 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Mycotoxin Contamination in Irish Oats Using Deep and Transfer Learning
Dec 23, 2025Mycotoxin contamination poses a significant risk to cereal crop quality, food safety, and agricultural productivity. Accurate prediction of mycotoxin levels can support early intervention strategies and reduce economic losses. This study investigates the use of neural networks and transfer learning models to predict mycotoxin contamination in Irish oat crops as a multi-response prediction task. Our dataset comprises oat samples collected in Ireland, containing a mix of environmental, agronomic, and geographical predictors. Five modelling approaches were evaluated: a baseline multilayer perceptron (MLP), an MLP with pre-training, and three transfer learning models; TabPFN, TabNet, and FT-Transformer. Model performance was evaluated using regression (RMSE, $R^2$) and classification (AUC, F1) metrics, with results reported per toxin and on average. Additionally, permutation-based variable importance analysis was conducted to identify the most influential predictors across both prediction tasks. The transfer learning approach TabPFN provided the overall best performance, followed by the baseline MLP. Our variable importance analysis revealed that weather history patterns in the 90-day pre-harvest period were the most important predictors, alongside seed moisture content.
Predicting BVD Re-emergence in Irish Cattle From Highly Imbalanced Herd-Level Data Using Machine Learning Algorithms
Apr 17, 2025



Bovine Viral Diarrhoea (BVD) has been the focus of a successful eradication programme in Ireland, with the herd-level prevalence declining from 11.3% in 2013 to just 0.2% in 2023. As the country moves toward BVD freedom, the development of predictive models for targeted surveillance becomes increasingly important to mitigate the risk of disease re-emergence. In this study, we evaluate the performance of a range of machine learning algorithms, including binary classification and anomaly detection techniques, for predicting BVD-positive herds using highly imbalanced herd-level data. We conduct an extensive simulation study to assess model performance across varying sample sizes and class imbalance ratios, incorporating resampling, class weighting, and appropriate evaluation metrics (sensitivity, positive predictive value, F1-score and AUC values). Random forests and XGBoost models consistently outperformed other methods, with the random forest model achieving the highest sensitivity and AUC across scenarios, including real-world prediction of 2023 herd status, correctly identifying 219 of 250 positive herds while halving the number of herds that require compared to a blanket-testing strategy.
Generative AI-based data augmentation for improved bioacoustic classification in noisy environments
Dec 02, 2024



1. Obtaining data to train robust artificial intelligence (AI)-based models for species classification can be challenging, particularly for rare species. Data augmentation can boost classification accuracy by increasing the diversity of training data and is cheaper to obtain than expert-labelled data. However, many classic image-based augmentation techniques are not suitable for audio spectrograms. 2. We investigate two generative AI models as data augmentation tools to synthesise spectrograms and supplement audio data: Auxiliary Classifier Generative Adversarial Networks (ACGAN) and Denoising Diffusion Probabilistic Models (DDPMs). The latter performed particularly well in terms of both realism of generated spectrograms and accuracy in a resulting classification task. 3. Alongside these new approaches, we present a new audio data set of 640 hours of bird calls from wind farm sites in Ireland, approximately 800 samples of which have been labelled by experts. Wind farm data are particularly challenging for classification models given the background wind and turbine noise. 4. Training an ensemble of classification models on real and synthetic data combined gave 92.6% accuracy (and 90.5% with just the real data) when compared with highly confident BirdNET predictions. 5. Our approach can be used to augment acoustic signals for more species and other land-use types, and has the potential to bring about a step-change in our capacity to develop reliable AI-based detection of rare species. Our code is available at https://github.com/gibbona1/ SpectrogramGenAI.
Bayesian Causal Forests for Longitudinal Data: Assessing the Impact of Part-Time Work on Growth in High School Mathematics Achievement
Jul 16, 2024



Modelling growth in student achievement is a significant challenge in the field of education. Understanding how interventions or experiences such as part-time work can influence this growth is also important. Traditional methods like difference-in-differences are effective for estimating causal effects from longitudinal data. Meanwhile, Bayesian non-parametric methods have recently become popular for estimating causal effects from single time point observational studies. However, there remains a scarcity of methods capable of combining the strengths of these two approaches to flexibly estimate heterogeneous causal effects from longitudinal data. Motivated by two waves of data from the High School Longitudinal Study, the NCES' most recent longitudinal study which tracks a representative sample of over 20,000 students in the US, our study introduces a longitudinal extension of Bayesian Causal Forests. This model allows for the flexible identification of both individual growth in mathematical ability and the effects of participation in part-time work. Simulation studies demonstrate the predictive performance and reliable uncertainty quantification of the proposed model. Results reveal the negative impact of part time work for most students, but hint at potential benefits for those students with an initially low sense of school belonging. Clear signs of a widening achievement gap between students with high and low academic achievement are also identified. Potential policy implications are discussed, along with promising areas for future research.
Machine Learning Applied to the Detection of Mycotoxin in Food: A Review
Apr 23, 2024



Mycotoxins, toxic secondary metabolites produced by certain fungi, pose significant threats to global food safety and public health. These compounds can contaminate a variety of crops, leading to economic losses and health risks to both humans and animals. Traditional lab analysis methods for mycotoxin detection can be time-consuming and may not always be suitable for large-scale screenings. However, in recent years, machine learning (ML) methods have gained popularity for use in the detection of mycotoxins and in the food safety industry in general, due to their accurate and timely predictions. We provide a systematic review on some of the recent ML applications for detecting/predicting the presence of mycotoxin on a variety of food ingredients, highlighting their advantages, challenges, and potential for future advancements. We address the need for reproducibility and transparency in ML research through open access to data and code. An observation from our findings is the frequent lack of detailed reporting on hyperparameters in many studies as well as a lack of open source code, which raises concerns about the reproducibility and optimisation of the ML models used. The findings reveal that while the majority of studies predominantly utilised neural networks for mycotoxin detection, there was a notable diversity in the types of neural network architectures employed, with convolutional neural networks being the most popular.
SERT: A Transfomer Based Model for Spatio-Temporal Sensor Data with Missing Values for Environmental Monitoring
Jun 09, 2023Environmental monitoring is crucial to our understanding of climate change, biodiversity loss and pollution. The availability of large-scale spatio-temporal data from sources such as sensors and satellites allows us to develop sophisticated models for forecasting and understanding key drivers. However, the data collected from sensors often contain missing values due to faulty equipment or maintenance issues. The missing values rarely occur simultaneously leading to data that are multivariate misaligned sparse time series. We propose two models that are capable of performing multivariate spatio-temporal forecasting while handling missing data naturally without the need for imputation. The first model is a transformer-based model, which we name SERT (Spatio-temporal Encoder Representations from Transformers). The second is a simpler model named SST-ANN (Sparse Spatio-Temporal Artificial Neural Network) which is capable of providing interpretable results. We conduct extensive experiments on two different datasets for multivariate spatio-temporal forecasting and show that our models have competitive or superior performance to those at the state-of-the-art.
Bayesian Causal Forests for Multivariate Outcomes: Application to Irish Data From an International Large Scale Education Assessment
Mar 08, 2023


Bayesian Causal Forests (BCF) is a causal inference machine learning model based on a highly flexible non-parametric regression and classification tool called Bayesian Additive Regression Trees (BART). Motivated by data from the Trends in International Mathematics and Science Study (TIMSS), which includes data on student achievement in both mathematics and science, we present a multivariate extension of the BCF algorithm. With the help of simulation studies we show that our approach can accurately estimate causal effects for multiple outcomes subject to the same treatment. We also apply our model to Irish data from TIMSS 2019. Our findings reveal the positive effects of having access to a study desk at home (Mathematics ATE 95% CI: [0.20, 11.67]) while also highlighting the negative consequences of students often feeling hungry at school (Mathematics ATE 95% CI: [-11.15, -2.78] , Science ATE 95% CI: [-10.82,-1.72]) or often being absent (Mathematics ATE 95% CI: [-12.47, -1.55]).
NEAL: An open-source tool for audio annotation
Dec 08, 2022Passive acoustic monitoring is used widely in ecology, biodiversity, and conservation studies. Data sets collected via acoustic monitoring are often extremely large and built to be processed automatically using Artificial Intelligence and Machine learning models, which aim to replicate the work of domain experts. These models, being supervised learning algorithms, need to be trained on high quality annotations produced by experts. Since the experts are often resource-limited, a cost-effective process for annotating audio is needed to get maximal use out of the data. We present an open-source interactive audio data annotation tool, NEAL (Nature+Energy Audio Labeller). Built using R and the associated Shiny framework, the tool provides a reactive environment where users can quickly annotate audio files and adjust settings that automatically change the corresponding elements of the user interface. The app has been designed with the goal of having both expert birders and citizen scientists contribute to acoustic annotation projects. The popularity and flexibility of R programming in bioacoustics means that the Shiny app can be modified for other bird labelling data sets, or even to generic audio labelling tasks. We demonstrate the app by labelling data collected from wind farm sites across Ireland.
Review of Clustering Methods for Functional Data
Oct 03, 2022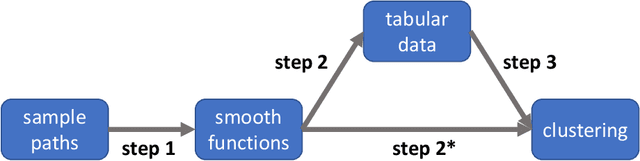

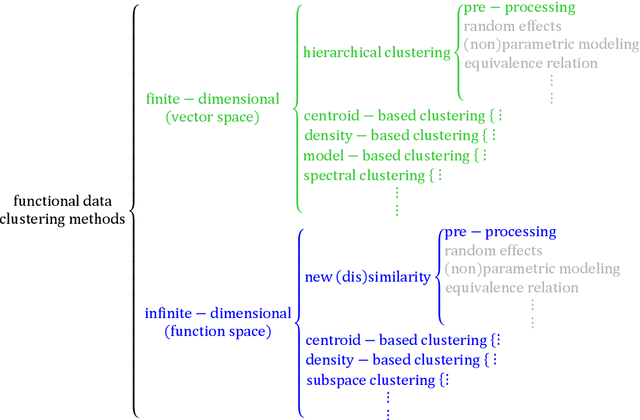
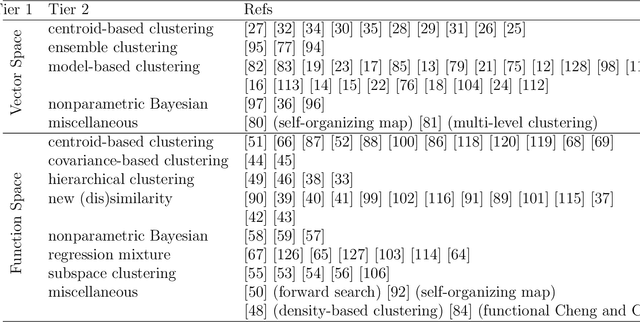
Functional data clustering is to identify heterogeneous morphological patterns in the continuous functions underlying the discrete measurements/observations. Application of functional data clustering has appeared in many publications across various fields of sciences, including but not limited to biology, (bio)chemistry, engineering, environmental science, medical science, psychology, social science, etc. The phenomenal growth of the application of functional data clustering indicates the urgent need for a systematic approach to develop efficient clustering methods and scalable algorithmic implementations. On the other hand, there is abundant literature on the cluster analysis of time series, trajectory data, spatio-temporal data, etc., which are all related to functional data. Therefore, an overarching structure of existing functional data clustering methods will enable the cross-pollination of ideas across various research fields. We here conduct a comprehensive review of original clustering methods for functional data. We propose a systematic taxonomy that explores the connections and differences among the existing functional data clustering methods and relates them to the conventional multivariate clustering methods. The structure of the taxonomy is built on three main attributes of a functional data clustering method and therefore is more reliable than existing categorizations. The review aims to bridge the gap between the functional data analysis community and the clustering community and to generate new principles for functional data clustering.
Hierarchical Embedded Bayesian Additive Regression Trees
Apr 14, 2022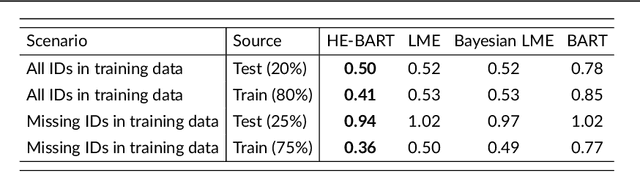
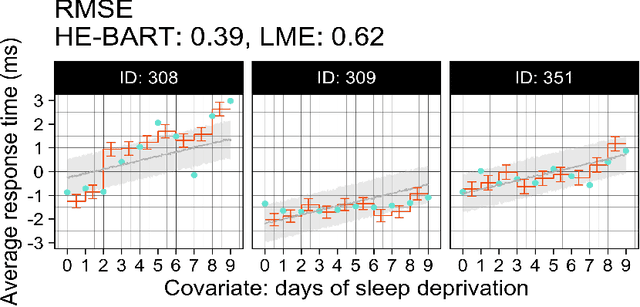
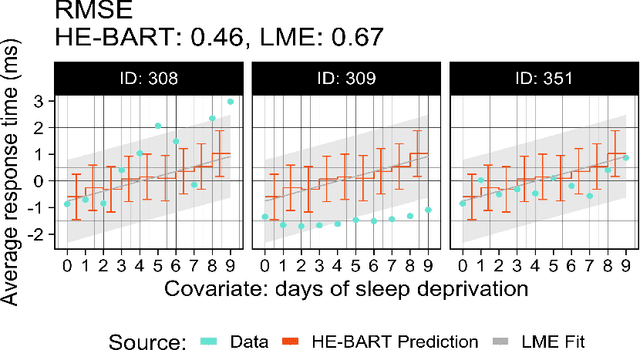
We propose a simple yet powerful extension of Bayesian Additive Regression Trees which we name Hierarchical Embedded BART (HE-BART). The model allows for random effects to be included at the terminal node level of a set of regression trees, making HE-BART a non-parametric alternative to mixed effects models which avoids the need for the user to specify the structure of the random effects in the model, whilst maintaining the prediction and uncertainty calibration properties of standard BART. Using simulated and real-world examples, we demonstrate that this new extension yields superior predictions for many of the standard mixed effects models' example data sets, and yet still provides consistent estimates of the random effect variances. In a future version of this paper, we outline its use in larger, more advanced data sets and structures.