 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHate Speech Detection on Vietnamese Social Media Text using the Bi-GRU-LSTM-CNN Model
Dec 22, 2019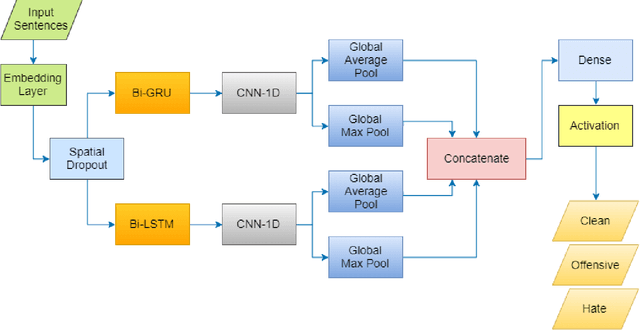
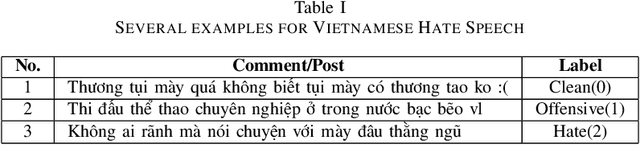
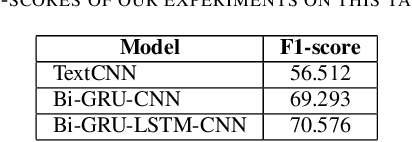
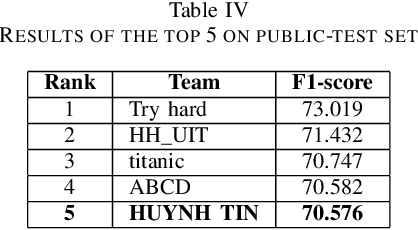
In recent years, Hate Speech Detection has become one of the interesting fields in natural language processing or computational linguistics. In this paper, we present the description of our system to solve this problem at the VLSP shared task 2019: Hate Speech Detection on Social Networks with the corpus which contains 20,345 human-labeled comments/posts for training and 5,086 for public-testing. We implement a deep learning method based on the Bi-GRU-LSTM-CNN classifier into this task. Our result in this task is 70.576% of F1-score, ranking the 5th of performance on public-test set.
* Technical Report, VLSP Workshop 2019
Hate Speech Detection on Vietnamese Social Media Text using the Bidirectional-LSTM Model
Nov 09, 2019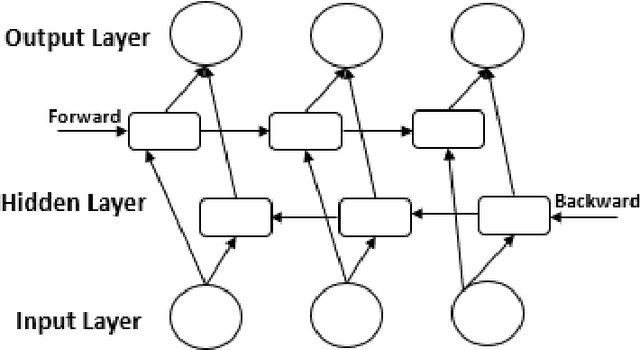

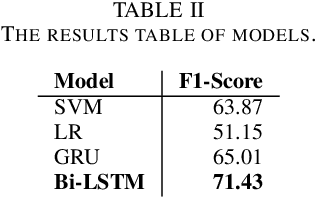
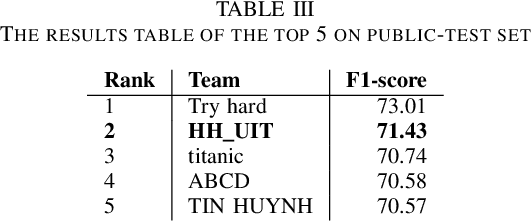
In this paper, we describe our system which participates in the shared task of Hate Speech Detection on Social Networks of VLSP 2019 evaluation campaign. We are provided with the pre-labeled dataset and an unlabeled dataset for social media comments or posts. Our mission is to pre-process and build machine learning models to classify comments/posts. In this report, we use Bidirectional Long Short-Term Memory to build the model that can predict labels for social media text according to Clean, Offensive, Hate. With this system, we achieve comparative results with 71.43% on the public standard test set of VLSP 2019.