 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratising Clinical AI through Dataset Condensation for Classical Clinical Models
Mar 10, 2026Dataset condensation (DC) learns a compact synthetic dataset that enables models to match the performance of full-data training, prioritising utility over distributional fidelity. While typically explored for computational efficiency, DC also holds promise for healthcare data democratisation, especially when paired with differential privacy, allowing synthetic data to serve as a safe alternative to real records. However, existing DC methods rely on differentiable neural networks, limiting their compatibility with widely used clinical models such as decision trees and Cox regression. We address this gap using a differentially private, zero-order optimisation framework that extends DC to non-differentiable models using only function evaluations. Empirical results across six datasets, including both classification and survival tasks, show that the proposed method produces condensed datasets that preserve model utility while providing effective differential privacy guarantees - enabling model-agnostic data sharing for clinical prediction tasks without exposing sensitive patient information.
Deep Reinforcement Learning for Multi-class Imbalanced Training
May 24, 2022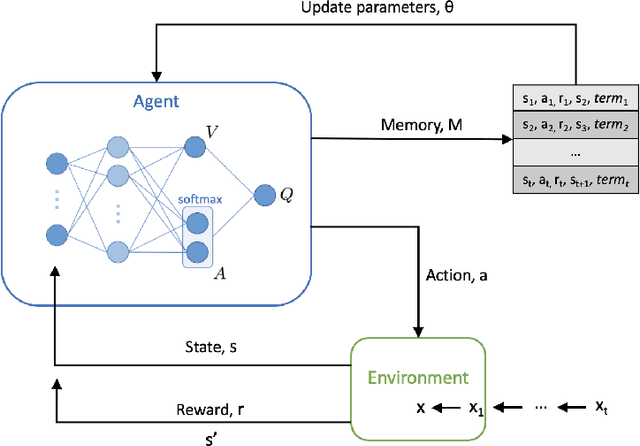
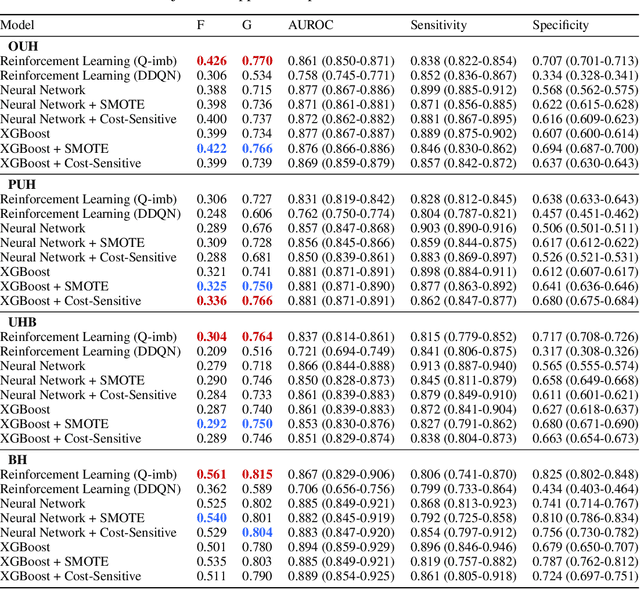
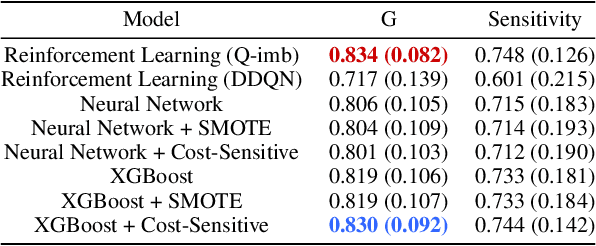
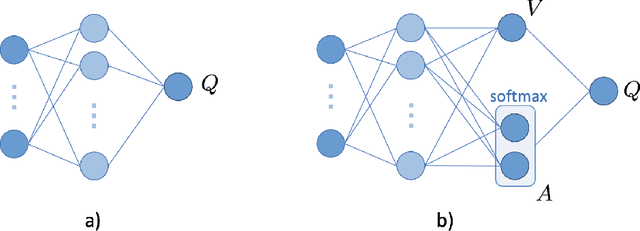
With the rapid growth of memory and computing power, datasets are becoming increasingly complex and imbalanced. This is especially severe in the context of clinical data, where there may be one rare event for many cases in the majority class. We introduce an imbalanced classification framework, based on reinforcement learning, for training extremely imbalanced data sets, and extend it for use in multi-class settings. We combine dueling and double deep Q-learning architectures, and formulate a custom reward function and episode-training procedure, specifically with the added capability of handling multi-class imbalanced training. Using real-world clinical case studies, we demonstrate that our proposed framework outperforms current state-of-the-art imbalanced learning methods, achieving more fair and balanced classification, while also significantly improving the prediction of minority classes.