 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM2KB: Constructing Knowledge Bases using instruction tuned context aware Large Language Models
Aug 25, 2023The advent of Large Language Models (LLM) has revolutionized the field of natural language processing, enabling significant progress in various applications. One key area of interest is the construction of Knowledge Bases (KB) using these powerful models. Knowledge bases serve as repositories of structured information, facilitating information retrieval and inference tasks. Our paper proposes LLM2KB, a system for constructing knowledge bases using large language models, with a focus on the Llama 2 architecture and the Wikipedia dataset. We perform parameter efficient instruction tuning for Llama-2-13b-chat and StableBeluga-13B by training small injection models that have only 0.05 % of the parameters of the base models using the Low Rank Adaptation (LoRA) technique. These injection models have been trained with prompts that are engineered to utilize Wikipedia page contexts of subject entities fetched using a Dense Passage Retrieval (DPR) algorithm, to answer relevant object entities for a given subject entity and relation. Our best performing model achieved an average F1 score of 0.6185 across 21 relations in the LM-KBC challenge held at the ISWC 2023 conference.
Few-shot learning approaches for classifying low resource domain specific software requirements
Feb 14, 2023


With the advent of strong pre-trained natural language processing models like BERT, DeBERTa, MiniLM, T5, the data requirement for industries to fine-tune these models to their niche use cases has drastically reduced (typically to a few hundred annotated samples for achieving a reasonable performance). However, the availability of even a few hundred annotated samples may not always be guaranteed in low resource domains like automotive, which often limits the usage of such deep learning models in an industrial setting. In this paper we aim to address the challenge of fine-tuning such pre-trained models with only a few annotated samples, also known as Few-shot learning. Our experiments focus on evaluating the performance of a diverse set of algorithms and methodologies to achieve the task of classifying BOSCH automotive domain textual software requirements into 3 categories, while utilizing only 15 annotated samples per category for fine-tuning. We find that while SciBERT and DeBERTa based models tend to be the most accurate at 15 training samples, their performance improvement scales minimally as the number of annotated samples is increased to 50 in comparison to Siamese and T5 based models.
Wiki to Automotive: Understanding the Distribution Shift and its impact on Named Entity Recognition
Dec 01, 2021
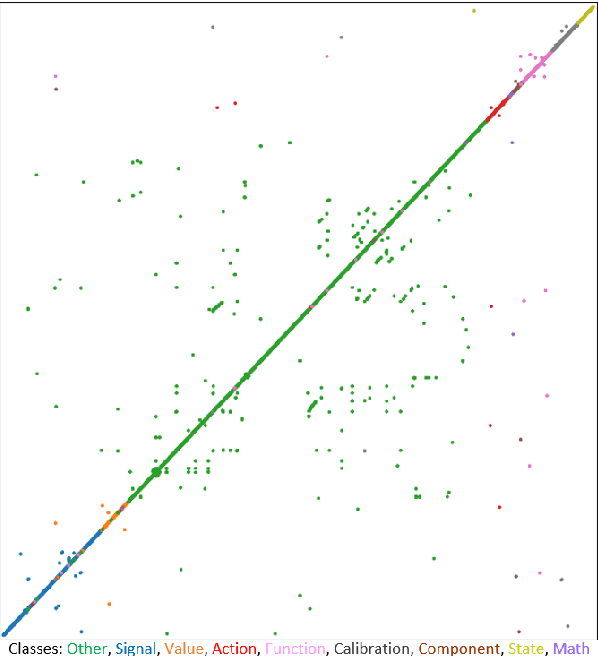
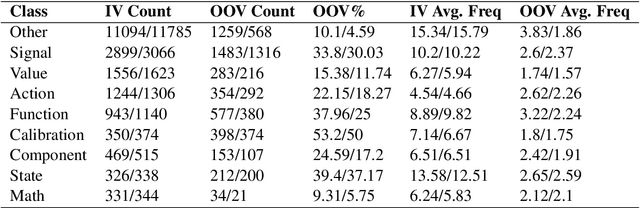

While transfer learning has become a ubiquitous technique used across Natural Language Processing (NLP) tasks, it is often unable to replicate the performance of pre-trained models on text of niche domains like Automotive. In this paper we aim to understand the main characteristics of the distribution shift with automotive domain text (describing technical functionalities such as Cruise Control) and attempt to explain the potential reasons for the gap in performance. We focus on performing the Named Entity Recognition (NER) task as it requires strong lexical, syntactic and semantic understanding by the model. Our experiments with 2 different encoders, namely BERT-Base-Uncased and SciBERT-Base-Scivocab-Uncased have lead to interesting findings that showed: 1) The performance of SciBERT is better than BERT when used for automotive domain, 2) Fine-tuning the language models with automotive domain text did not make significant improvements to the NER performance, 3) The distribution shift is challenging as it is characterized by lack of repeating contexts, sparseness of entities, large number of Out-Of-Vocabulary (OOV) words and class overlap due to domain specific nuances.
Using Integrated Gradients to explain Linguistic Acceptability learnt by BERT
Jun 01, 2021
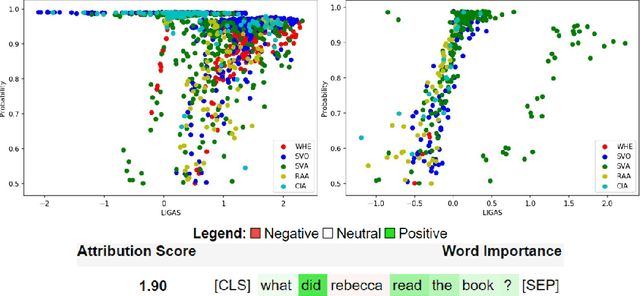
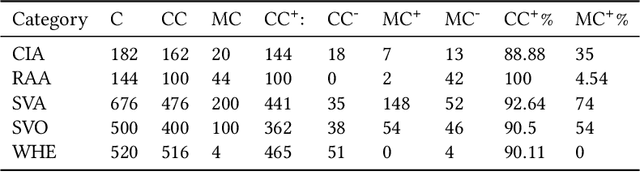
BERT has been a breakthrough in language understanding by leveraging the multi-head self-attention mechanism in its architecture. To the best of our knowledge this work is the first to leverage Layer Integrated Gradients Attribution Scores (LIGAS) to explain the Linguistic Acceptability criteria that are learnt by BERT on the Corpus of Linguistic Acceptability (CoLA) benchmark dataset. Our experiments on 5 different categories of sentences lead to the following interesting findings: 1) LIGAS for Linguistically Acceptable (LA) sentences are significantly smaller in comparison to Linguistically Unacceptable (LUA) sentences, 2) There are specific subtrees of the Constituency Parse Tree (CPT) for LA and LUA sentences which contribute larger LIGAS, 3) Across the different categories of sentences we observed around 88% to 100% of the Correctly classified sentences had positive LIGAS, indicating a strong positive relationship to the prediction confidence of the model, and 4) Around 57% of the Misclassified sentences had positive LIGAS, which we believe can become correctly classified sentences if the LIGAS are parameterized in the loss function of the model.