 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWEPSAM: Weakly Pre-Learnt Saliency Model
May 03, 2016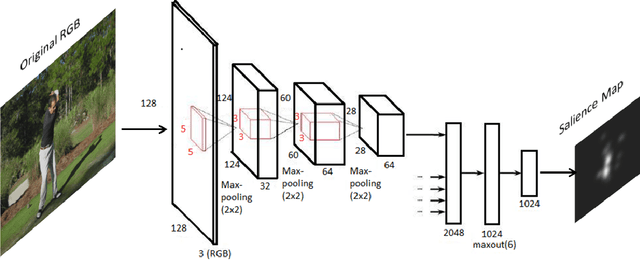
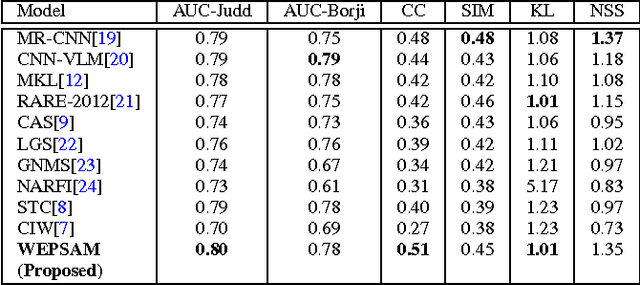
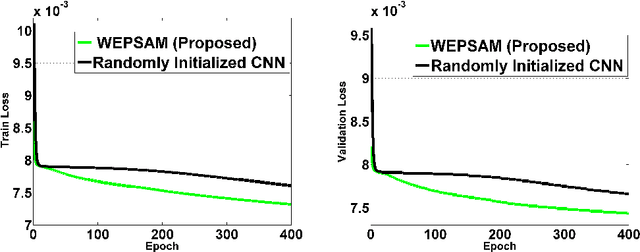
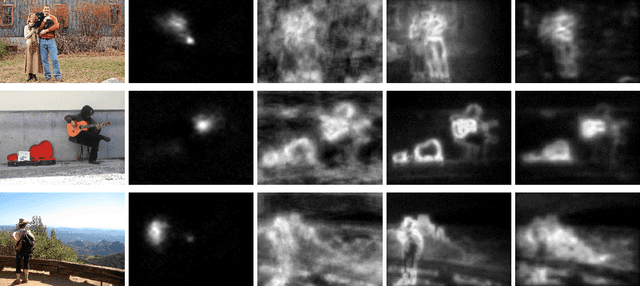
Visual saliency detection tries to mimic human vision psychology which concentrates on sparse, important areas in natural image. Saliency prediction research has been traditionally based on low level features such as contrast, edge, etc. Recent thrust in saliency prediction research is to learn high level semantics using ground truth eye fixation datasets. In this paper we present, WEPSAM : Weakly Pre-Learnt Saliency Model as a pioneering effort of using domain specific pre-learing on ImageNet for saliency prediction using a light weight CNN architecture. The paper proposes a two step hierarchical learning, in which the first step is to develop a framework for weakly pre-training on a large scale dataset such as ImageNet which is void of human eye fixation maps. The second step refines the pre-trained model on a limited set of ground truth fixations. Analysis of loss on iSUN and SALICON datasets reveal that pre-trained network converges much faster compared to randomly initialized network. WEPSAM also outperforms some recent state-of-the-art saliency prediction models on the challenging MIT300 dataset.
Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus Images
Mar 15, 2016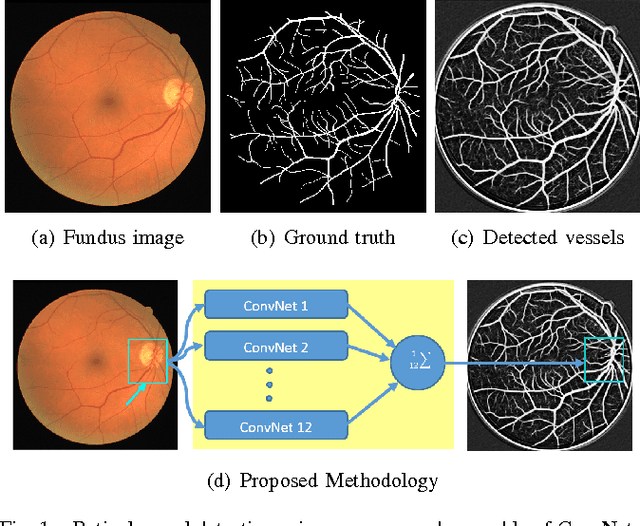
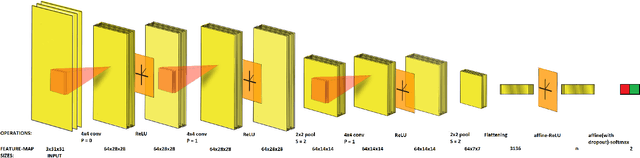
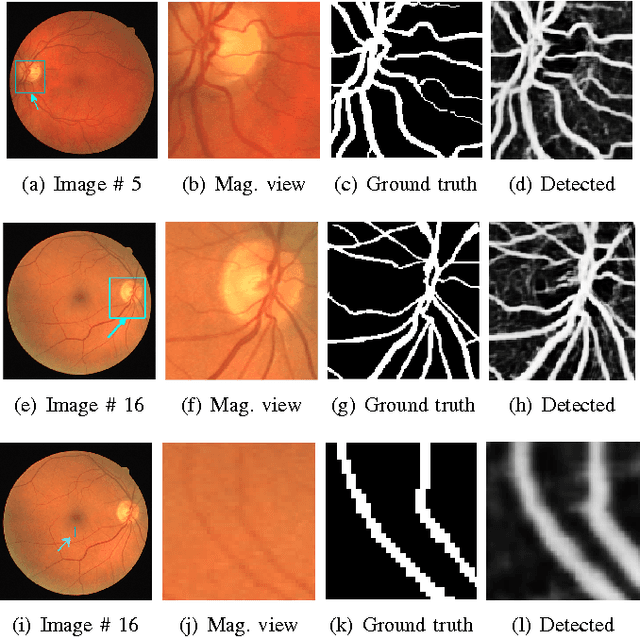
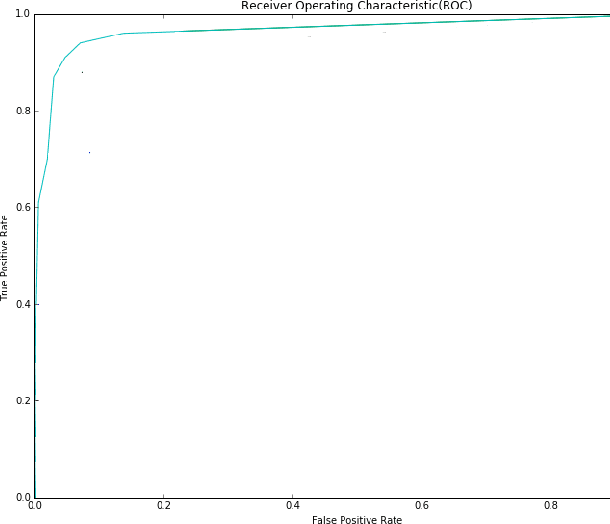
Vision impairment due to pathological damage of the retina can largely be prevented through periodic screening using fundus color imaging. However the challenge with large scale screening is the inability to exhaustively detect fine blood vessels crucial to disease diagnosis. In this work we present a computational imaging framework using deep and ensemble learning for reliable detection of blood vessels in fundus color images. An ensemble of deep convolutional neural networks is trained to segment vessel and non-vessel areas of a color fundus image. During inference, the responses of the individual ConvNets of the ensemble are averaged to form the final segmentation. In experimental evaluation with the DRIVE database, we achieve the objective of vessel detection with maximum average accuracy of 94.7\% and area under ROC curve of 0.9283.
Faster learning of deep stacked autoencoders on multi-core systems using synchronized layer-wise pre-training
Mar 09, 2016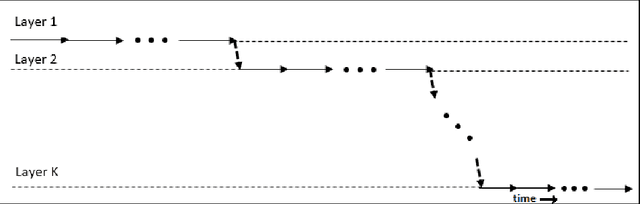

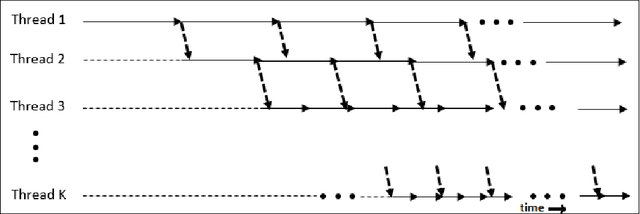
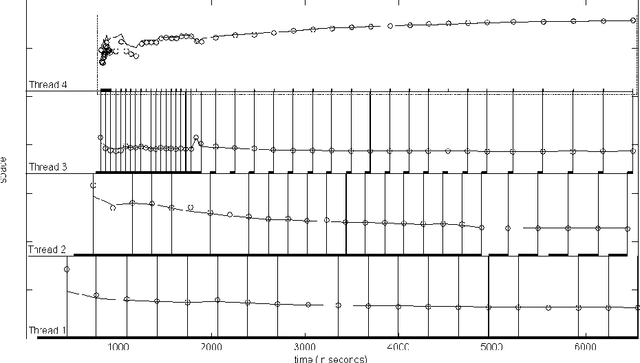
Deep neural networks are capable of modelling highly non-linear functions by capturing different levels of abstraction of data hierarchically. While training deep networks, first the system is initialized near a good optimum by greedy layer-wise unsupervised pre-training. However, with burgeoning data and increasing dimensions of the architecture, the time complexity of this approach becomes enormous. Also, greedy pre-training of the layers often turns detrimental by over-training a layer causing it to lose harmony with the rest of the network. In this paper a synchronized parallel algorithm for pre-training deep networks on multi-core machines has been proposed. Different layers are trained by parallel threads running on different cores with regular synchronization. Thus the pre-training process becomes faster and chances of over-training are reduced. This is experimentally validated using a stacked autoencoder for dimensionality reduction of MNIST handwritten digit database. The proposed algorithm achieved 26\% speed-up compared to greedy layer-wise pre-training for achieving the same reconstruction accuracy substantiating its potential as an alternative.