 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMAT: Global Memory Augmentation for Transformers
Jun 05, 2020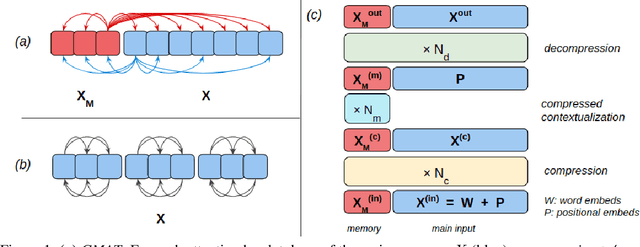
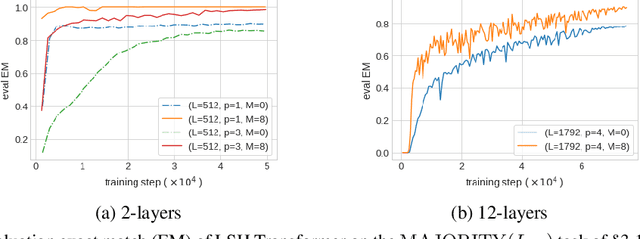
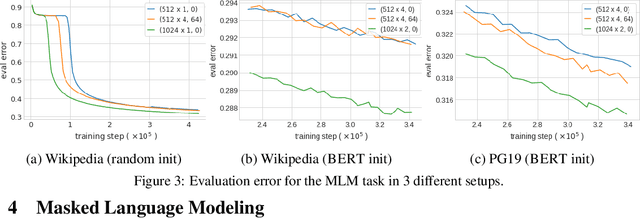

Transformer-based models have become ubiquitous in natural language processing thanks to their large capacity, innate parallelism and high performance. The contextualizing component of a Transformer block is the $\textit{pairwise dot-product}$ attention that has a large $\Omega(L^2)$ memory requirement for length $L$ sequences, limiting its ability to process long documents. This has been the subject of substantial interest recently, where multiple approximations were proposed to reduce the quadratic memory requirement using sparse attention matrices. In this work, we propose to augment sparse Transformer blocks with a dense attention-based $\textit{global memory}$ of length $M$ ($\ll L$) which provides an aggregate global view of the entire input sequence to each position. Our augmentation has a manageable $O(M\cdot(L+M))$ memory overhead, and can be seamlessly integrated with prior sparse solutions. Moreover, global memory can also be used for sequence compression, by representing a long input sequence with the memory representations only. We empirically show that our method leads to substantial improvement on a range of tasks, including (a) synthetic tasks that require global reasoning, (b) masked language modeling, and (c) reading comprehension.
Injecting Numerical Reasoning Skills into Language Models
Apr 09, 2020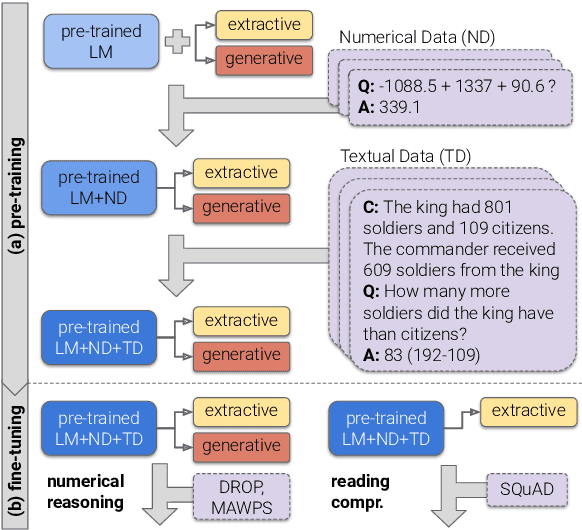

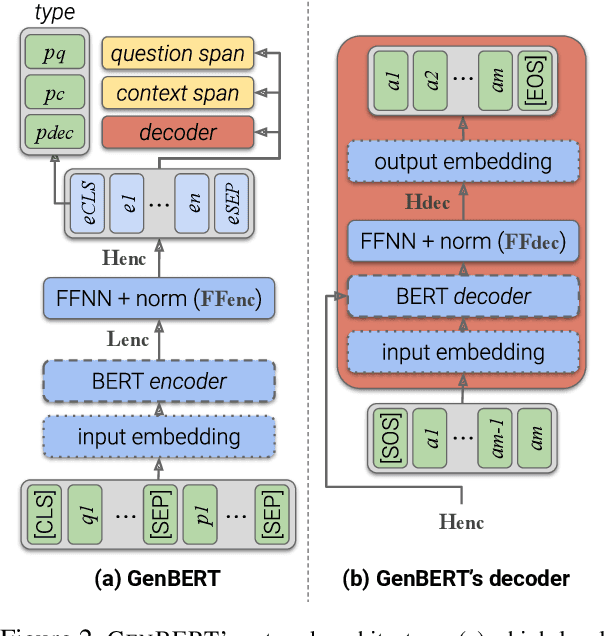

Large pre-trained language models (LMs) are known to encode substantial amounts of linguistic information. However, high-level reasoning skills, such as numerical reasoning, are difficult to learn from a language-modeling objective only. Consequently, existing models for numerical reasoning have used specialized architectures with limited flexibility. In this work, we show that numerical reasoning is amenable to automatic data generation, and thus one can inject this skill into pre-trained LMs, by generating large amounts of data, and training in a multi-task setup. We show that pre-training our model, GenBERT, on this data, dramatically improves performance on DROP (49.3 $\rightarrow$ 72.3 F1), reaching performance that matches state-of-the-art models of comparable size, while using a simple and general-purpose encoder-decoder architecture. Moreover, GenBERT generalizes well to math word problem datasets, while maintaining high performance on standard RC tasks. Our approach provides a general recipe for injecting skills into large pre-trained LMs, whenever the skill is amenable to automatic data augmentation.
Break It Down: A Question Understanding Benchmark
Jan 31, 2020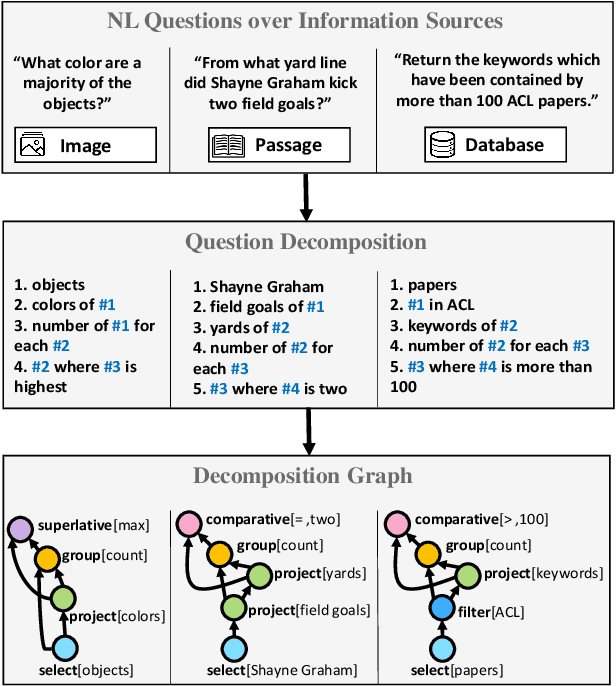
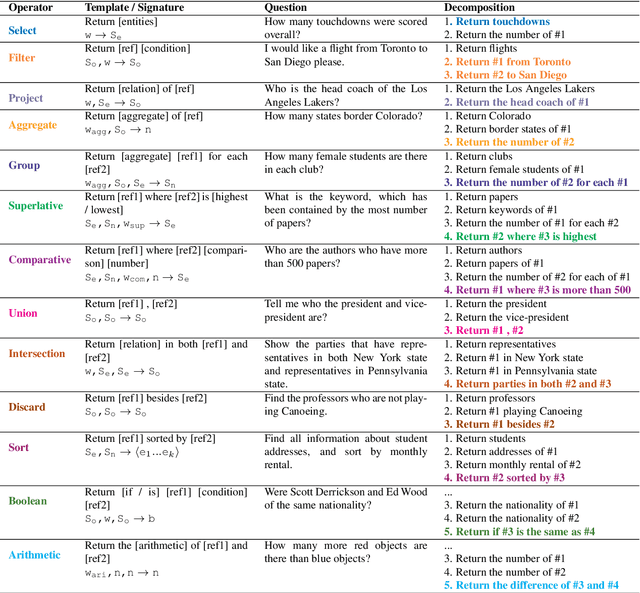
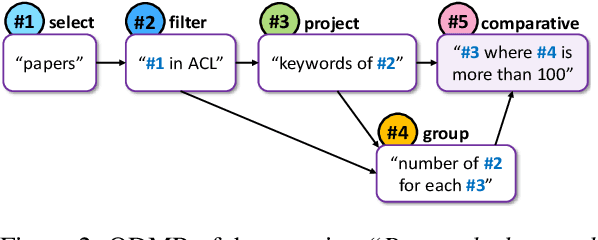

Understanding natural language questions entails the ability to break down a question into the requisite steps for computing its answer. In this work, we introduce a Question Decomposition Meaning Representation (QDMR) for questions. QDMR constitutes the ordered list of steps, expressed through natural language, that are necessary for answering a question. We develop a crowdsourcing pipeline, showing that quality QDMRs can be annotated at scale, and release the Break dataset, containing over 83K pairs of questions and their QDMRs. We demonstrate the utility of QDMR by showing that (a) it can be used to improve open-domain question answering on the HotpotQA dataset, (b) it can be deterministically converted to a pseudo-SQL formal language, which can alleviate annotation in semantic parsing applications. Last, we use Break to train a sequence-to-sequence model with copying that parses questions into QDMR structures, and show that it substantially outperforms several natural baselines.
HeartFit: An Accurate Platform for Heart Murmur Diagnosis Utilizing Deep Learning
Jul 24, 2019Cardiovascular disease (CD) is the number one leading cause of death worldwide, accounting for more than 17 million deaths in 2015. Critical indicators of CD include heart murmurs, intense sounds emitted by the heart during periods of irregular blood flow. Current diagnosis of heart murmurs relies on echocardiography (ECHO), which costs thousands of dollars and medical professionals to analyze the results, making it very unsuitable for areas with inadequate medical facilities. Thus, there is a need for an accessible alternative. Based on a simple interface and deep learning, HeartFit allows users to administer diagnoses themselves. An inexpensive, custom designed stethoscope in conjunction with a mobile application allows users to record and upload audio of their heart to a database. Using a deep learning network architecture, the database classifies the audio and returns the diagnosis to the user. The model consists of a deep recurrent convolutional neural network trained on 300 prelabeled heartbeat audio samples. After the model was validated on a previously unseen set of 100 heartbeat audio samples, it achieved a f beta score of 0.9545 and an accuracy of 95.5 percent. This value exceeds that of clinical examination accuracy, which is around 83 percent to 91 percent and costs orders of magnitude less than ECHO, demonstrating the effectiveness of the HeartFit platform. Through the platform, users can obtain immediate, accurate diagnosis of heart murmurs without any professional medical assistance, revolutionizing how we combat CD.
CAMLPAD: Cybersecurity Autonomous Machine Learning Platform for Anomaly Detection
Jul 23, 2019As machine learning and cybersecurity continue to explode in the context of the digital ecosystem, the complexity of cybersecurity data combined with complicated and evasive machine learning algorithms leads to vast difficulties in designing an end to end system for intelligent, automatic anomaly classification. On the other hand, traditional systems use elementary statistics techniques and are often inaccurate, leading to weak centralized data analysis platforms. In this paper, we propose a novel system that addresses these two problems, titled CAMLPAD, for Cybersecurity Autonomous Machine Learning Platform for Anomaly Detection. The CAMLPAD systems streamlined, holistic approach begins with retrieving a multitude of different species of cybersecurity data in real time using elasticsearch, then running several machine learning algorithms, namely Isolation Forest, Histogram Based Outlier Score (HBOS), Cluster Based Local Outlier Factor (CBLOF), and K Means Clustering, to process the data. Next, the calculated anomalies are visualized using Kibana and are assigned an outlier score, which serves as an indicator for whether an alert should be sent to the system administrator that there are potential anomalies in the network. After comprehensive testing of our platform in a simulated environment, the CAMLPAD system achieved an adjusted rand score of 95 percent, exhibiting the reliable accuracy and precision of the system. All in all, the CAMLPAD system provides an accurate, streamlined approach to real time cybersecurity anomaly detection, delivering a novel solution that has the potential to revolutionize the cybersecurity sector.
User-Interactive Machine Learning Model for Identifying Structural Relationships of Code Features
Jul 18, 2019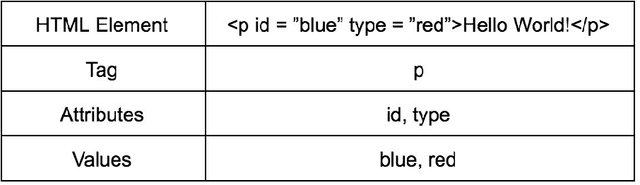
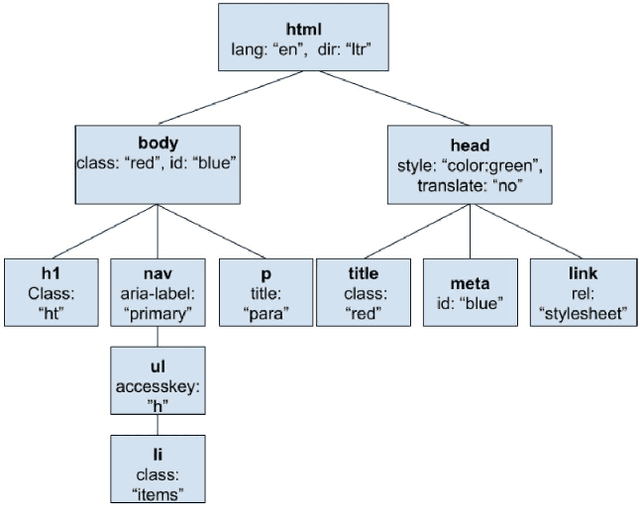
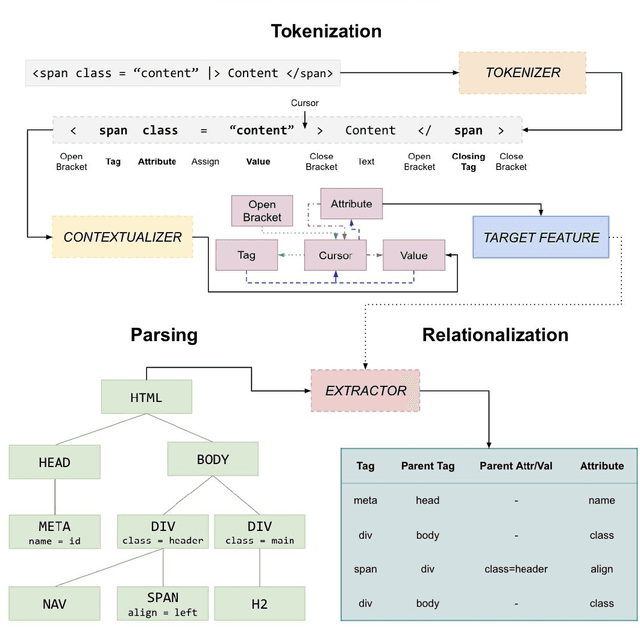
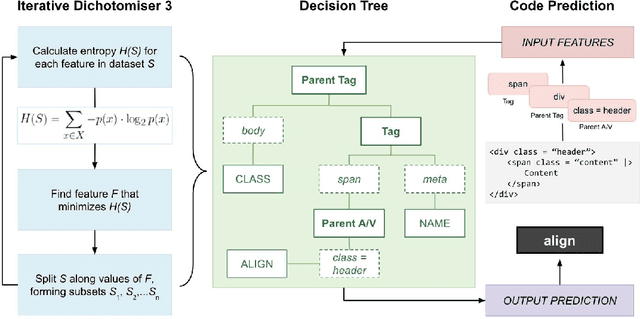
Traditional machine learning based intelligent systems assist users by learning patterns in data and making recommendations. However, these systems are limited in that the user has little means of understanding the rationale behind the systems suggestions, communicating their own understanding of patterns, or correcting system behavior. In this project, we outline a model for intelligent software based on a human computer feedback loop. The Machine Learning (ML) systems recommendations are reviewed by the user, and in turn, this information shapes the systems decision making. Our model was applied to developing an HTML editor that integrates ML with user interaction to ascertain structural relationships between HTML document features and apply them for code completion. The editor utilizes the ID3 algorithm to build decision trees, sequences of rules for predicting code the user will type. The editor displays the decision trees rules in the Interactive Rules Interface System (IRIS), which allows developers to prioritize, modify, or delete them. These interactions alter the data processed by ID3, providing the developer some control over the autocomplete system. Validation indicates that, absent user interaction, the ML model is able to predict tags with 78.4 percent accuracy, attributes with 62.9 percent accuracy, and values with 12.8 percent accuracy. Based off of the results of the user study, user interaction with the rules interface corrects feature relationships missed or mistaken by the automated process, enhancing autocomplete accuracy and developer productivity. Additionally, interaction is proven to help developers work with greater awareness of code patterns. Our research demonstrates the viability of a software integration of machine intelligence with human feedback.
AquaSight: Automatic Water Impurity Detection Utilizing Convolutional Neural Networks
Jul 17, 2019According to the United Nations World Water Assessment Programme, every day, 2 million tons of sewage and industrial and agricultural waste are discharged into the worlds water. In order to address this pervasive issue of increasing water pollution, while ensuring that the global population has an efficient, accurate, and low cost method to assess whether the water they drink is contaminated, we propose AquaSight, a novel mobile application that utilizes deep learning methods, specifically Convolutional Neural Networks, for automated water impurity detection. After comprehensive training with a dataset of 105 images representing varying magnitudes of contamination, the deep learning algorithm achieved a 96 percent accuracy and loss of 0.108. Furthermore, the machine learning model uses efficient analysis of the turbidity and transparency levels of water to estimate a particular sample of waters level of contamination. When deployed, the AquaSight system will provide an efficient way for individuals to secure an estimation of water quality, alerting local and national government to take action and potentially saving millions of lives worldwide.
StrokeSave: A Novel, High-Performance Mobile Application for Stroke Diagnosis using Deep Learning and Computer Vision
Jul 09, 2019According to the WHO, Cerebrovascular Stroke, or CS, is the second largest cause of death worldwide. Current diagnosis of CS relies on labor and cost intensive neuroimaging techniques, unsuitable for areas with inadequate access to quality medical facilities. Thus, there is a great need for an efficient diagnosis alternative. StrokeSave is a platform for users to self-diagnose for prevalence to stroke. The mobile app is continuously updated with heart rate, blood pressure, and blood oxygen data from sensors on the patient wrist. Once these measurements reach a threshold for possible stroke, the patient takes facial images and vocal recordings to screen for paralysis attributed to stroke. A custom designed lens attached to a phone's camera then takes retinal images for the deep learning model to classify based on presence of retinopathy and sends a comprehensive diagnosis. The deep learning model, which consists of a RNN trained on 100 voice slurred audio files, a SVM trained on 410 vascular data points, and a CNN trained on 520 retinopathy images, achieved a holistic accuracy of 95.0 percent when validated on 327 samples. This value exceeds that of clinical examination accuracy, which is around 40 to 89 percent, further demonstrating the vital utility of such a medical device. Through this automated platform, users receive efficient, highly accurate diagnosis without professional medical assistance, revolutionizing medical diagnosis of CS and potentially saving millions of lives.
Dilated Convolutions for Modeling Long-Distance Genomic Dependencies
Oct 03, 2017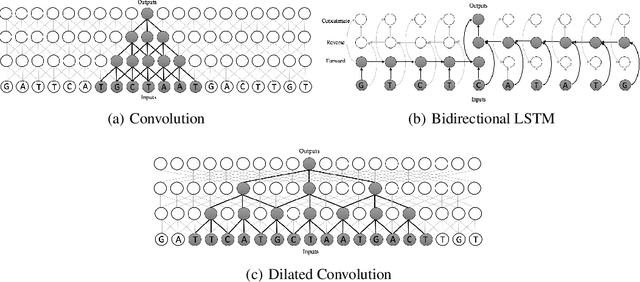
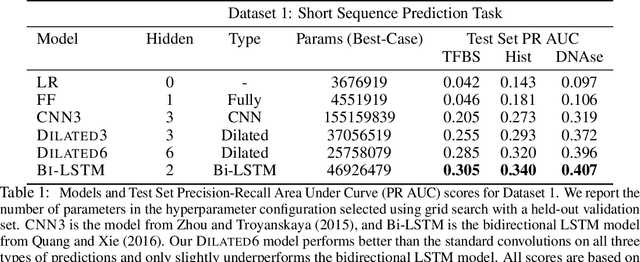
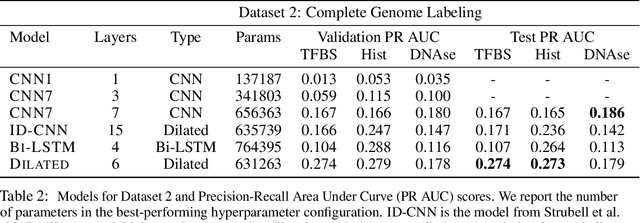
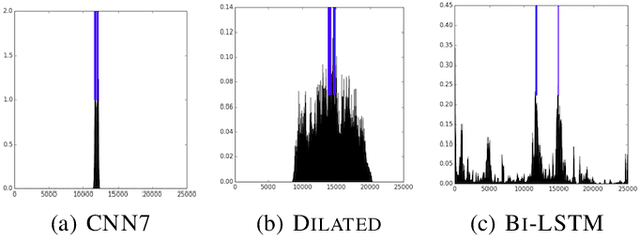
We consider the task of detecting regulatory elements in the human genome directly from raw DNA. Past work has focused on small snippets of DNA, making it difficult to model long-distance dependencies that arise from DNA's 3-dimensional conformation. In order to study long-distance dependencies, we develop and release a novel dataset for a larger-context modeling task. Using this new data set we model long-distance interactions using dilated convolutional neural networks, and compare them to standard convolutions and recurrent neural networks. We show that dilated convolutions are effective at modeling the locations of regulatory markers in the human genome, such as transcription factor binding sites, histone modifications, and DNAse hypersensitivity sites.
A Comparative Analysis of Tensor Decomposition Models Using Hyper Spectral Image
Mar 23, 2015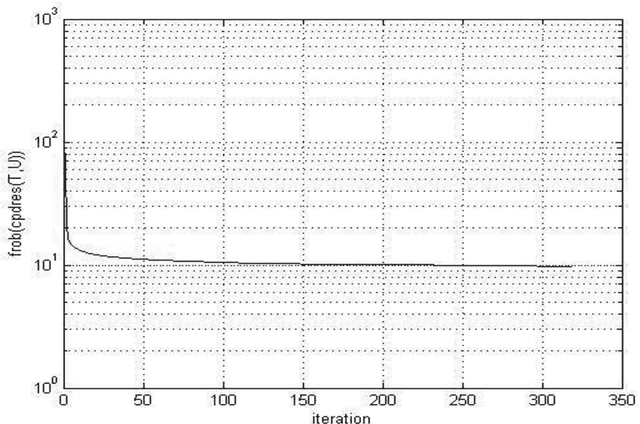
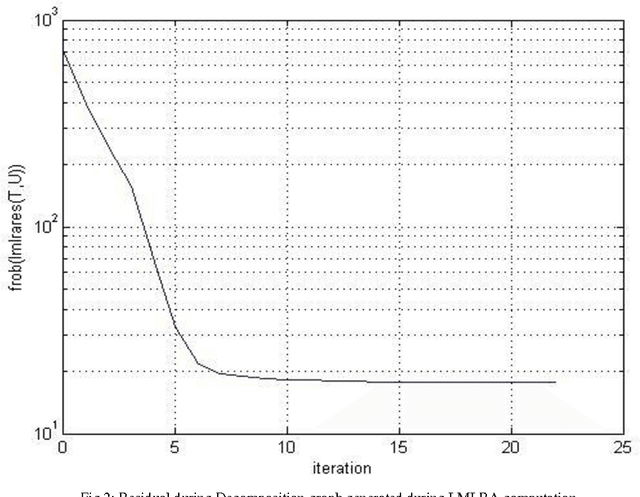
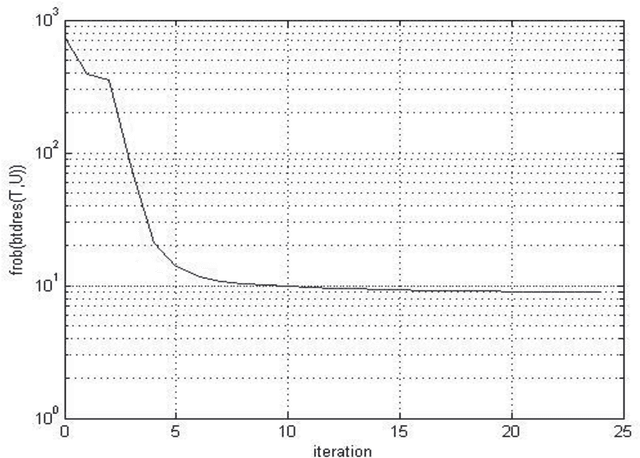

Hyper spectral imaging is a remote sensing technology, providing variety of applications such as material identification, space object identification, planetary exploitation etc. It deals with capturing continuum of images of the earth surface from different angles. Due to the multidimensional nature of the image, multi-way arrays are one of the possible solutions for analyzing hyper spectral data. This multi-way array is called tensor. Our approach deals with implementing three decomposition models LMLRA, BTD and CPD to the sample data for choosing the best decomposition of the data set. The results have proved that Block Term Decomposition (BTD) is the best tensor model for decomposing the hyper spectral image in to resultant factor matrices.
* 7 pages, 3 figures,1 table