 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction and Trustworthy AI
Aug 09, 2025Conformal predictors are machine learning algorithms developed in the 1990's by Gammerman, Vovk, and their research team, to provide set predictions with guaranteed confidence level. Over recent years, they have grown in popularity and have become a mainstream methodology for uncertainty quantification in the machine learning community. From its beginning, there was an understanding that they enable reliable machine learning with well-calibrated uncertainty quantification. This makes them extremely beneficial for developing trustworthy AI, a topic that has also risen in interest over the past few years, in both the AI community and society more widely. In this article, we review the potential for conformal prediction to contribute to trustworthy AI beyond its marginal validity property, addressing problems such as generalization risk and AI governance. Experiments and examples are also provided to demonstrate its use as a well-calibrated predictor and for bias identification and mitigation.
Investigating Data Usage for Inductive Conformal Predictors
Jun 18, 2024



Inductive conformal predictors (ICPs) are algorithms that are able to generate prediction sets, instead of point predictions, which are valid at a user-defined confidence level, only assuming exchangeability. These algorithms are useful for reliable machine learning and are increasing in popularity. The ICP development process involves dividing development data into three parts: training, calibration and test. With access to limited or expensive development data, it is an open question regarding the most efficient way to divide the data. This study provides several experiments to explore this question and consider the case for allowing overlap of examples between training and calibration sets. Conclusions are drawn that will be of value to academics and practitioners planning to use ICPs.
Reliable Prediction Intervals with Directly Optimized Inductive Conformal Regression for Deep Learning
Feb 02, 2023By generating prediction intervals (PIs) to quantify the uncertainty of each prediction in deep learning regression, the risk of wrong predictions can be effectively controlled. High-quality PIs need to be as narrow as possible, whilst covering a preset proportion of real labels. At present, many approaches to improve the quality of PIs can effectively reduce the width of PIs, but they do not ensure that enough real labels are captured. Inductive Conformal Predictor (ICP) is an algorithm that can generate effective PIs which is theoretically guaranteed to cover a preset proportion of data. However, typically ICP is not directly optimized to yield minimal PI width. However, in this study, we use Directly Optimized Inductive Conformal Regression (DOICR) that takes only the average width of PIs as the loss function and increases the quality of PIs through an optimized scheme under the validity condition that sufficient real labels are captured in the PIs. Benchmark experiments show that DOICR outperforms current state-of-the-art algorithms for regression problems using underlying Deep Neural Network structures for both tabular and image data.
Optimized conformal classification using gradient descent approximation
May 24, 2021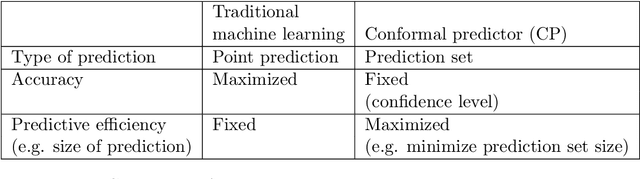
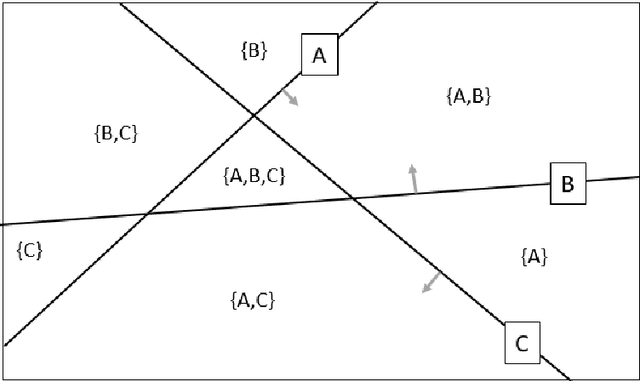
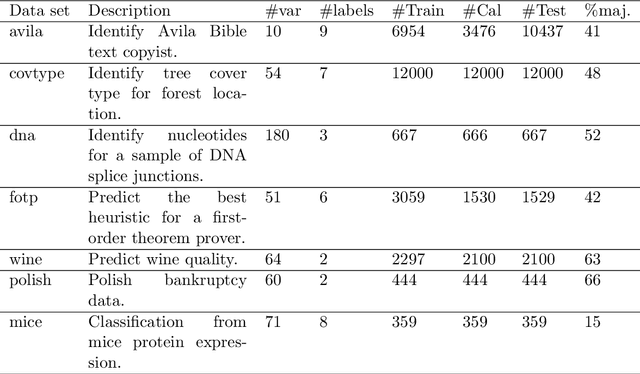
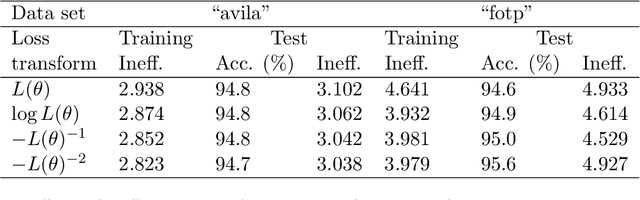
Conformal predictors are an important class of algorithms that allow predictions to be made with a user-defined confidence level. They are able to do this by outputting prediction sets, rather than simple point predictions. The conformal predictor is valid in the sense that the accuracy of its predictions is guaranteed to meet the confidence level, only assuming exchangeability in the data. Since accuracy is guaranteed, the performance of a conformal predictor is measured through the efficiency of the prediction sets. Typically, a conformal predictor is built on an underlying machine learning algorithm and hence its predictive power is inherited from this algorithm. However, since the underlying machine learning algorithm is not trained with the objective of minimizing predictive efficiency it means that the resulting conformal predictor may be sub-optimal and not aligned sufficiently to this objective. Hence, in this study we consider an approach to train the conformal predictor directly with maximum predictive efficiency as the optimization objective, and we focus specifically on the inductive conformal predictor for classification. To do this, the conformal predictor is approximated by a differentiable objective function and gradient descent used to optimize it. The resulting parameter estimates are then passed to a proper inductive conformal predictor to give valid prediction sets. We test the method on several real world data sets and find that the method is promising and in most cases gives improved predictive efficiency against a baseline conformal predictor.
Approximation to Object Conditional Validity with Inductive Conformal Predictors
Mar 02, 2021
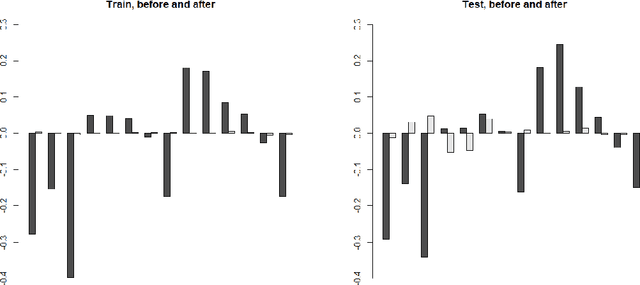

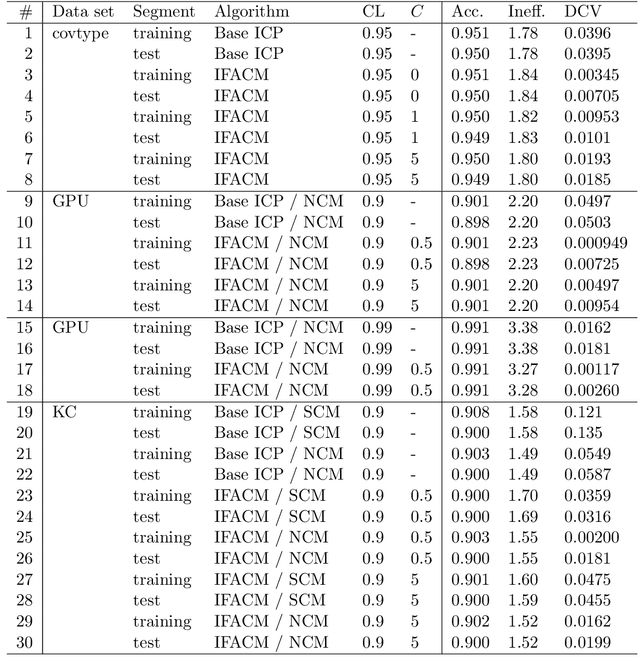
Conformal predictors are machine learning algorithms that output prediction sets that have a guarantee of marginal validity for finite samples with minimal distributional assumptions. This is a property that makes conformal predictors useful for machine learning tasks where we require reliable predictions. It would also be desirable to achieve conditional validity in the same setting, in the sense that validity of the prediction intervals remains valid regardless of conditioning on any particular property of the object of the prediction. Unfortunately, it has been shown that such conditional validity is impossible to guarantee for non-trivial prediction problems for finite samples. In this article, instead of trying to achieve a strong conditional validity result, the weaker goal of achieving an approximation to conditional validity is considered. A new algorithm is introduced to do this by iteratively adjusting a conformity measure to deviations from object conditional validity measured in the training data. Along with some theoretical results, experimental results are provided for three data sets that demonstrate (1) in real world machine learning tasks, lack of conditional validity is a measurable problem and (2) that the proposed algorithm is effective at alleviating this problem.