 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Vocal Sentiment Analysis
May 19, 2019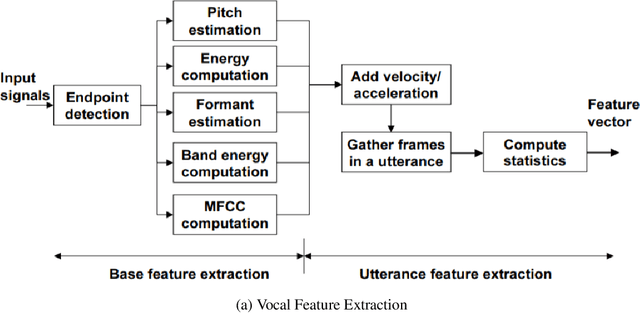
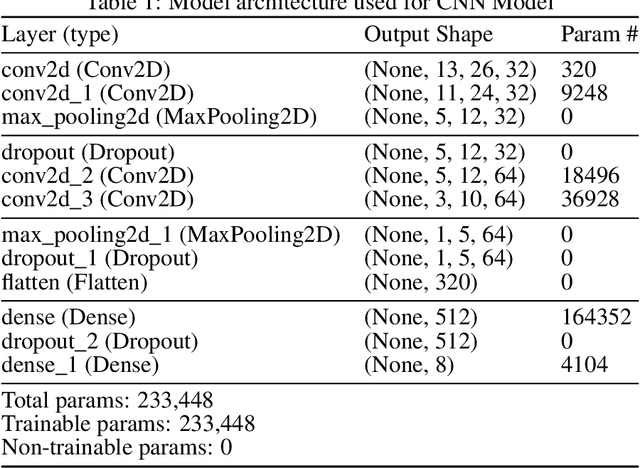
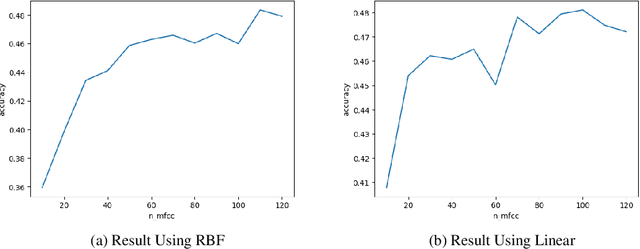
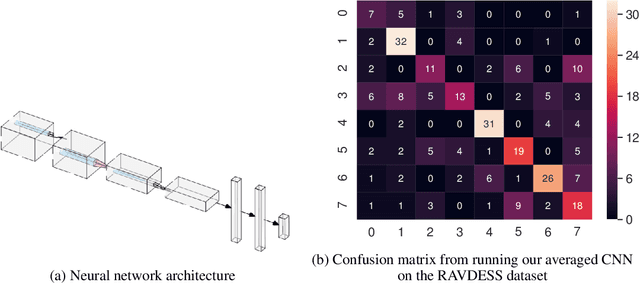
In this paper, we use several techniques with conventional vocal feature extraction (MFCC, STFT), along with deep-learning approaches such as CNN, and also context-level analysis, by providing the textual data, and combining different approaches for improved emotion-level classification. We explore models that have not been tested to gauge the difference in performance and accuracy. We apply hyperparameter sweeps and data augmentation to improve performance. Finally, we see if a real-time approach is feasible, and can be readily integrated into existing systems.
Tensor-Based Backpropagation in Neural Networks with Non-Sequential Input
Jul 13, 2017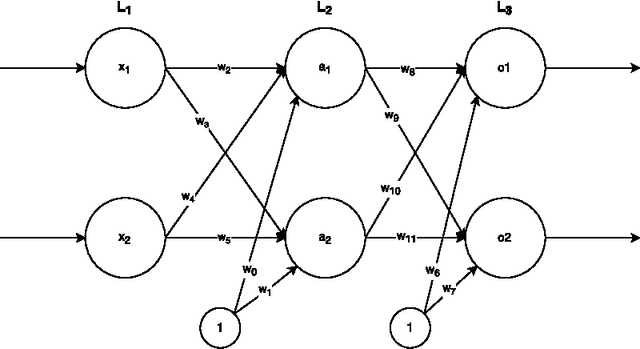
Neural networks have been able to achieve groundbreaking accuracy at tasks conventionally considered only doable by humans. Using stochastic gradient descent, optimization in many dimensions is made possible, albeit at a relatively high computational cost. By splitting training data into batches, networks can be distributed and trained vastly more efficiently and with minimal accuracy loss. We have explored the mathematics behind efficiently implementing tensor-based batch backpropagation algorithms. A common approach to batch training is iterating over batch items individually. Explicitly using tensor operations to backpropagate allows training to be performed non-linearly, increasing computational efficiency.