 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstant Learning: Parallel Deep Neural Networks and Convolutional Bootstrapping
May 21, 2016

Although deep neural networks (DNN) are able to scale with direct advances in computational power (e.g., memory and processing speed), they are not well suited to exploit the recent trends for parallel architectures. In particular, gradient descent is a sequential process and the resulting serial dependencies mean that DNN training cannot be parallelized effectively. Here, we show that a DNN may be replicated over a massive parallel architecture and used to provide a cumulative sampling of local solution space which results in rapid and robust learning. We introduce a complimentary convolutional bootstrapping approach that enhances performance of the parallel architecture further. Our parallelized convolutional bootstrapping DNN out-performs an identical fully-trained traditional DNN after only a single iteration of training.
Hierarchical Conflict Propagation: Sequence Learning in a Recurrent Deep Neural Network
Feb 25, 2016

Recurrent neural networks (RNN) are capable of learning to encode and exploit activation history over an arbitrary timescale. However, in practice, state of the art gradient descent based training methods are known to suffer from difficulties in learning long term dependencies. Here, we describe a novel training method that involves concurrent parallel cloned networks, each sharing the same weights, each trained at different stimulus phase and each maintaining independent activation histories. Training proceeds by recursively performing batch-updates over the parallel clones as activation history is progressively increased. This allows conflicts to propagate hierarchically from short-term contexts towards longer-term contexts until they are resolved. We illustrate the parallel clones method and hierarchical conflict propagation with a character-level deep RNN tasked with memorizing a paragraph of Moby Dick (by Herman Melville).
Qualitative Projection Using Deep Neural Networks
Oct 28, 2015


Deep neural networks (DNN) abstract by demodulating the output of linear filters. In this article, we refine this definition of abstraction to show that the inputs of a DNN are abstracted with respect to the filters. Or, to restate, the abstraction is qualified by the filters. This leads us to introduce the notion of qualitative projection. We use qualitative projection to abstract MNIST hand-written digits with respect to the various dogs, horses, planes and cars of the CIFAR dataset. We then classify the MNIST digits according to the magnitude of their dogness, horseness, planeness and carness qualities, illustrating the generality of qualitative projection.
Uniform Learning in a Deep Neural Network via "Oddball" Stochastic Gradient Descent
Oct 08, 2015

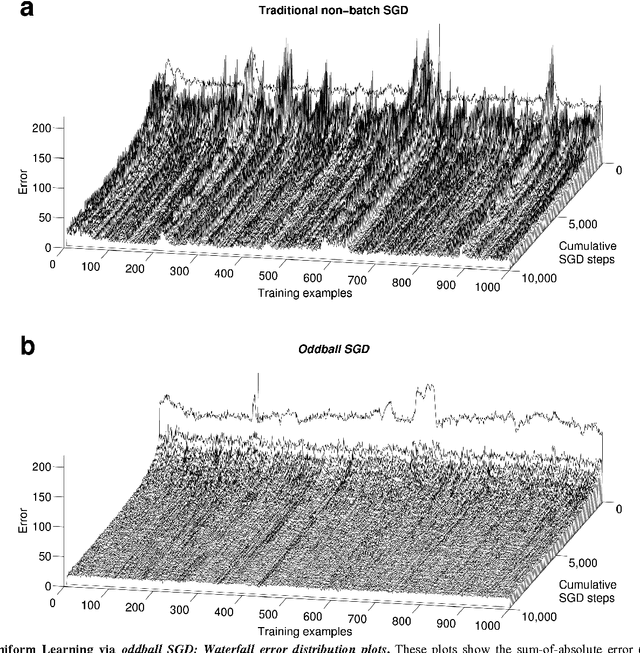
When training deep neural networks, it is typically assumed that the training examples are uniformly difficult to learn. Or, to restate, it is assumed that the training error will be uniformly distributed across the training examples. Based on these assumptions, each training example is used an equal number of times. However, this assumption may not be valid in many cases. "Oddball SGD" (novelty-driven stochastic gradient descent) was recently introduced to drive training probabilistically according to the error distribution - training frequency is proportional to training error magnitude. In this article, using a deep neural network to encode a video, we show that oddball SGD can be used to enforce uniform error across the training set.
On-the-Fly Learning in a Perpetual Learning Machine
Sep 29, 2015


Despite the promise of brain-inspired machine learning, deep neural networks (DNN) have frustratingly failed to bridge the deceptively large gap between learning and memory. Here, we introduce a Perpetual Learning Machine; a new type of DNN that is capable of brain-like dynamic 'on the fly' learning because it exists in a self-supervised state of Perpetual Stochastic Gradient Descent. Thus, we provide the means to unify learning and memory within a machine learning framework. We also explore the elegant duality of abstraction and synthesis: the Yin and Yang of deep learning.
"Oddball SGD": Novelty Driven Stochastic Gradient Descent for Training Deep Neural Networks
Sep 18, 2015
Stochastic Gradient Descent (SGD) is arguably the most popular of the machine learning methods applied to training deep neural networks (DNN) today. It has recently been demonstrated that SGD can be statistically biased so that certain elements of the training set are learned more rapidly than others. In this article, we place SGD into a feedback loop whereby the probability of selection is proportional to error magnitude. This provides a novelty-driven oddball SGD process that learns more rapidly than traditional SGD by prioritising those elements of the training set with the largest novelty (error). In our DNN example, oddball SGD trains some 50x faster than regular SGD.
Taming the ReLU with Parallel Dither in a Deep Neural Network
Sep 17, 2015


Rectified Linear Units (ReLU) seem to have displaced traditional 'smooth' nonlinearities as activation-function-du-jour in many - but not all - deep neural network (DNN) applications. However, nobody seems to know why. In this article, we argue that ReLU are useful because they are ideal demodulators - this helps them perform fast abstract learning. However, this fast learning comes at the expense of serious nonlinear distortion products - decoy features. We show that Parallel Dither acts to suppress the decoy features, preventing overfitting and leaving the true features cleanly demodulated for rapid, reliable learning.
Use it or Lose it: Selective Memory and Forgetting in a Perpetual Learning Machine
Sep 10, 2015


In a recent article we described a new type of deep neural network - a Perpetual Learning Machine (PLM) - which is capable of learning 'on the fly' like a brain by existing in a state of Perpetual Stochastic Gradient Descent (PSGD). Here, by simulating the process of practice, we demonstrate both selective memory and selective forgetting when we introduce statistical recall biases during PSGD. Frequently recalled memories are remembered, whilst memories recalled rarely are forgotten. This results in a 'use it or lose it' stimulus driven memory process that is similar to human memory.
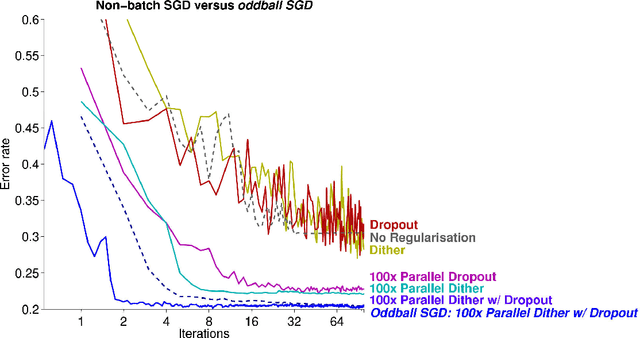
Parallel Dither and Dropout for Regularising Deep Neural Networks
Aug 28, 2015

Effective regularisation during training can mean the difference between success and failure for deep neural networks. Recently, dither has been suggested as alternative to dropout for regularisation during batch-averaged stochastic gradient descent (SGD). In this article, we show that these methods fail without batch averaging and we introduce a new, parallel regularisation method that may be used without batch averaging. Our results for parallel-regularised non-batch-SGD are substantially better than what is possible with batch-SGD. Furthermore, our results demonstrate that dither and dropout are complimentary.
Dither is Better than Dropout for Regularising Deep Neural Networks
Aug 26, 2015

Regularisation of deep neural networks (DNN) during training is critical to performance. By far the most popular method is known as dropout. Here, cast through the prism of signal processing theory, we compare and contrast the regularisation effects of dropout with those of dither. We illustrate some serious inherent limitations of dropout and demonstrate that dither provides a more effective regulariser.