 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Learning Experience: Using Vision-Language Models to Generate Questions for Educational Videos
May 03, 2025Web-based educational videos offer flexible learning opportunities and are becoming increasingly popular. However, improving user engagement and knowledge retention remains a challenge. Automatically generated questions can activate learners and support their knowledge acquisition. Further, they can help teachers and learners assess their understanding. While large language and vision-language models have been employed in various tasks, their application to question generation for educational videos remains underexplored. In this paper, we investigate the capabilities of current vision-language models for generating learning-oriented questions for educational video content. We assess (1) out-of-the-box models' performance; (2) fine-tuning effects on content-specific question generation; (3) the impact of different video modalities on question quality; and (4) in a qualitative study, question relevance, answerability, and difficulty levels of generated questions. Our findings delineate the capabilities of current vision-language models, highlighting the need for fine-tuning and addressing challenges in question diversity and relevance. We identify requirements for future multimodal datasets and outline promising research directions.
Validating LLM-Generated Relevance Labels for Educational Resource Search
Apr 17, 2025Manual relevance judgements in Information Retrieval are costly and require expertise, driving interest in using Large Language Models (LLMs) for automatic assessment. While LLMs have shown promise in general web search scenarios, their effectiveness for evaluating domain-specific search results, such as educational resources, remains unexplored. To investigate different ways of including domain-specific criteria in LLM prompts for relevance judgement, we collected and released a dataset of 401 human relevance judgements from a user study involving teaching professionals performing search tasks related to lesson planning. We compared three approaches to structuring these prompts: a simple two-aspect evaluation baseline from prior work on using LLMs as relevance judges, a comprehensive 12-dimensional rubric derived from educational literature, and criteria directly informed by the study participants. Using domain-specific frameworks, LLMs achieved strong agreement with human judgements (Cohen's $\kappa$ up to 0.650), significantly outperforming the baseline approach. The participant-derived framework proved particularly robust, with GPT-3.5 achieving $\kappa$ scores of 0.639 and 0.613 for 10-dimension and 5-dimension versions respectively. System-level evaluation showed that LLM judgements reliably identified top-performing retrieval approaches (RBO scores 0.71-0.76) while maintaining reasonable discrimination between systems (RBO 0.52-0.56). These findings suggest that LLMs can effectively evaluate educational resources when prompted with domain-specific criteria, though performance varies with framework complexity and input structure.
Unraveling the Impact of Visual Complexity on Search as Learning
Jan 09, 2025

Information search has become essential for learning and knowledge acquisition, offering broad access to information and learning resources. The visual complexity of web pages is known to influence search behavior, with previous work suggesting that searchers make evaluative judgments within the first second on a page. However, there is a significant gap in our understanding of how visual complexity impacts searches specifically conducted with a learning intent. This gap is particularly relevant for the development of optimized information retrieval (IR) systems that effectively support educational objectives. To address this research need, we model visual complexity and aesthetics via a diverse set of features, investigating their relationship with search behavior during learning-oriented web sessions. Our study utilizes a publicly available dataset from a lab study where participants learned about thunderstorm formation. Our findings reveal that while content relevance is the most significant predictor for knowledge gain, sessions with less visually complex pages are associated with higher learning success. This observation applies to features associated with the layout of web pages rather than to simpler features (e.g., number of images). The reported results shed light on the impact of visual complexity on learning-oriented searches, informing the design of more effective IR systems for educational contexts. To foster reproducibility, we release our source code (https://github.com/TIBHannover/sal_visual_complexity).
Saliency Detection in Educational Videos: Analyzing the Performance of Current Models, Identifying Limitations and Advancement Directions
Aug 08, 2024



Identifying the regions of a learning resource that a learner pays attention to is crucial for assessing the material's impact and improving its design and related support systems. Saliency detection in videos addresses the automatic recognition of attention-drawing regions in single frames. In educational settings, the recognition of pertinent regions in a video's visual stream can enhance content accessibility and information retrieval tasks such as video segmentation, navigation, and summarization. Such advancements can pave the way for the development of advanced AI-assisted technologies that support learning with greater efficacy. However, this task becomes particularly challenging for educational videos due to the combination of unique characteristics such as text, voice, illustrations, animations, and more. To the best of our knowledge, there is currently no study that evaluates saliency detection approaches in educational videos. In this paper, we address this gap by evaluating four state-of-the-art saliency detection approaches for educational videos. We reproduce the original studies and explore the replication capabilities for general-purpose (non-educational) datasets. Then, we investigate the generalization capabilities of the models and evaluate their performance on educational videos. We conduct a comprehensive analysis to identify common failure scenarios and possible areas of improvement. Our experimental results show that educational videos remain a challenging context for generic video saliency detection models.
On the Influence of Reading Sequences on Knowledge Gain during Web Search
Jan 10, 2024Nowadays, learning increasingly involves the usage of search engines and web resources. The related interdisciplinary research field search as learning aims to understand how people learn on the web. Previous work has investigated several feature classes to predict, for instance, the expected knowledge gain during web search. Therein, eye-tracking features have not been extensively studied so far. In this paper, we extend a previously used reading model from a line-based one to one that can detect reading sequences across multiple lines. We use publicly available study data from a web-based learning task to examine the relationship between our feature set and the participants' test scores. Our findings demonstrate that learners with higher knowledge gain spent significantly more time reading, and processing more words in total. We also find evidence that faster reading at the expense of more backward regressions may be an indicator of better web-based learning. We make our code publicly available at https://github.com/TIBHannover/reading_web_search.
Predicting Knowledge Gain for MOOC Video Consumption
Dec 13, 2022Informal learning on the Web using search engines as well as more structured learning on MOOC platforms have become very popular in recent years. As a result of the vast amount of available learning resources, intelligent retrieval and recommendation methods are indispensable -- this is true also for MOOC videos. However, the automatic assessment of this content with regard to predicting (potential) knowledge gain has not been addressed by previous work yet. In this paper, we investigate whether we can predict learning success after MOOC video consumption using 1) multimodal features covering slide and speech content, and 2) a wide range of text-based features describing the content of the video. In a comprehensive experimental setting, we test four different classifiers and various feature subset combinations. We conduct a detailed feature importance analysis to gain insights in which modality benefits knowledge gain prediction the most.
* 13 pages, 1 figure, 3 tables
SaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.
Evaluation of Automated Image Descriptions for Visually Impaired Students
Jun 29, 2021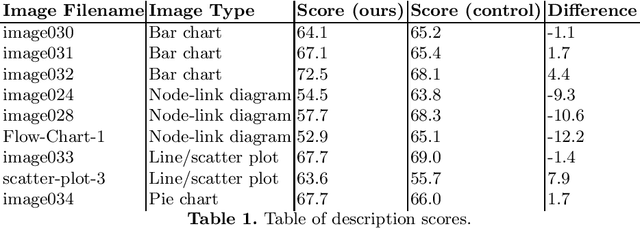
Illustrations are widely used in education, and sometimes, alternatives are not available for visually impaired students. Therefore, those students would benefit greatly from an automatic illustration description system, but only if those descriptions were complete, correct, and easily understandable using a screenreader. In this paper, we report on a study for the assessment of automated image descriptions. We interviewed experts to establish evaluation criteria, which we then used to create an evaluation questionnaire for sighted non-expert raters, and description templates. We used this questionnaire to evaluate the quality of descriptions which could be generated with a template-based automatic image describer. We present evidence that these templates have the potential to generate useful descriptions, and that the questionnaire identifies problems with description templates.
* 6 pages, 12 references. Accepted for publication at the 22nd International Conference on Artificial Intelligence in Education (AIED 2021), June 14-16 2021, Utrecht, The Netherlands
Predicting Knowledge Gain during Web Search based on Multimedia Resource Consumption
Jun 11, 2021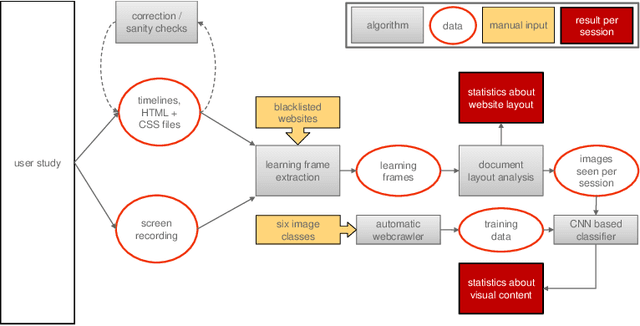
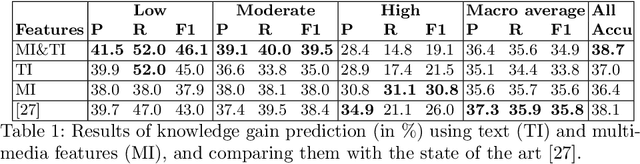
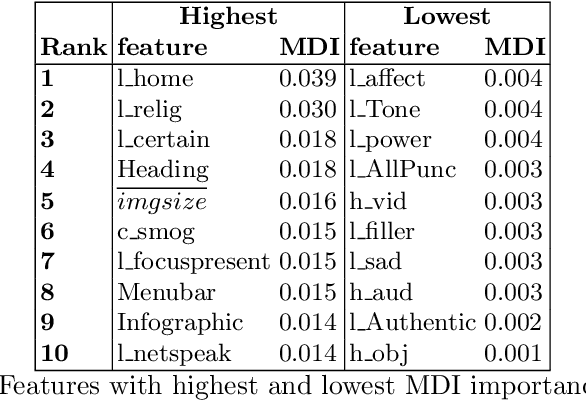
In informal learning scenarios the popularity of multimedia content, such as video tutorials or lectures, has significantly increased. Yet, the users' interactions, navigation behavior, and consequently learning outcome, have not been researched extensively. Related work in this field, also called search as learning, has focused on behavioral or text resource features to predict learning outcome and knowledge gain. In this paper, we investigate whether we can exploit features representing multimedia resource consumption to predict of knowledge gain (KG) during Web search from in-session data, that is without prior knowledge about the learner. For this purpose, we suggest a set of multimedia features related to image and video consumption. Our feature extraction is evaluated in a lab study with 113 participants where we collected data for a given search as learning task on the formation of thunderstorms and lightning. We automatically analyze the monitored log data and utilize state-of-the-art computer vision methods to extract features about the seen multimedia resources. Experimental results demonstrate that multimedia features can improve KG prediction. Finally, we provide an analysis on feature importance (text and multimedia) for KG prediction.
Citation Recommendation for Research Papers via Knowledge Graphs
Jun 10, 2021
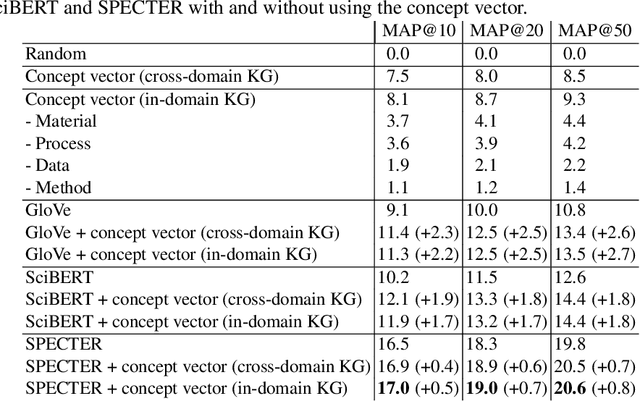
Citation recommendation for research papers is a valuable task that can help researchers improve the quality of their work by suggesting relevant related work. Current approaches for this task rely primarily on the text of the papers and the citation network. In this paper, we propose to exploit an additional source of information, namely research knowledge graphs (KG) that interlink research papers based on mentioned scientific concepts. Our experimental results demonstrate that the combination of information from research KGs with existing state-of-the-art approaches is beneficial. Experimental results are presented for the STM-KG (STM: Science, Technology, Medicine), which is an automatically populated knowledge graph based on the scientific concepts extracted from papers of ten domains. The proposed approach outperforms the state of the art with a mean average precision of 20.6% (+0.8) for the top-50 retrieved results.