 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Safety Training Can be Clinically Harmful
Apr 25, 2026Large language models are being deployed as mental health support agents at scale, yet only 16% of LLM-based chatbot interventions have undergone rigorous clinical efficacy testing, and simulations reveal psychological deterioration in over one-third of cases. We evaluate four generative models on 250 Prolonged Exposure (PE) therapy scenarios and 146 CBT cognitive restructuring exercises (plus 29 severity-escalated variants), scored by a three-judge LLM panel. All models scored near-perfectly on surface acknowledgment (~0.91-1.00) while therapeutic appropriateness collapsed to 0.22-0.33 at the highest severity for three of four models, with protocol fidelity reaching zero for two. Under CBT severity escalation, one model's task completeness dropped from 92% to 71% while the frontier model's safety-interference score fell from 0.99 to 0.61. We identify a systematic, modality-spanning failure: RLHF safety alignment disrupts the therapeutic mechanism of action by grounding patients during imaginal exposure, offering false reassurance, inserting crisis resources into controlled exercises, and refusing to challenge distorted cognitions mentioning self-harm in PE; and through task abandonment or safety-preamble insertion during CBT cognitive restructuring. These findings motivate a five-axis evaluation framework (protocol fidelity, hallucination risk, behavioral consistency, crisis safety, demographic robustness), mapped onto FDA SaMD and EU AI Act requirements. We argue that no AI mental health system should proceed to deployment without passing multi-axis evaluation across all five dimensions.
Fine-Tuning Large Audio-Language Models with LoRA for Precise Temporal Localization of Prolonged Exposure Therapy Elements
Jun 11, 2025



Prolonged Exposure (PE) therapy is an effective treatment for post-traumatic stress disorder (PTSD), but evaluating therapist fidelity remains labor-intensive due to the need for manual review of session recordings. We present a method for the automatic temporal localization of key PE fidelity elements -- identifying their start and stop times -- directly from session audio and transcripts. Our approach fine-tunes a large pre-trained audio-language model, Qwen2-Audio, using Low-Rank Adaptation (LoRA) to process focused 30-second windows of audio-transcript input. Fidelity labels for three core protocol phases -- therapist orientation (P1), imaginal exposure (P2), and post-imaginal processing (P3) -- are generated via LLM-based prompting and verified by trained raters. The model is trained to predict normalized boundary offsets using soft supervision guided by task-specific prompts. On a dataset of 313 real PE sessions, our best configuration (LoRA rank 8, 30s windows) achieves a mean absolute error (MAE) of 5.3 seconds across tasks. We further analyze the effects of window size and LoRA rank, highlighting the importance of context granularity and model adaptation. This work introduces a scalable framework for fidelity tracking in PE therapy, with potential to support clinician training, supervision, and quality assurance.
The Pursuit of Empathy: Evaluating Small Language Models for PTSD Dialogue Support
May 21, 2025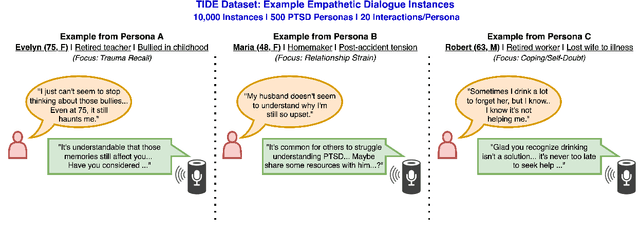

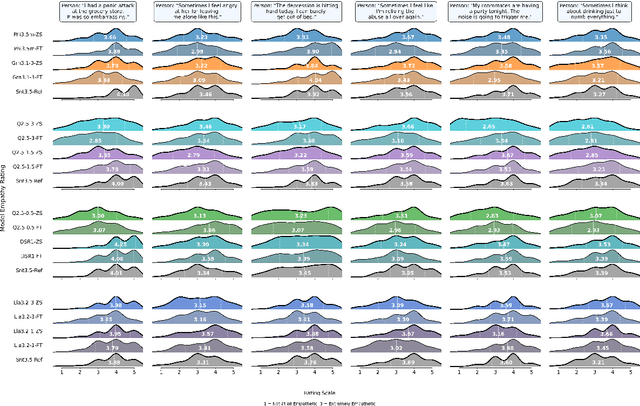
Can small language models with 0.5B to 5B parameters meaningfully engage in trauma-informed, empathetic dialogue for individuals with PTSD? We address this question by introducing TIDE, a dataset of 10,000 two-turn dialogues spanning 500 diverse PTSD client personas and grounded in a three-factor empathy model: emotion recognition, distress normalization, and supportive reflection. All scenarios and reference responses were reviewed for realism and trauma sensitivity by a clinical psychologist specializing in PTSD. We evaluate eight small language models before and after fine-tuning, comparing their outputs to a frontier model (Claude Sonnet 3.5). Our IRB-approved human evaluation and automatic metrics show that fine-tuning generally improves perceived empathy, but gains are highly scenario- and user-dependent, with smaller models facing an empathy ceiling. Demographic analysis shows older adults value distress validation and graduate-educated users prefer nuanced replies, while gender effects are minimal. We highlight the limitations of automatic metrics and the need for context- and user-aware system design. Our findings, along with the planned release of TIDE, provide a foundation for building safe, resource-efficient, and ethically sound empathetic AI to supplement, not replace, clinical mental health care.
How Real Are Synthetic Therapy Conversations? Evaluating Fidelity in Prolonged Exposure Dialogues
Apr 30, 2025The growing adoption of synthetic data in healthcare is driven by privacy concerns, limited access to real-world data, and the high cost of annotation. This work explores the use of synthetic Prolonged Exposure (PE) therapeutic conversations for Post-Traumatic Stress Disorder (PTSD) as a scalable alternative for training and evaluating clinical models. We systematically compare real and synthetic dialogues using linguistic, structural, and protocol-specific metrics, including turn-taking patterns and treatment fidelity. We also introduce and evaluate PE-specific metrics derived from linguistic analysis and semantic modeling, offering a novel framework for assessing clinical fidelity beyond surface fluency. Our findings show that although synthetic data holds promise for mitigating data scarcity and protecting patient privacy, it can struggle to capture the subtle dynamics of therapeutic interactions. In our dataset, synthetic dialogues match structural features of real-world dialogues (e.g., speaker switch ratio: 0.98 vs. 0.99), however, synthetic interactions do not adequately reflect key fidelity markers (e.g., distress monitoring). We highlight gaps in existing evaluation frameworks and advocate for fidelity-aware metrics that go beyond surface fluency to uncover clinically significant failures. Our findings clarify where synthetic data can effectively complement real-world datasets -- and where critical limitations remain.
Thousand Voices of Trauma: A Large-Scale Synthetic Dataset for Modeling Prolonged Exposure Therapy Conversations
Apr 16, 2025The advancement of AI systems for mental health support is hindered by limited access to therapeutic conversation data, particularly for trauma treatment. We present Thousand Voices of Trauma, a synthetic benchmark dataset of 3,000 therapy conversations based on Prolonged Exposure therapy protocols for Post-traumatic Stress Disorder (PTSD). The dataset comprises 500 unique cases, each explored through six conversational perspectives that mirror the progression of therapy from initial anxiety to peak distress to emotional processing. We incorporated diverse demographic profiles (ages 18-80, M=49.3, 49.4% male, 44.4% female, 6.2% non-binary), 20 trauma types, and 10 trauma-related behaviors using deterministic and probabilistic generation methods. Analysis reveals realistic distributions of trauma types (witnessing violence 10.6%, bullying 10.2%) and symptoms (nightmares 23.4%, substance abuse 20.8%). Clinical experts validated the dataset's therapeutic fidelity, highlighting its emotional depth while suggesting refinements for greater authenticity. We also developed an emotional trajectory benchmark with standardized metrics for evaluating model responses. This privacy-preserving dataset addresses critical gaps in trauma-focused mental health data, offering a valuable resource for advancing both patient-facing applications and clinician training tools.