 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Attribution to Decode Dataset Bias in Neural Network Models for Chemistry
Nov 29, 2018
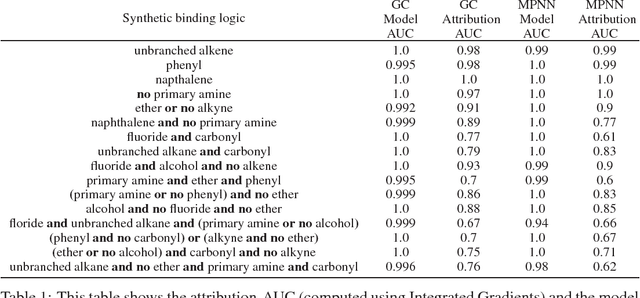
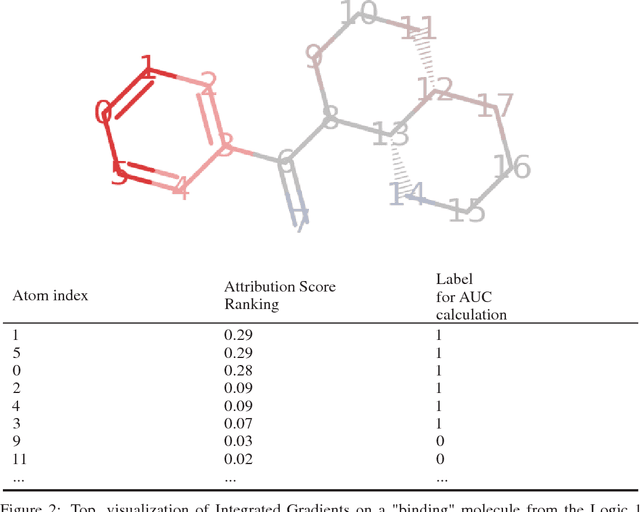
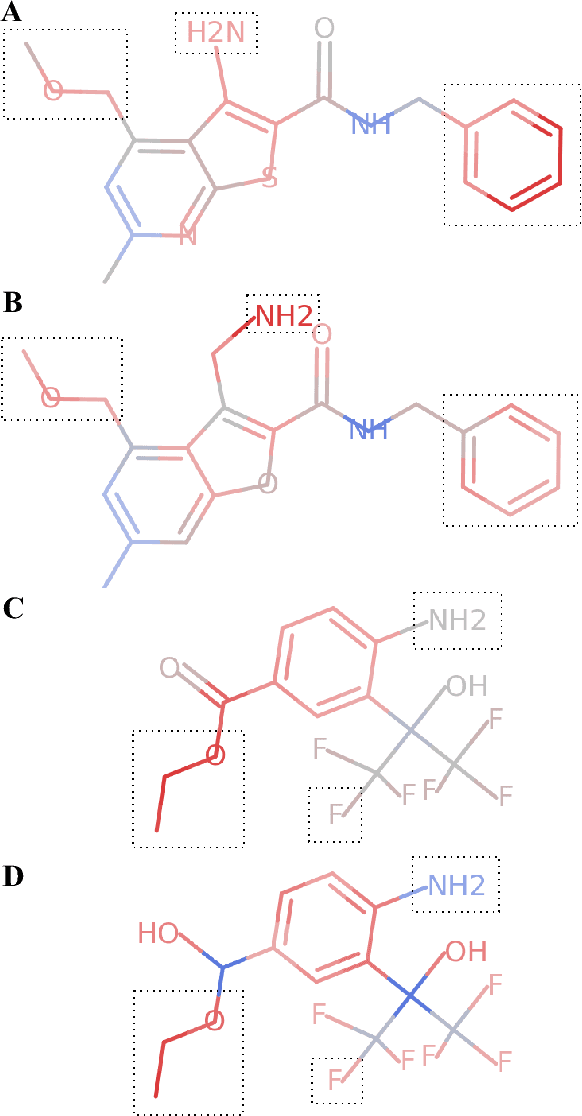
Deep neural networks have achieved state of the art accuracy at classifying molecules with respect to whether they bind to specific protein targets. A key breakthrough would occur if these models could reveal the fragment pharmacophores that are causally involved in binding. Extracting chemical details of binding from the networks could potentially lead to scientific discoveries about the mechanisms of drug actions. But doing so requires shining light into the black box that is the trained neural network model, a task that has proved difficult across many domains. Here we show how the binding mechanism learned by deep neural network models can be interrogated, using a recently described attribution method. We first work with carefully constructed synthetic datasets, in which the 'fragment logic' of binding is fully known. We find that networks that achieve perfect accuracy on held out test datasets still learn spurious correlations due to biases in the datasets, and we are able to exploit this non-robustness to construct adversarial examples that fool the model. The dataset bias makes these models unreliable for accurately revealing information about the mechanisms of protein-ligand binding. In light of our findings, we prescribe a test that checks for dataset bias given a hypothesis. If the test fails, it indicates that either the model must be simplified or regularized and/or that the training dataset requires augmentation.
Counterfactual Fairness in Text Classification through Robustness
Sep 27, 2018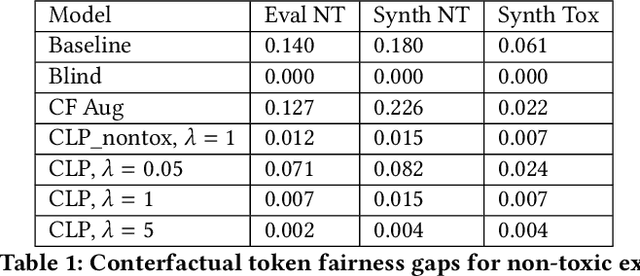
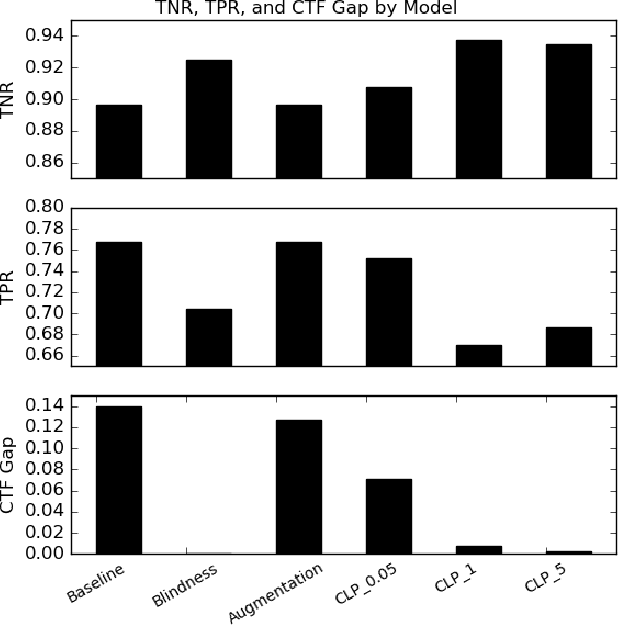
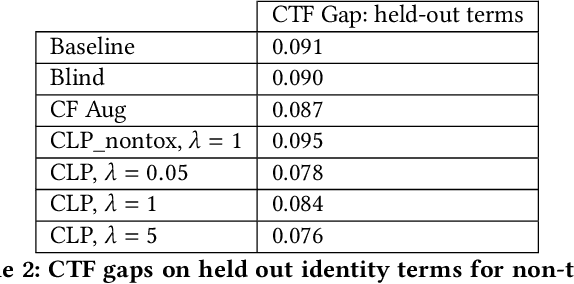
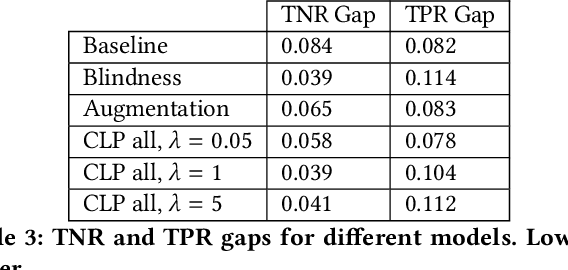
In this paper, we study counterfactual fairness in text classification, which asks the question: How would the prediction change if the sensitive attribute discussed in the example were something else? We offer a heuristic for measuring this particular form of fairness in text classifiers by substituting individual tokens pertaining to attributes (e.g. sexual orientation, race, and religion), and describe the relationship with other notions, including individual and group fairness. Further, we offer methods, including hard ablation, blindness, and counterfactual logit pairing, for optimizing this counterfactual fairness metric during model training, bridging the robustness literature and the fairness literature. Empirically, counterfactual logit pairing performs as well as hard ablation and blindness to sensitive tokens, but generalizes better to unseen tokens. Interestingly, we find that in practice, the methods do not significantly harm classifier performance, and have varying tradeoffs with group fairness. These approaches, both for measurement and optimization, provide a new path forward for addressing counterfactual fairness issues.
A Note about: Local Explanation Methods for Deep Neural Networks lack Sensitivity to Parameter Values
Jun 11, 2018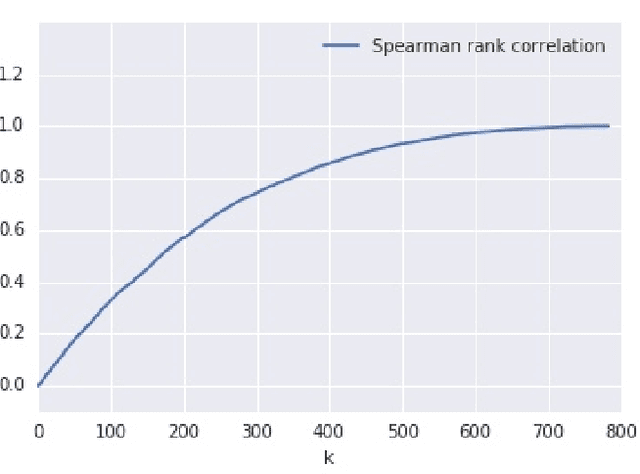
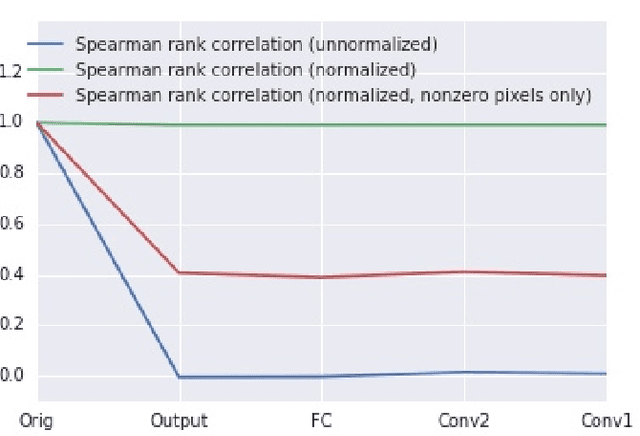
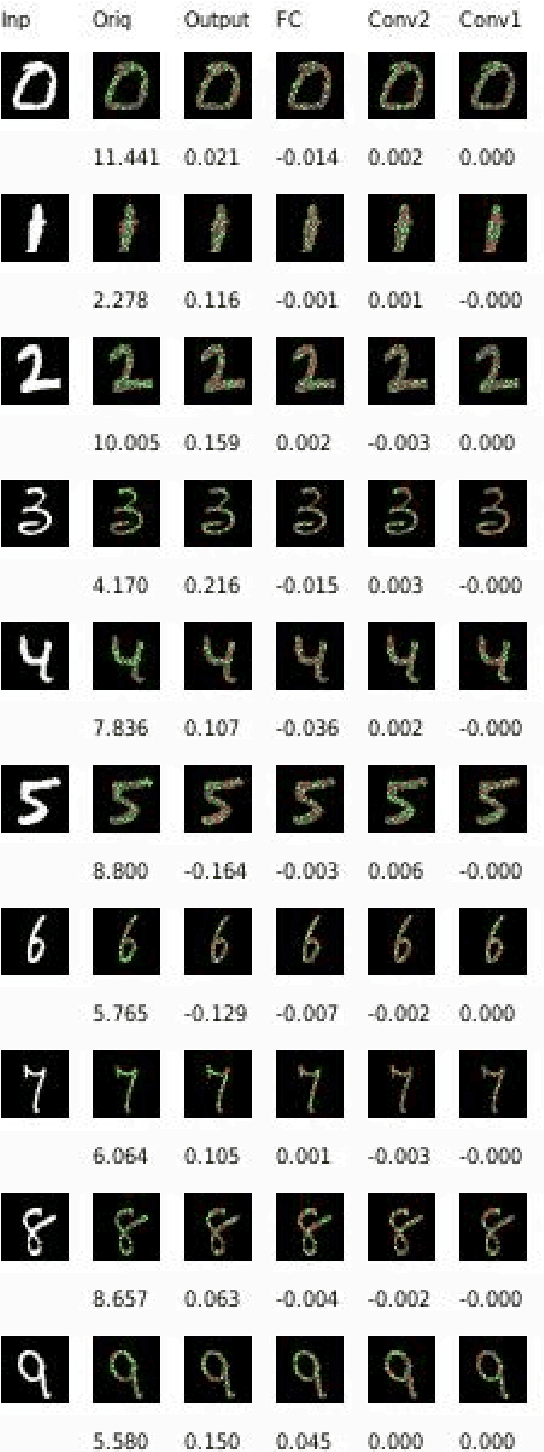
Local explanation methods, also known as attribution methods, attribute a deep network's prediction to its input (cf. Baehrens et al. (2010)). We respond to the claim from Adebayo et al. (2018) that local explanation methods lack sensitivity, i.e., DNNs with randomly-initialized weights produce explanations that are both visually and quantitatively similar to those produced by DNNs with learned weights. Further investigation reveals that their findings are due to two choices in their analysis: (a) ignoring the signs of the attributions; and (b) for integrated gradients (IG), including pixels in their analysis that have zero attributions by choice of the baseline (an auxiliary input relative to which the attributions are computed). When both factors are accounted for, IG attributions for a random network and the actual network are uncorrelated. Our investigation also sheds light on how these issues affect visualizations, although we note that more work is needed to understand how viewers interpret the difference between the random and the actual attributions.
Did the Model Understand the Question?
May 14, 2018
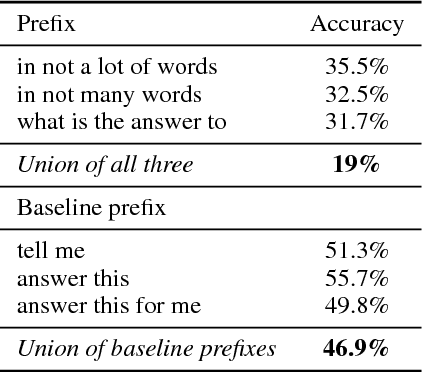
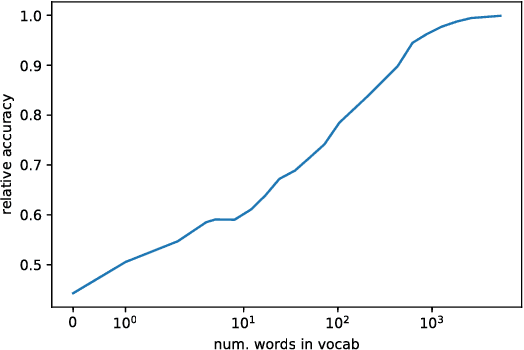

We analyze state-of-the-art deep learning models for three tasks: question answering on (1) images, (2) tables, and (3) passages of text. Using the notion of \emph{attribution} (word importance), we find that these deep networks often ignore important question terms. Leveraging such behavior, we perturb questions to craft a variety of adversarial examples. Our strongest attacks drop the accuracy of a visual question answering model from $61.1\%$ to $19\%$, and that of a tabular question answering model from $33.5\%$ to $3.3\%$. Additionally, we show how attributions can strengthen attacks proposed by Jia and Liang (2017) on paragraph comprehension models. Our results demonstrate that attributions can augment standard measures of accuracy and empower investigation of model performance. When a model is accurate but for the wrong reasons, attributions can surface erroneous logic in the model that indicates inadequacies in the test data.
It was the training data pruning too!
Mar 12, 2018We study the current best model (KDG) for question answering on tabular data evaluated over the WikiTableQuestions dataset. Previous ablation studies performed against this model attributed the model's performance to certain aspects of its architecture. In this paper, we find that the model's performance also crucially depends on a certain pruning of the data used to train the model. Disabling the pruning step drops the accuracy of the model from 43.3% to 36.3%. The large impact on the performance of the KDG model suggests that the pruning may be a useful pre-processing step in training other semantic parsers as well.
Abductive Matching in Question Answering
Sep 10, 2017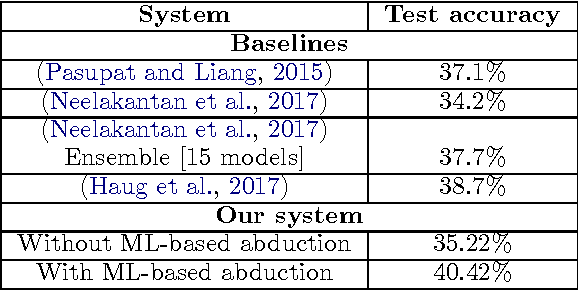
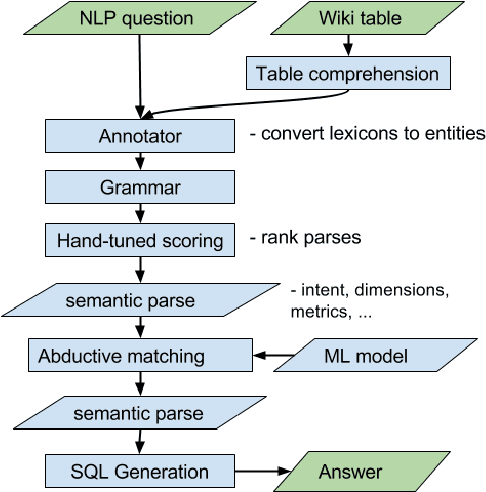

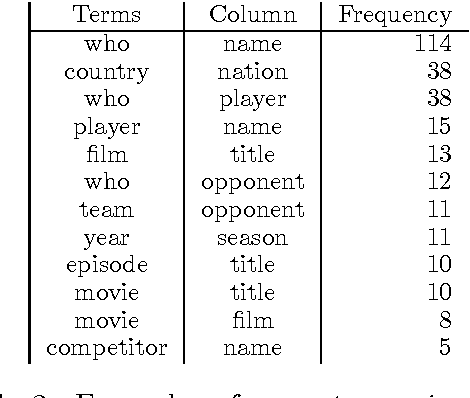
We study question-answering over semi-structured data. We introduce a new way to apply the technique of semantic parsing by applying machine learning only to provide annotations that the system infers to be missing; all the other parsing logic is in the form of manually authored rules. In effect, the machine learning is used to provide non-syntactic matches, a step that is ill-suited to manual rules. The advantage of this approach is in its debuggability and in its transparency to the end-user. We demonstrate the effectiveness of the approach by achieving state-of-the-art performance of 40.42% accuracy on a standard benchmark dataset over tables from Wikipedia.
Axiomatic Attribution for Deep Networks
Jun 13, 2017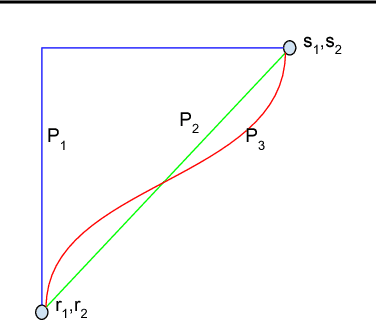


We study the problem of attributing the prediction of a deep network to its input features, a problem previously studied by several other works. We identify two fundamental axioms---Sensitivity and Implementation Invariance that attribution methods ought to satisfy. We show that they are not satisfied by most known attribution methods, which we consider to be a fundamental weakness of those methods. We use the axioms to guide the design of a new attribution method called Integrated Gradients. Our method requires no modification to the original network and is extremely simple to implement; it just needs a few calls to the standard gradient operator. We apply this method to a couple of image models, a couple of text models and a chemistry model, demonstrating its ability to debug networks, to extract rules from a network, and to enable users to engage with models better.
Gradients of Counterfactuals
Nov 15, 2016

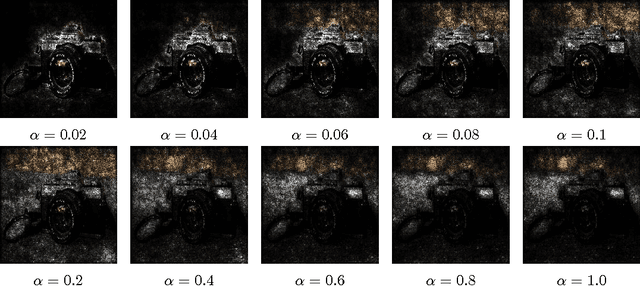

Gradients have been used to quantify feature importance in machine learning models. Unfortunately, in nonlinear deep networks, not only individual neurons but also the whole network can saturate, and as a result an important input feature can have a tiny gradient. We study various networks, and observe that this phenomena is indeed widespread, across many inputs. We propose to examine interior gradients, which are gradients of counterfactual inputs constructed by scaling down the original input. We apply our method to the GoogleNet architecture for object recognition in images, as well as a ligand-based virtual screening network with categorical features and an LSTM based language model for the Penn Treebank dataset. We visualize how interior gradients better capture feature importance. Furthermore, interior gradients are applicable to a wide variety of deep networks, and have the attribution property that the feature importance scores sum to the the prediction score. Best of all, interior gradients can be computed just as easily as gradients. In contrast, previous methods are complex to implement, which hinders practical adoption.