 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Chunking with Transformers for Image-Based Spacecraft Guidance and Control
Sep 04, 2025We present an imitation learning approach for spacecraft guidance, navigation, and control(GNC) that achieves high performance from limited data. Using only 100 expert demonstrations, equivalent to 6,300 environment interactions, our method, which implements Action Chunking with Transformers (ACT), learns a control policy that maps visual and state observations to thrust and torque commands. ACT generates smoother, more consistent trajectories than a meta-reinforcement learning (meta-RL) baseline trained with 40 million interactions. We evaluate ACT on a rendezvous task: in-orbit docking with the International Space Station (ISS). We show that our approach achieves greater accuracy, smoother control, and greater sample efficiency.
VisualEnv: visual Gym environments with Blender
Dec 01, 2021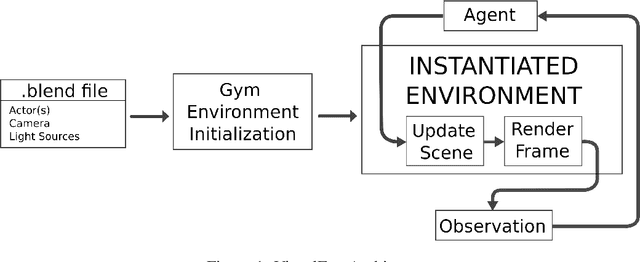



In this paper VisualEnv, a new tool for creating visual environment for reinforcement learning is introduced. It is the product of an integration of an open-source modelling and rendering software, Blender, and a python module used to generate environment model for simulation, OpenAI Gym. VisualEnv allows the user to create custom environments with photorealistic rendering capabilities and full integration with python. The framework is described and tested on a series of example problems that showcase its features for training reinforcement learning agents.
Reinforcement Meta-Learning for Interception of Maneuvering Exoatmospheric Targets with Parasitic Attitude Loop
Apr 18, 2020



We use Reinforcement Meta-Learning to optimize an adaptive integrated guidance, navigation, and control system suitable for exoatmospheric interception of a maneuvering target. The system maps observations consisting of strapdown seeker angles and rate gyro measurements directly to thruster on-off commands. Using a high fidelity six degree-of-freedom simulator, we demonstrate that the optimized policy can adapt to parasitic effects including seeker angle measurement lag, thruster control lag, the parasitic attitude loop resulting from scale factor errors and Gaussian noise on angle and rotational velocity measurements, and a time varying center of mass caused by fuel consumption and slosh. Importantly, the optimized policy gives good performance over a wide range of challenging target maneuvers. Unlike previous work that enhances range observability by inducing line of sight oscillations, our system is optimized to use only measurements available from the seeker and rate gyros. Through extensive Monte Carlo simulation of randomized exoatmospheric interception scenarios, we demonstrate that the optimized policy gives performance close to that of augmented proportional navigation with perfect knowledge of the full engagement state. The optimized system is computationally efficient and requires minimal memory, and should be compatible with today's flight processors.