 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Document Processing -- Methods and Tools in the real world
Dec 28, 2021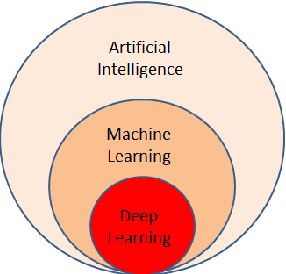
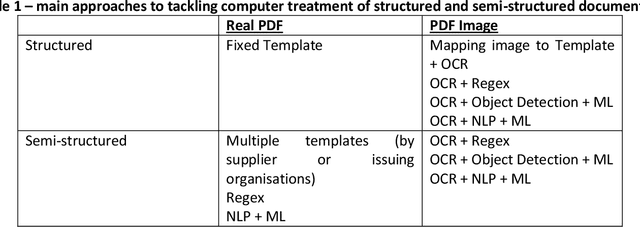
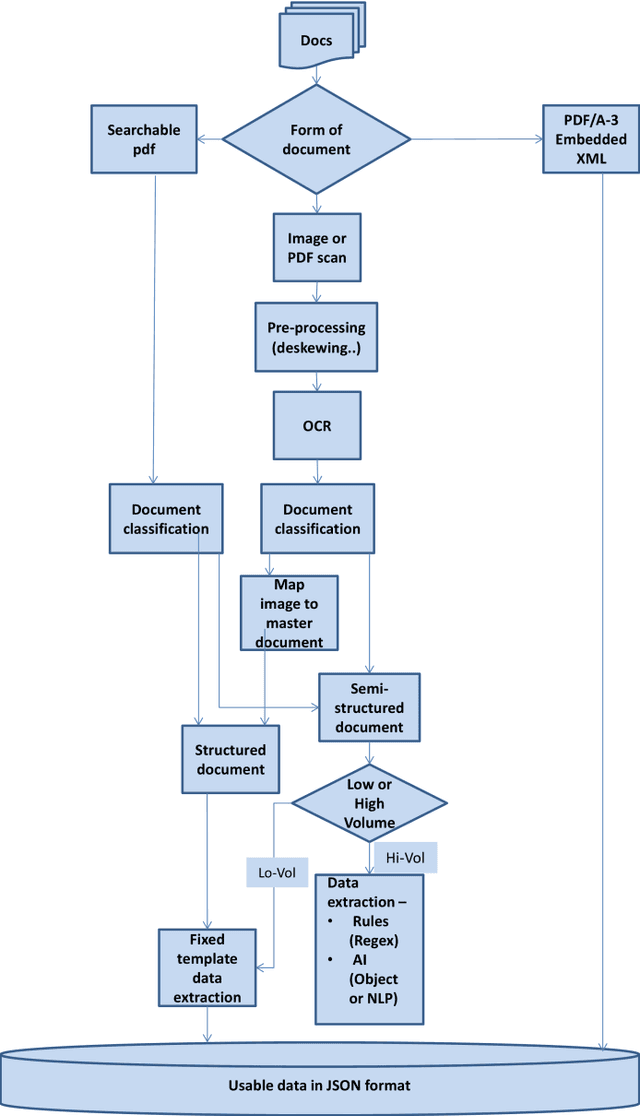

The originality of this publication is to look at the subject of IDP (Intelligent Document Processing) from the perspective of an end-user and industrialist and not that of a Computer Science researcher. This domain is one part of the challenge of information digitalisation that constitutes the Industrial Revolution of the twenty first century (Industry 4.0) and this paper looks specifically at the difficult areas of classifying, extracting information and subsequent integration into business processes with respect to forms and invoices. Since the focus is on practical implementation a brief review is carried out of the market in commercial tools for OCR, document classification and data extraction in so far as this is publicly available together with pricing (if known). Brief definitions of the main terms encountered in Computer Science publications and commercial prospectuses are provided in order to de-mystify the language for the layman. A small number of practical tests are carried out on a few real documents in order to illustrate the capabilities of tools that are commonly available at a reasonable price. The unsolved (so far) issue of tables contained in invoices is raised. The case of a typical large industrial company is evoked where the requirement is to extract 100 per cent of the information with 100 per cent reliability in order to integrate into the back-end Enterprise Resource Planning system. Finally a brief description is given of the state-of-the-art research by the huge corporations who are pushing the boundaries of deep learning techniques further and further with massive computing and financial power - progress that will undoubtedly trickle down into the real world at some later date. The paper finishes by asking the question whether the objectives and timing of the commercial world and the progress of Computer Science are fully aligned.
Automatic extraction of requirements expressed in industrial standards : a way towards machine readable standards ?
Dec 24, 2021

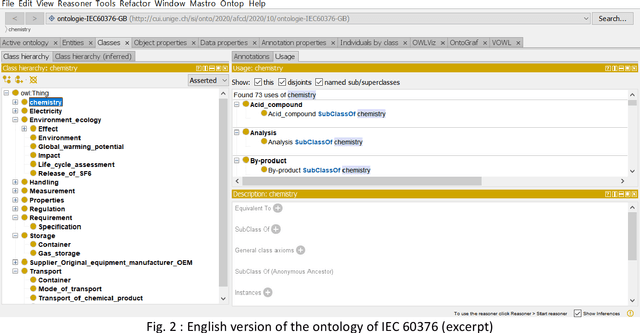
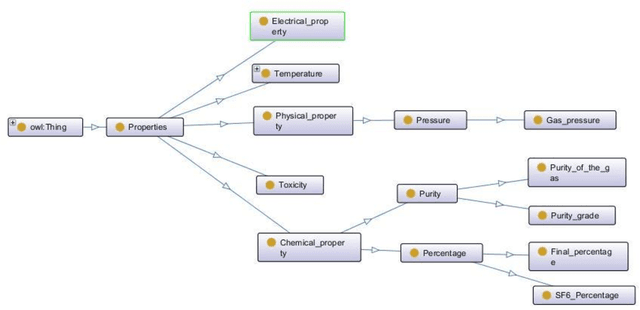
The project, under industrial funding, presented in this publication aims at the semantic analysis of a normative document describing requirements applicable to electrical appliances. The objective of the project is to build a semantic approach to extract and automatically process information related to the requirements contained in the standard. To this end, the project has been divided into three parts, covering the analysis of the requirements document, the extraction of relevant information and creation of the ontology and the comparison with other approaches. The first part of our work deals with the analysis of the requirements document under study. The study focuses on the specificity of the sentence structure, the use of particular words and vocabulary related to the representation of the requirements. The aim is to propose a representation facilitating the extraction of information, used in the second part of the study. In the second part, the extraction of relevant information is conducted in two ways: manual (the ontology being built by hand), semi-automatic (using semantic annotation software and natural language processing techniques). Whatever the method used, the aim of this extraction is to create the concept dictionary, then the ontology, enriched as the document is scanned and understood by the system. Once the relevant terms have been identified, the work focuses on identifying and representing the requirements, separating the textual writing from the information given in the tables. The automatic processing of requirements involves the extraction of sentences containing terms identified as relevant to a requirement. The identified requirement is then indexed and stored in a representation that can be used for query processing.