 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDrive-QA- Automated Generation of Multiple-Choice Questions for Autonomous Driving Datasets Using Large Vision-Language Models
Mar 20, 2025In autonomous driving, open-ended question answering often suffers from unreliable evaluations because freeform responses require either complex metrics or subjective human judgment. To address this challenge, we introduce AutoDrive-QA, an automatic pipeline that converts existing driving QA datasets (including DriveLM, NuScenes-QA, and LingoQA) into a structured multiple-choice question (MCQ) format. This benchmark systematically assesses perception, prediction, and planning tasks, providing a standardized and objective evaluation framework. AutoDrive-QA employs an automated pipeline that leverages large language models (LLMs) to generate high-quality, contextually relevant distractors based on domain-specific error patterns commonly found in autonomous driving scenarios. To evaluate both general capabilities and generalization performance, we test the benchmark on three public datasets and conduct zero-shot experiments on an unseen dataset. The zero-shot evaluations reveal that GPT-4V leads with 69.57% accuracy -- achieving 74.94% in Perception, 65.33% in Prediction, and 68.45% in Planning -- demonstrating that while all models excel in Perception, they struggle in Prediction. Consequently, AutoDrive-QA establishes a rigorous, unbiased standard for integrating and evaluating different vision-language models across various autonomous driving datasets, thereby improving generalization in this field. We release all the codes in the AutoDrive-QA GitHub Repository.
SOD-YOLOv8 -- Enhancing YOLOv8 for Small Object Detection in Traffic Scenes
Aug 08, 2024



Object detection as part of computer vision can be crucial for traffic management, emergency response, autonomous vehicles, and smart cities. Despite significant advances in object detection, detecting small objects in images captured by distant cameras remains challenging due to their size, distance from the camera, varied shapes, and cluttered backgrounds. To address these challenges, we propose Small Object Detection YOLOv8 (SOD-YOLOv8), a novel model specifically designed for scenarios involving numerous small objects. Inspired by Efficient Generalized Feature Pyramid Networks (GFPN), we enhance multi-path fusion within YOLOv8 to integrate features across different levels, preserving details from shallower layers and improving small object detection accuracy. Also, A fourth detection layer is added to leverage high-resolution spatial information effectively. The Efficient Multi-Scale Attention Module (EMA) in the C2f-EMA module enhances feature extraction by redistributing weights and prioritizing relevant features. We introduce Powerful-IoU (PIoU) as a replacement for CIoU, focusing on moderate-quality anchor boxes and adding a penalty based on differences between predicted and ground truth bounding box corners. This approach simplifies calculations, speeds up convergence, and enhances detection accuracy. SOD-YOLOv8 significantly improves small object detection, surpassing widely used models in various metrics, without substantially increasing computational cost or latency compared to YOLOv8s. Specifically, it increases recall from 40.1\% to 43.9\%, precision from 51.2\% to 53.9\%, $\text{mAP}_{0.5}$ from 40.6\% to 45.1\%, and $\text{mAP}_{0.5:0.95}$ from 24\% to 26.6\%. In dynamic real-world traffic scenes, SOD-YOLOv8 demonstrated notable improvements in diverse conditions, proving its reliability and effectiveness in detecting small objects even in challenging environments.
NLP-enabled trajectory map-matching in urban road networks using transformer sequence-to-sequence model
Apr 18, 2024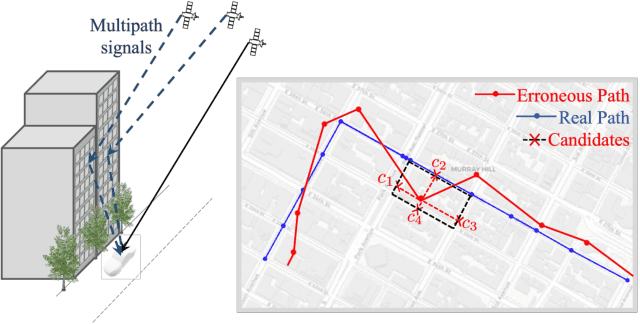
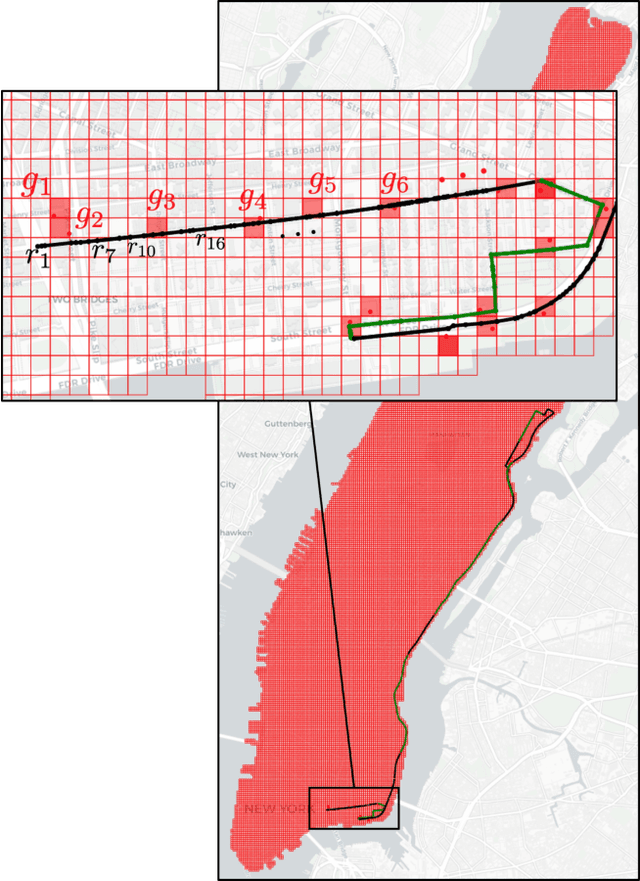
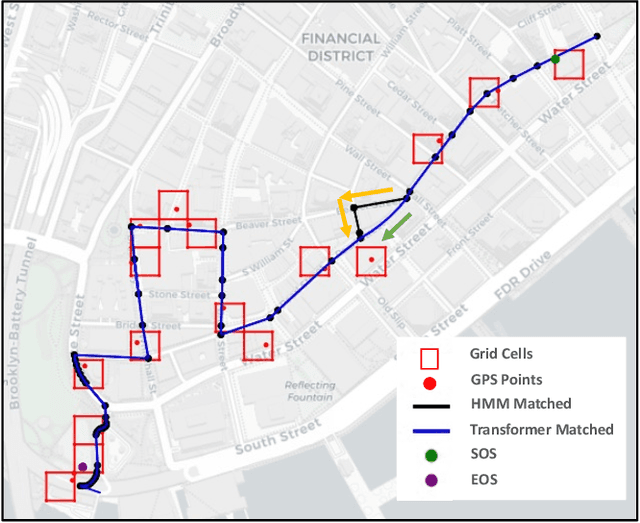
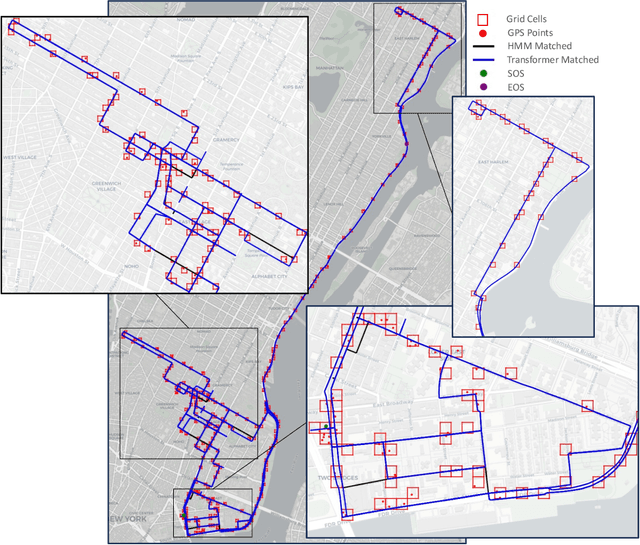
Large-scale geolocation telematics data acquired from connected vehicles has the potential to significantly enhance mobility infrastructures and operational systems within smart cities. To effectively utilize this data, it is essential to accurately match the geolocation data to the road segments. However, this matching is often not trivial due to the low sampling rate and errors exacerbated by multipath effects in urban environments. Traditionally, statistical modeling techniques such as Hidden-Markov models incorporating domain knowledge into the matching process have been extensively used for map-matching tasks. However, rule-based map-matching tasks are noise-sensitive and inefficient in processing large-scale trajectory data. Deep learning techniques directly learn the relationship between observed data and road networks from the data, often without the need for hand-crafted rules or domain knowledge. This renders them an efficient approach for map-matching large-scale datasets and makes them more robust to the noise. This paper introduces a sequence-to-sequence deep-learning model, specifically the transformer-based encoder-decoder model, to perform as a surrogate for map-matching algorithms. The encoder-decoder architecture initially encodes the series of noisy GPS points into a representation that automatically captures autoregressive behavior and spatial correlations between GPS points. Subsequently, the decoder associates data points with the road network features and thus transforms these representations into a sequence of road segments. The model is trained and evaluated using GPS traces collected in Manhattan, New York. Achieving an accuracy of 76%, transformer-based encoder-decoder models extensively employed in natural language processing presented a promising performance for translating noisy GPS data to the navigated routes in urban road networks.