 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Language Identification using Multi-Head Self-Attention and 1D Convolutional Neural Networks
Jan 30, 2021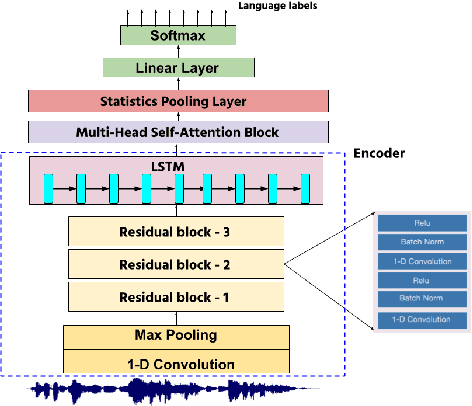
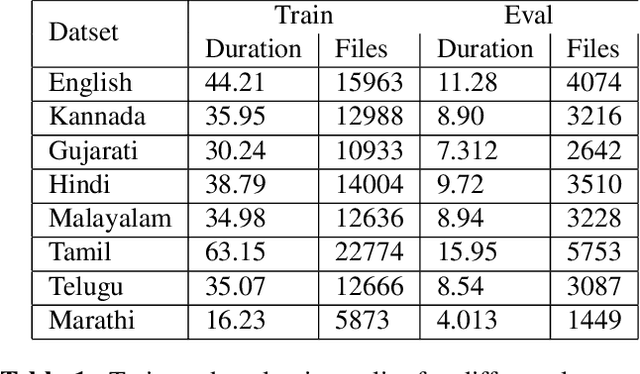
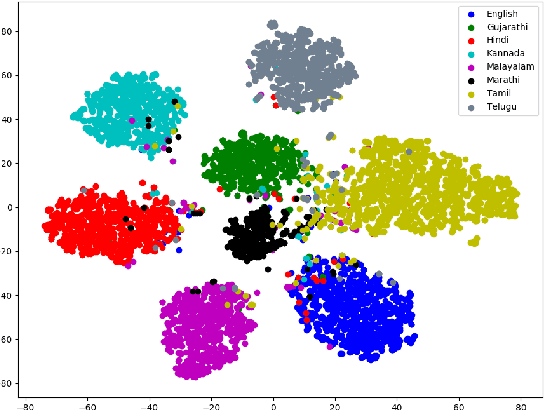
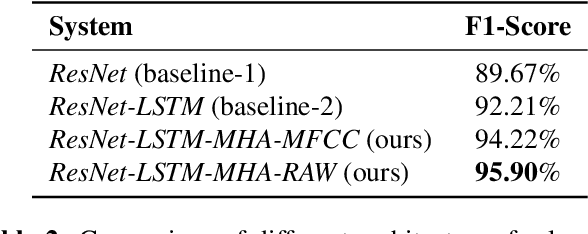
In this work, we propose a new approach for language identification using multi-head self-attention combined with raw waveform based 1D convolutional neural networks for Indian languages. Our approach uses an encoder, multi-head selfattention, and a statistics pooling layer. The encoder learns features directly from raw waveforms using 1D convolution kernels and an LSTM layer. The LSTM layer captures temporal information between the features extracted by the 1D convolutional layer. The multi-head self-attention layer takes outputs of the LSTM layer and applies self-attention mechanisms on these features with M different heads. This process helps the model give more weightage to the more useful features and less weightage to the less relevant features. Finally, the frame-level features are combined using a statistics pooling layer to extract the utterance-level feature vector label prediction. We conduct all our experiments on the 373 hrs of audio data for eight different Indian languages. Our experiments show that our approach outperforms the baseline model by an absolute 3.69% improvement in F1-score and achieves the best F1-score of 95.90%. Our approach also shows that using raw waveform models gets a 1.7% improvement in performance compared to the models built using handcrafted features.
Identification of Indian Languages using Ghost-VLAD pooling
Feb 05, 2020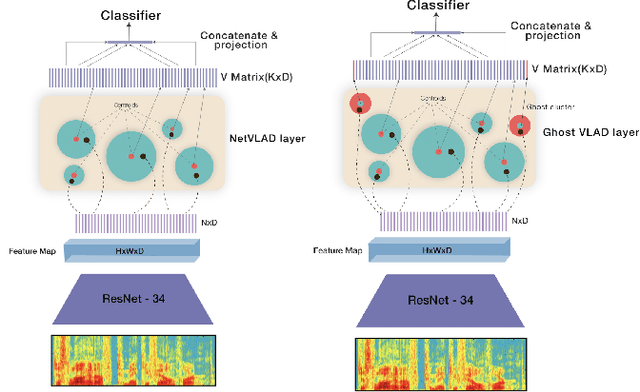
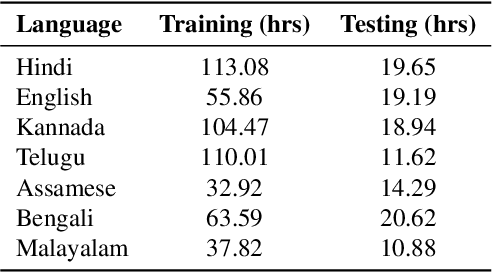

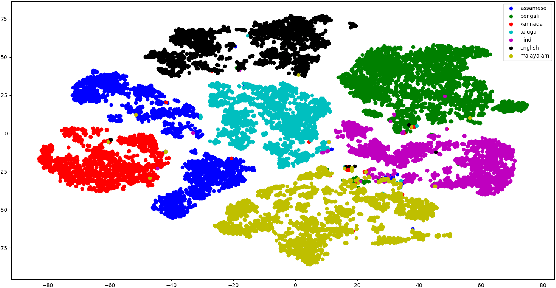
In this work, we propose a new pooling strategy for language identification by considering Indian languages. The idea is to obtain utterance level features for any variable length audio for robust language recognition. We use the GhostVLAD approach to generate an utterance level feature vector for any variable length input audio by aggregating the local frame level features across time. The generated feature vector is shown to have very good language discriminative features and helps in getting state of the art results for language identification task. We conduct our experiments on 635Hrs of audio data for 7 Indian languages. Our method outperforms the previous state of the art x-vector [11] method by an absolute improvement of 1.88% in F1-score and achieves 98.43% F1-score on the held-out test data. We compare our system with various pooling approaches and show that GhostVLAD is the best pooling approach for this task. We also provide visualization of the utterance level embeddings generated using Ghost-VLAD pooling and show that this method creates embeddings which has very good language discriminative features.