 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector of Locally-Aggregated Word Embeddings (VLAWE): A Novel Document-level Representation
Mar 24, 2019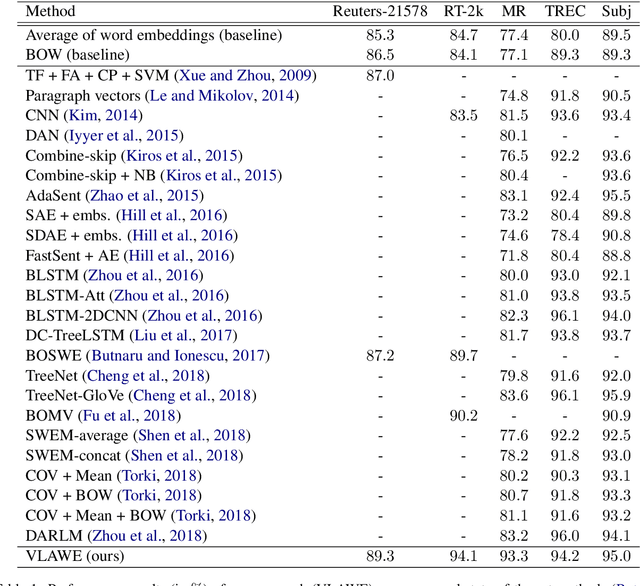

In this paper, we propose a novel representation for text documents based on aggregating word embedding vectors into document embeddings. Our approach is inspired by the Vector of Locally-Aggregated Descriptors used for image representation, and it works as follows. First, the word embeddings gathered from a collection of documents are clustered by k-means in order to learn a codebook of semnatically-related word embeddings. Each word embedding is then associated to its nearest cluster centroid (codeword). The Vector of Locally-Aggregated Word Embeddings (VLAWE) representation of a document is then computed by accumulating the differences between each codeword vector and each word vector (from the document) associated to the respective codeword. We plug the VLAWE representation, which is learned in an unsupervised manner, into a classifier and show that it is useful for a diverse set of text classification tasks. We compare our approach with a broad range of recent state-of-the-art methods, demonstrating the effectiveness of our approach. Furthermore, we obtain a considerable improvement on the Movie Review data set, reporting an accuracy of 93.3%, which represents an absolute gain of 10% over the state-of-the-art approach.
MOROCO: The Moldavian and Romanian Dialectal Corpus
Jan 19, 2019
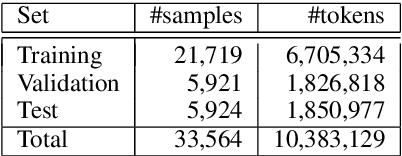
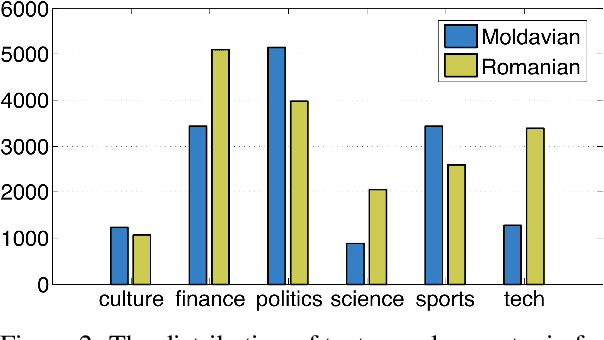
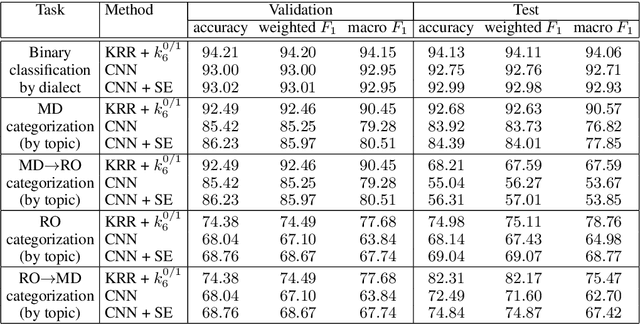
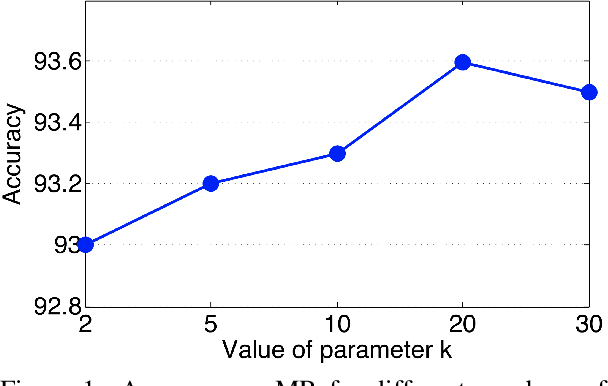
In this work, we introduce the MOldavian and ROmanian Dialectal COrpus (MOROCO), which is freely available for download at https://github.com/butnaruandrei/MOROCO. The corpus contains 33564 samples of text (with over 10 million tokens) collected from the news domain. The samples belong to one of the following six topics: culture, finance, politics, science, sports and tech. The data set is divided into 21719 samples for training, 5921 samples for validation and another 5924 samples for testing. For each sample, we provide corresponding dialectal and category labels. This allows us to perform empirical studies on several classification tasks such as (i) binary discrimination of Moldavian versus Romanian text samples, (ii) intra-dialect multi-class categorization by topic and (iii) cross-dialect multi-class categorization by topic. We perform experiments using a shallow approach based on string kernels, as well as a novel deep approach based on character-level convolutional neural networks containing Squeeze-and-Excitation blocks. We also present and analyze the most discriminative features of our best performing model, before and after named entity removal.
Transductive Learning with String Kernels for Cross-Domain Text Classification
Nov 02, 2018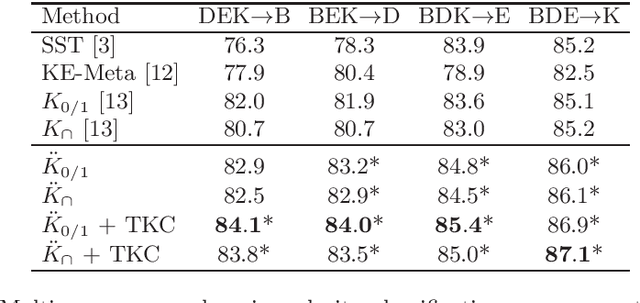
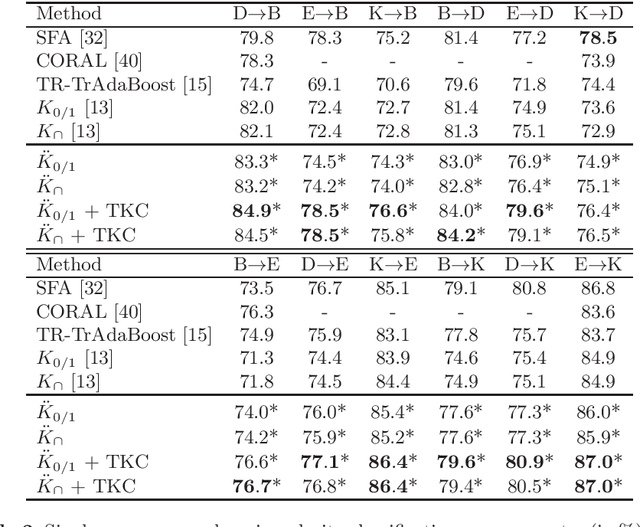
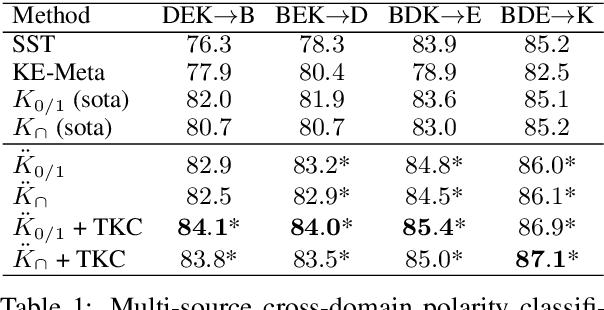
For many text classification tasks, there is a major problem posed by the lack of labeled data in a target domain. Although classifiers for a target domain can be trained on labeled text data from a related source domain, the accuracy of such classifiers is usually lower in the cross-domain setting. Recently, string kernels have obtained state-of-the-art results in various text classification tasks such as native language identification or automatic essay scoring. Moreover, classifiers based on string kernels have been found to be robust to the distribution gap between different domains. In this paper, we formally describe an algorithm composed of two simple yet effective transductive learning approaches to further improve the results of string kernels in cross-domain settings. By adapting string kernels to the test set without using the ground-truth test labels, we report significantly better accuracy rates in cross-domain English polarity classification.
Improving the results of string kernels in sentiment analysis and Arabic dialect identification by adapting them to your test set
Aug 31, 2018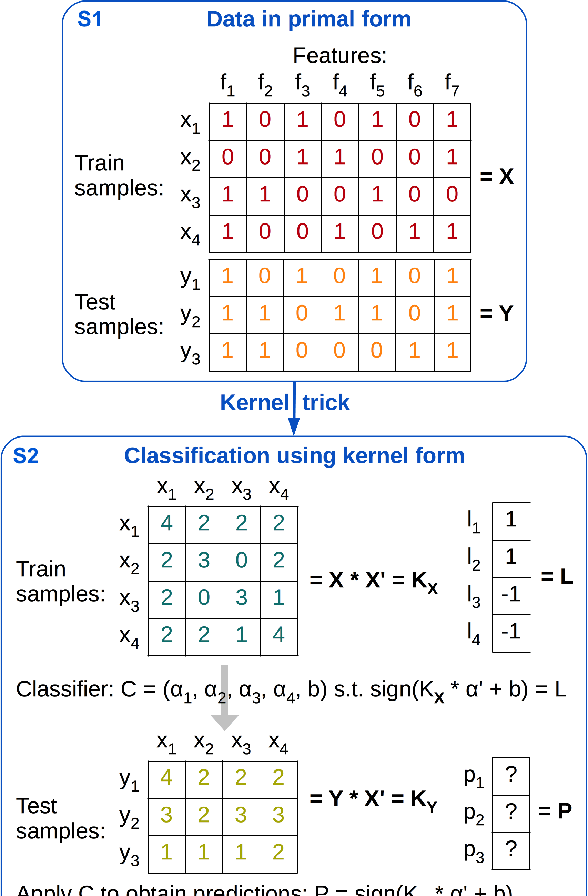
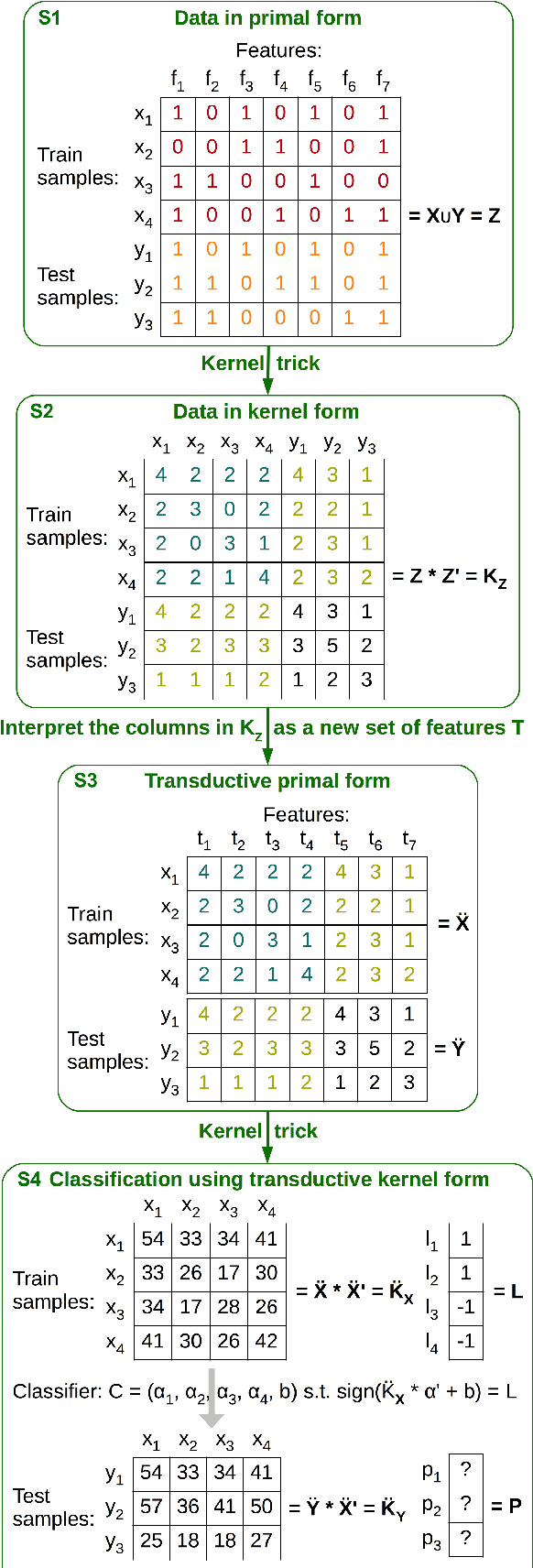

Recently, string kernels have obtained state-of-the-art results in various text classification tasks such as Arabic dialect identification or native language identification. In this paper, we apply two simple yet effective transductive learning approaches to further improve the results of string kernels. The first approach is based on interpreting the pairwise string kernel similarities between samples in the training set and samples in the test set as features. Our second approach is a simple self-training method based on two learning iterations. In the first iteration, a classifier is trained on the training set and tested on the test set, as usual. In the second iteration, a number of test samples (to which the classifier associated higher confidence scores) are added to the training set for another round of training. However, the ground-truth labels of the added test samples are not necessary. Instead, we use the labels predicted by the classifier in the first training iteration. By adapting string kernels to the test set, we report significantly better accuracy rates in English polarity classification and Arabic dialect identification.
UnibucKernel Reloaded: First Place in Arabic Dialect Identification for the Second Year in a Row
Jul 28, 2018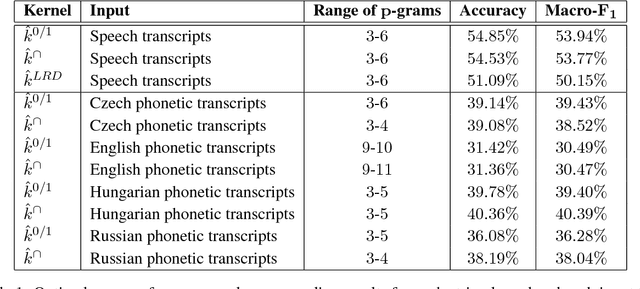
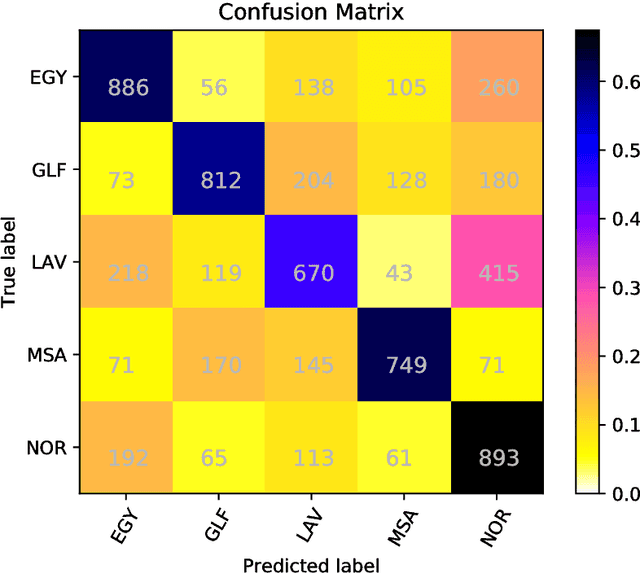
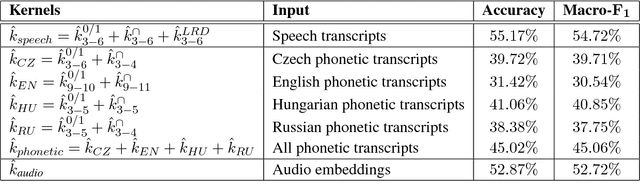

We present a machine learning approach that ranked on the first place in the Arabic Dialect Identification (ADI) Closed Shared Tasks of the 2018 VarDial Evaluation Campaign. The proposed approach combines several kernels using multiple kernel learning. While most of our kernels are based on character p-grams (also known as n-grams) extracted from speech or phonetic transcripts, we also use a kernel based on dialectal embeddings generated from audio recordings by the organizers. In the learning stage, we independently employ Kernel Discriminant Analysis (KDA) and Kernel Ridge Regression (KRR). Preliminary experiments indicate that KRR provides better classification results. Our approach is shallow and simple, but the empirical results obtained in the 2018 ADI Closed Shared Task prove that it achieves the best performance. Furthermore, our top macro-F1 score (58.92%) is significantly better than the second best score (57.59%) in the 2018 ADI Shared Task, according to the statistical significance test performed by the organizers. Nevertheless, we obtain even better post-competition results (a macro-F1 score of 62.28%) using the audio embeddings released by the organizers after the competition. With a very similar approach (that did not include phonetic features), we also ranked first in the ADI Closed Shared Tasks of the 2017 VarDial Evaluation Campaign, surpassing the second best method by 4.62%. We therefore conclude that our multiple kernel learning method is the best approach to date for Arabic dialect identification.
Automated essay scoring with string kernels and word embeddings
Jul 06, 2018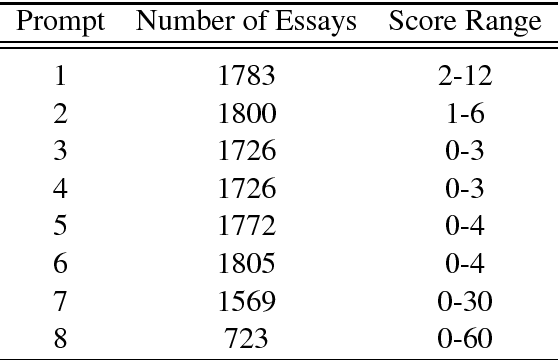
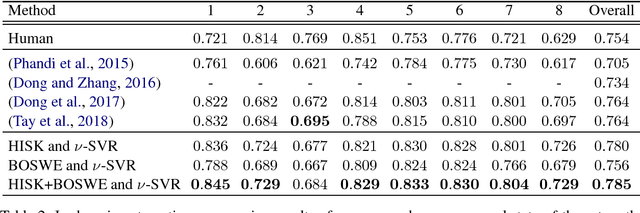
In this work, we present an approach based on combining string kernels and word embeddings for automatic essay scoring. String kernels capture the similarity among strings based on counting common character n-grams, which are a low-level yet powerful type of feature, demonstrating state-of-the-art results in various text classification tasks such as Arabic dialect identification or native language identification. To our best knowledge, we are the first to apply string kernels to automatically score essays. We are also the first to combine them with a high-level semantic feature representation, namely the bag-of-super-word-embeddings. We report the best performance on the Automated Student Assessment Prize data set, in both in-domain and cross-domain settings, surpassing recent state-of-the-art deep learning approaches.
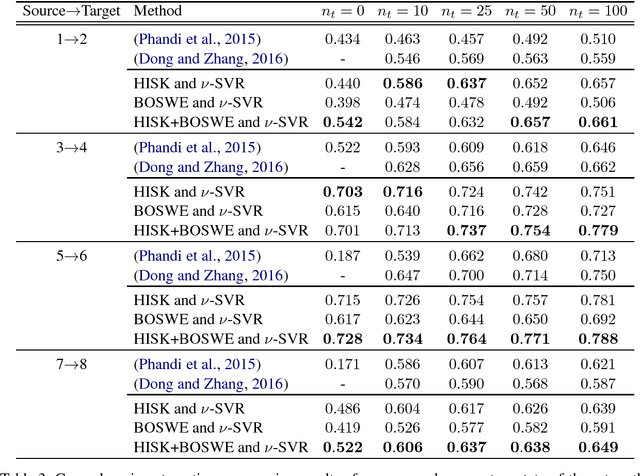
UnibucKernel: A kernel-based learning method for complex word identification
May 22, 2018
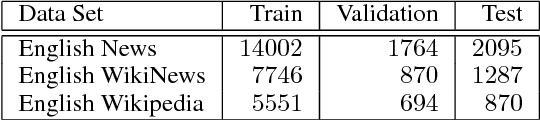
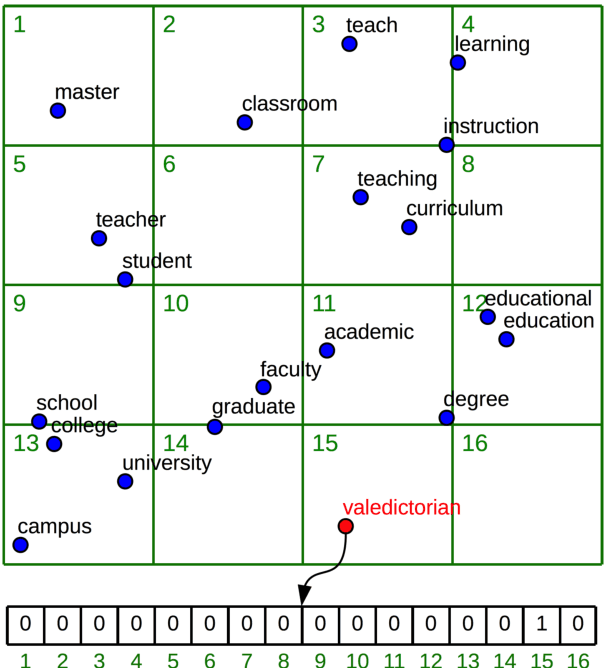

In this paper, we present a kernel-based learning approach for the 2018 Complex Word Identification (CWI) Shared Task. Our approach is based on combining multiple low-level features, such as character n-grams, with high-level semantic features that are either automatically learned using word embeddings or extracted from a lexical knowledge base, namely WordNet. After feature extraction, we employ a kernel method for the learning phase. The feature matrix is first transformed into a normalized kernel matrix. For the binary classification task (simple versus complex), we employ Support Vector Machines. For the regression task, in which we have to predict the complexity level of a word (a word is more complex if it is labeled as complex by more annotators), we employ v-Support Vector Regression. We applied our approach only on the three English data sets containing documents from Wikipedia, WikiNews and News domains. Our best result during the competition was the third place on the English Wikipedia data set. However, in this paper, we also report better post-competition results.
From Image to Text Classification: A Novel Approach based on Clustering Word Embeddings
Jul 25, 2017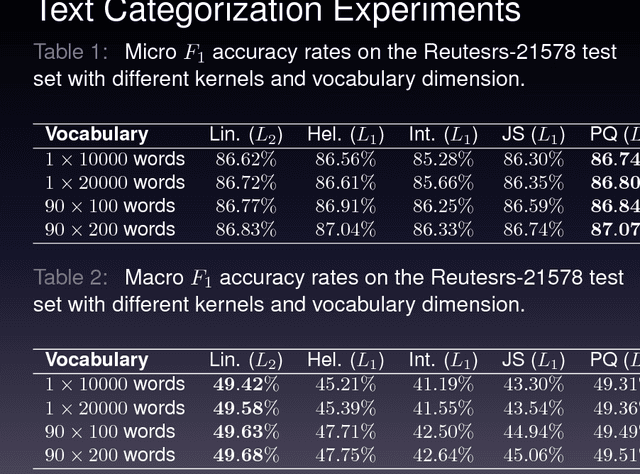
In this paper, we propose a novel approach for text classification based on clustering word embeddings, inspired by the bag of visual words model, which is widely used in computer vision. After each word in a collection of documents is represented as word vector using a pre-trained word embeddings model, a k-means algorithm is applied on the word vectors in order to obtain a fixed-size set of clusters. The centroid of each cluster is interpreted as a super word embedding that embodies all the semantically related word vectors in a certain region of the embedding space. Every embedded word in the collection of documents is then assigned to the nearest cluster centroid. In the end, each document is represented as a bag of super word embeddings by computing the frequency of each super word embedding in the respective document. We also diverge from the idea of building a single vocabulary for the entire collection of documents, and propose to build class-specific vocabularies for better performance. Using this kind of representation, we report results on two text mining tasks, namely text categorization by topic and polarity classification. On both tasks, our model yields better performance than the standard bag of words.
ShotgunWSD: An unsupervised algorithm for global word sense disambiguation inspired by DNA sequencing
Jul 25, 2017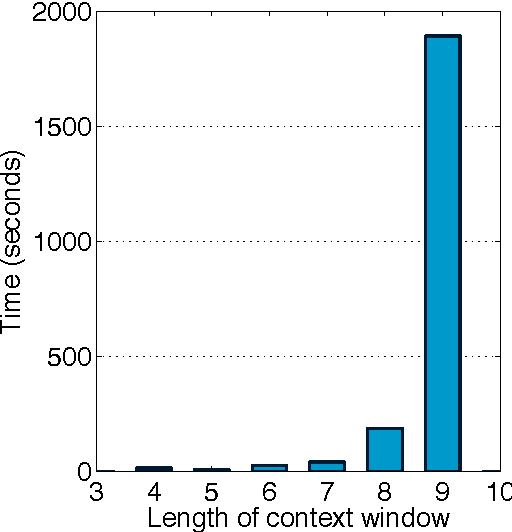
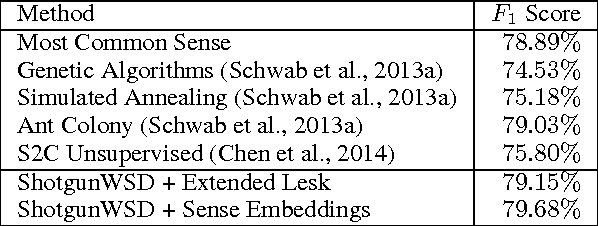
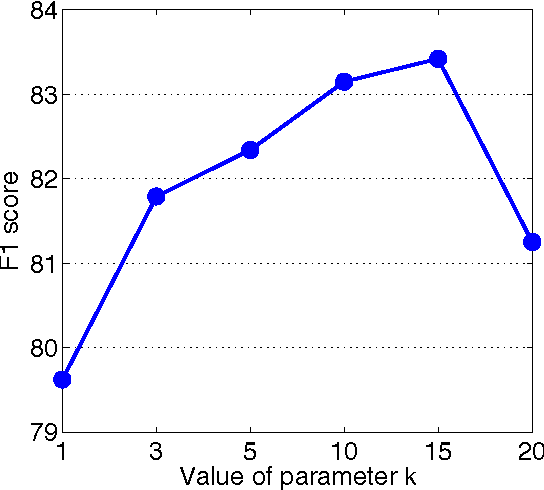

In this paper, we present a novel unsupervised algorithm for word sense disambiguation (WSD) at the document level. Our algorithm is inspired by a widely-used approach in the field of genetics for whole genome sequencing, known as the Shotgun sequencing technique. The proposed WSD algorithm is based on three main steps. First, a brute-force WSD algorithm is applied to short context windows (up to 10 words) selected from the document in order to generate a short list of likely sense configurations for each window. In the second step, these local sense configurations are assembled into longer composite configurations based on suffix and prefix matching. The resulted configurations are ranked by their length, and the sense of each word is chosen based on a voting scheme that considers only the top k configurations in which the word appears. We compare our algorithm with other state-of-the-art unsupervised WSD algorithms and demonstrate better performance, sometimes by a very large margin. We also show that our algorithm can yield better performance than the Most Common Sense (MCS) baseline on one data set. Moreover, our algorithm has a very small number of parameters, is robust to parameter tuning, and, unlike other bio-inspired methods, it gives a deterministic solution (it does not involve random choices).