 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Sustainability And Performance: The Role Of Small-Scale Llms In Agentic Artificial Intelligence Systems
Jan 27, 2026As large language models become integral to agentic artificial intelligence systems, their energy demands during inference may pose significant sustainability challenges. This study investigates whether deploying smaller-scale language models can reduce energy consumption without compromising responsiveness and output quality in a multi-agent, real-world environments. We conduct a comparative analysis across language models of varying scales to quantify trade-offs between efficiency and performance. Results show that smaller open-weights models can lower energy usage while preserving task quality. Building on these findings, we propose practical guidelines for sustainable artificial intelligence design, including optimal batch size configuration and computation resource allocation. These insights offer actionable strategies for developing scalable, environmentally responsible artificial intelligence systems.
Generative latent neural models for automatic word alignment
Sep 28, 2020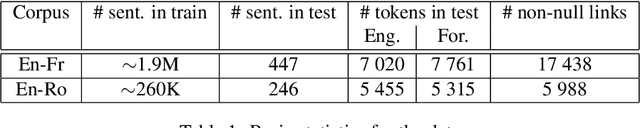

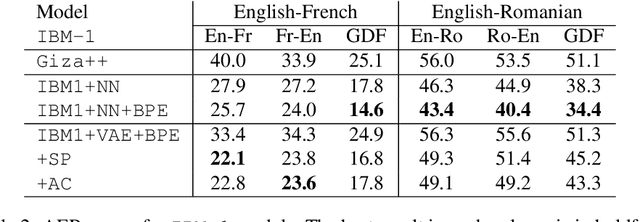
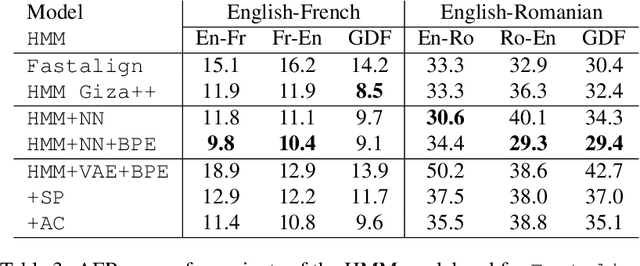
Word alignments identify translational correspondences between words in a parallel sentence pair and are used, for instance, to learn bilingual dictionaries, to train statistical machine translation systems or to perform quality estimation. Variational autoencoders have been recently used in various of natural language processing to learn in an unsupervised way latent representations that are useful for language generation tasks. In this paper, we study these models for the task of word alignment and propose and assess several evolutions of a vanilla variational autoencoders. We demonstrate that these techniques can yield competitive results as compared to Giza++ and to a strong neural network alignment system for two language pairs.
Neural Baselines for Word Alignment
Sep 28, 2020

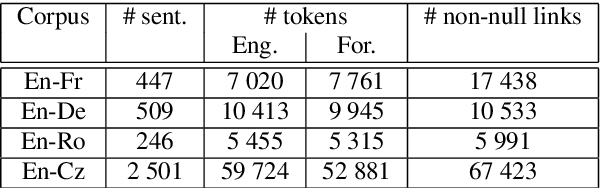
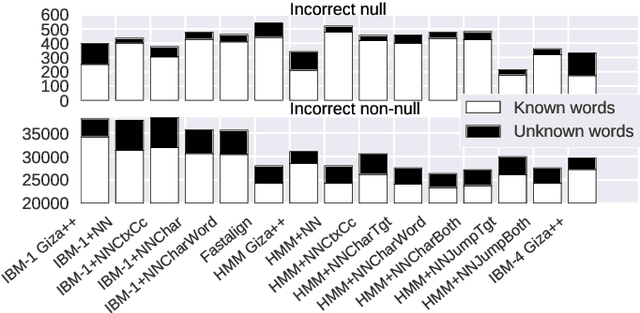
Word alignments identify translational correspondences between words in a parallel sentence pair and is used, for instance, to learn bilingual dictionaries, to train statistical machine translation systems , or to perform quality estimation. In most areas of natural language processing, neural network models nowadays constitute the preferred approach, a situation that might also apply to word alignment models. In this work, we study and comprehensively evaluate neural models for unsupervised word alignment for four language pairs, contrasting several variants of neural models. We show that in most settings, neural versions of the IBM-1 and hidden Markov models vastly outperform their discrete counterparts. We also analyze typical alignment errors of the baselines that our models overcome to illustrate the benefits-and the limitations-of these new models for morphologically rich languages.