 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE360: Semantic Edit in 360$^\circ$ Panoramas via Hierarchical Data Construction
Dec 23, 2025While instruction-based image editing is emerging, extending it to 360$^\circ$ panoramas introduces additional challenges. Existing methods often produce implausible results in both equirectangular projections (ERP) and perspective views. To address these limitations, we propose SE360, a novel framework for multi-condition guided object editing in 360$^\circ$ panoramas. At its core is a novel coarse-to-fine autonomous data generation pipeline without manual intervention. This pipeline leverages a Vision-Language Model (VLM) and adaptive projection adjustment for hierarchical analysis, ensuring the holistic segmentation of objects and their physical context. The resulting data pairs are both semantically meaningful and geometrically consistent, even when sourced from unlabeled panoramas. Furthermore, we introduce a cost-effective, two-stage data refinement strategy to improve data realism and mitigate model overfitting to erase artifacts. Based on the constructed dataset, we train a Transformer-based diffusion model to allow flexible object editing guided by text, mask, or reference image in 360$^\circ$ panoramas. Our experiments demonstrate that our method outperforms existing methods in both visual quality and semantic accuracy.
Deep Portrait Delighting
Apr 01, 2022

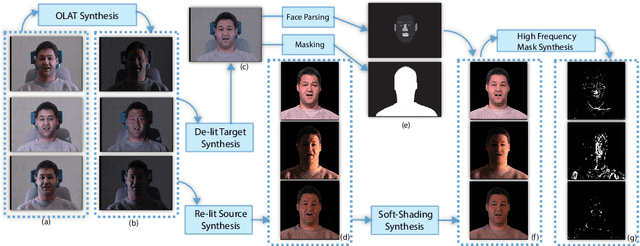
We present a deep neural network for removing undesirable shading features from an unconstrained portrait image, recovering the underlying texture. Our training scheme incorporates three regularization strategies: masked loss, to emphasize high-frequency shading features; soft-shadow loss, which improves sensitivity to subtle changes in lighting; and shading-offset estimation, to supervise separation of shading and texture. Our method demonstrates improved delighting quality and generalization when compared with the state-of-the-art. We further demonstrate how our delighting method can enhance the performance of light-sensitive computer vision tasks such as face relighting and semantic parsing, allowing them to handle extreme lighting conditions.
Casual 6-DoF: free-viewpoint panorama using a handheld 360 camera
Mar 31, 2022

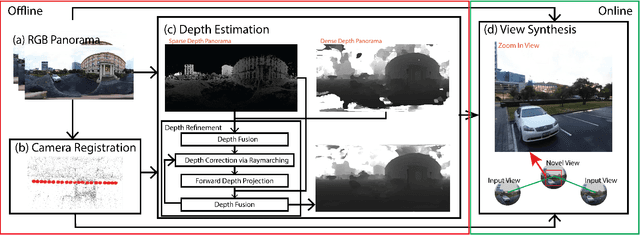
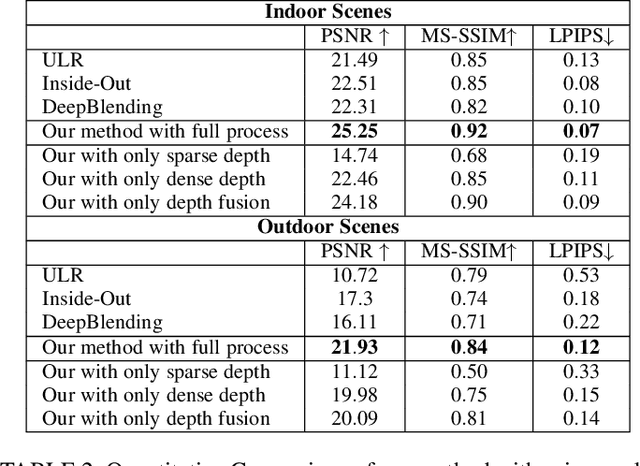
Six degrees-of-freedom (6-DoF) video provides telepresence by enabling users to move around in the captured scene with a wide field of regard. Compared to methods requiring sophisticated camera setups, the image-based rendering method based on photogrammetry can work with images captured with any poses, which is more suitable for casual users. However, existing image-based rendering methods are based on perspective images. When used to reconstruct 6-DoF views, it often requires capturing hundreds of images, making data capture a tedious and time-consuming process. In contrast to traditional perspective images, 360{\deg} images capture the entire surrounding view in a single shot, thus, providing a faster capturing process for 6-DoF view reconstruction. This paper presents a novel method to provide 6-DoF experiences over a wide area using an unstructured collection of 360{\deg} panoramas captured by a conventional 360{\deg} camera. Our method consists of 360{\deg} data capturing, novel depth estimation to produce a high-quality spherical depth panorama, and high-fidelity free-viewpoint generation. We compared our method against state-of-the-art methods, using data captured in various environments. Our method shows better visual quality and robustness in the tested scenes.