scholars propose that it could be created sometime in the future, and furthermore that its creation could cause a severe global catastrophe, possibly even resulting in human extinction. Given the high stakes, it is important to analyze ASI risk and factor the risk into decisions related to ASI research and development. This paper presents a graphical model of major pathways to ASI catastrophe, focusing on ASI created via recursive self-improvement. The model uses the established risk and decision analysis modeling paradigms of fault trees and influence diagrams in order to depict combinations of events and conditions that could lead to AI catastrophe, as well as intervention options that could decrease risks. The events and conditions include select aspects of the ASI itself as well as the human process of ASI research, development, and management. Model structure is derived from published literature on ASI risk. The model offers a foundation for rigorous quantitative evaluation and decision making on the long-term risk of ASI catastrophe.