 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel Region of Interest Extraction Layer for Instance Segmentation
Apr 28, 2020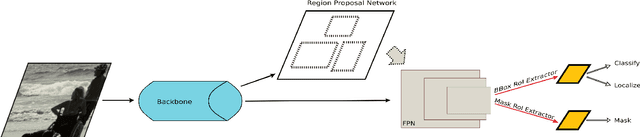
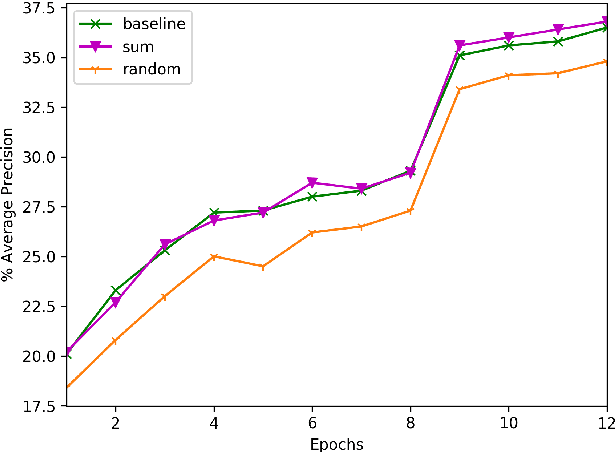
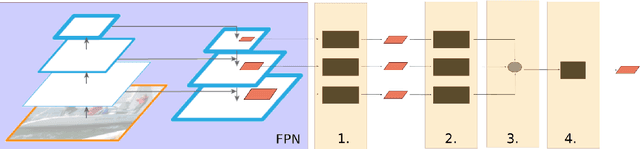
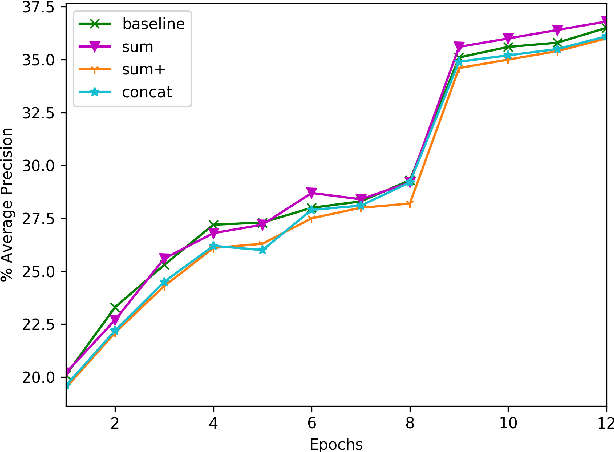
Given the wide diffusion of deep neural network architectures for computer vision tasks, several new applications are nowadays more and more feasible. Among them, a particular attention has been recently given to instance segmentation, by exploiting the results achievable by two-stage networks (such as Mask R-CNN or Faster R-CNN), derived from R-CNN. In these complex architectures, a crucial role is played by the Region of Interest (RoI) extraction layer, devoted to extract a coherent subset of features from a single Feature Pyramid Network (FPN) layer attached on top of a backbone. This paper is motivated by the need to overcome to the limitations of existing RoI extractors which select only one (the best) layer from FPN. Our intuition is that all the layers of FPN retain useful information. Therefore, the proposed layer (called Generic RoI Extractor - GRoIE) introduces non-local building blocks and attention mechanisms to boost the performance. A comprehensive ablation study at component level is conducted to find the best set of algorithms and parameters for the GRoIE layer. Moreover, GRoIE can be integrated seamlessly with every two-stage architecture for both object detection and instance segmentation tasks. Therefore, the improvements brought by the use of GRoIE in different state-of-the-art architectures are also evaluated. The proposed layer leads up to gain a 1.1% AP on bounding box detection and 1.7% AP on instance segmentation. The code is publicly available on GitHub repository at https://github.com/IMPLabUniPr/mmdetection-groie
Adversarial Training for Aspect-Based Sentiment Analysis with BERT
Jan 31, 2020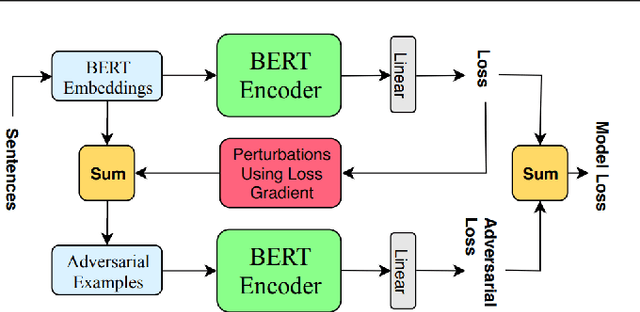
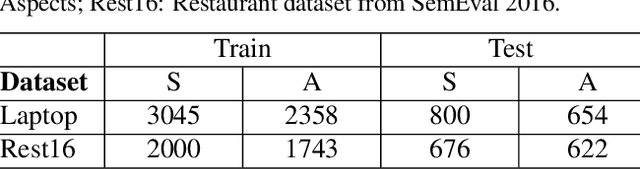
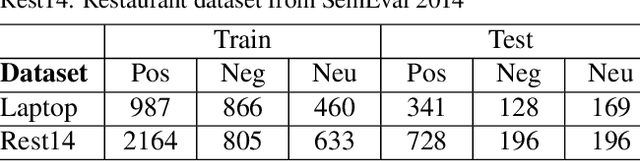
Aspect-Based Sentiment Analysis (ABSA) deals with the extraction of sentiments and their targets. Collecting labeled data for this task in order to help neural networks generalize better can be laborious and time-consuming. As an alternative, similar data to the real-world examples can be produced artificially through an adversarial process which is carried out in the embedding space. Although these examples are not real sentences, they have been shown to act as a regularization method which can make neural networks more robust. In this work, we apply adversarial training, which was put forward by Goodfellow et al. (2014), to the post-trained BERT (BERT-PT) language model proposed by Xu et al. (2019) on the two major tasks of Aspect Extraction and Aspect Sentiment Classification in sentiment analysis. After improving the results of post-trained BERT by an ablation study, we propose a novel architecture called BERT Adversarial Training (BAT) to utilize adversarial training in ABSA. The proposed model outperforms post-trained BERT in both tasks. To the best of our knowledge, this is the first study on the application of adversarial training in ABSA.
MetalGAN: Multi-Domain Label-Less Image Synthesis Using cGANs and Meta-Learning
Dec 05, 2019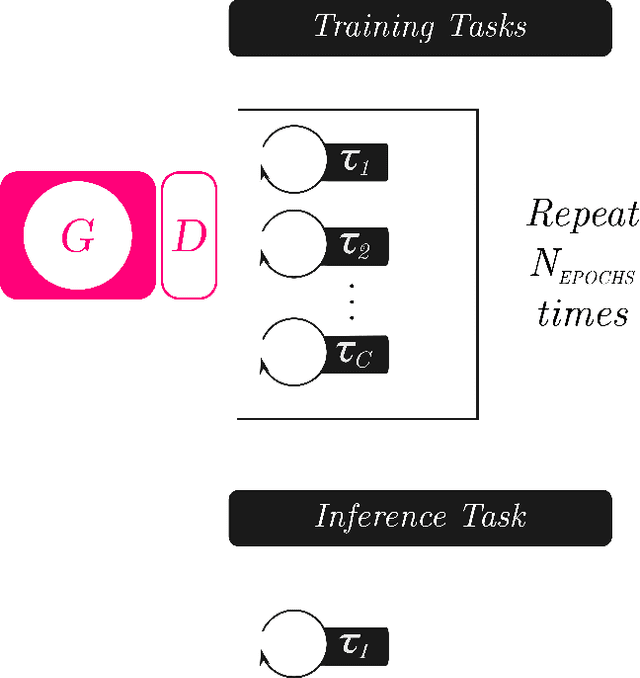
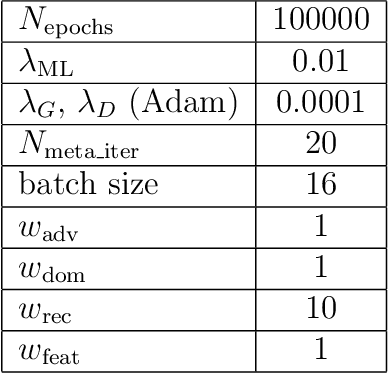
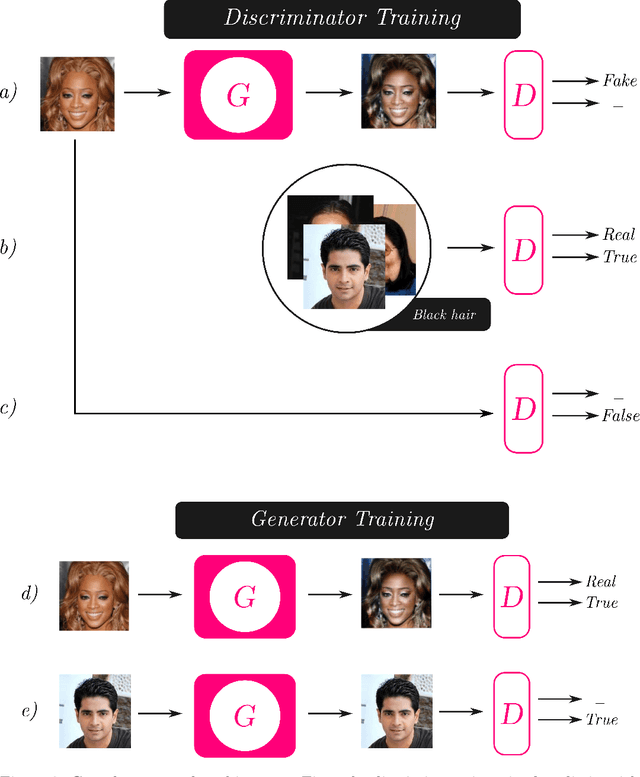
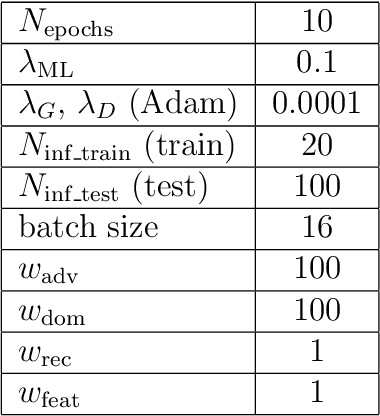
Image synthesis is currently one of the most addressed image processing topic in computer vision and deep learning fields of study. Researchers have tackled this problem focusing their efforts on its several challenging problems, e.g. image quality and size, domain and pose changing, architecture of the networks, and so on. Above all, producing images belonging to different domains by using a single architecture is a very relevant goal for image generation. In fact, a single multi-domain network would allow greater flexibility and robustness in the image synthesis task than other approaches. This paper proposes a novel architecture and a training algorithm, which are able to produce multi-domain outputs using a single network. A small portion of a dataset is intentionally used, and there are no hard-coded labels (or classes). This is achieved by combining a conditional Generative Adversarial Network (cGAN) for image generation and a Meta-Learning algorithm for domain switch, and we called our approach MetalGAN. The approach has proved to be appropriate for solving the multi-domain problem and it is validated on facial attribute transfer, using CelebA dataset.
MetalGAN: a Cluster-based Adaptive Training for Few-Shot Adversarial Colorization
Sep 17, 2019
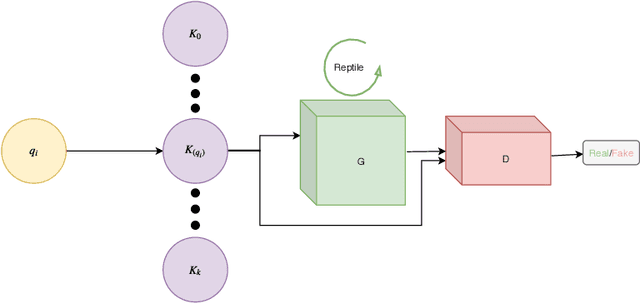


In recent years, the majority of works on deep-learning-based image colorization have focused on how to make a good use of the enormous datasets currently available. What about when the data at disposal are scarce? The main objective of this work is to prove that a network can be trained and can provide excellent colorization results even without a large quantity of data. The adopted approach is a mixed one, which uses an adversarial method for the actual colorization, and a meta-learning technique to enhance the generator model. Also, a clusterization a-priori of the training dataset ensures a task-oriented division useful for meta-learning, and at the same time reduces the per-step number of images. This paper describes in detail the method and its main motivations, and a discussion of results and future developments is provided.
Genetic Algorithms for the Optimization of Diffusion Parameters in Content-Based Image Retrieval
Aug 19, 2019
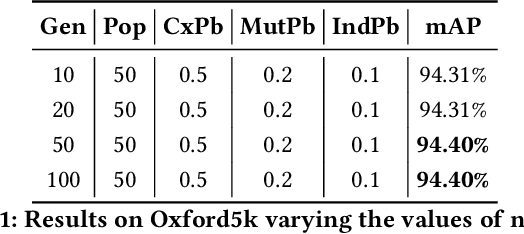
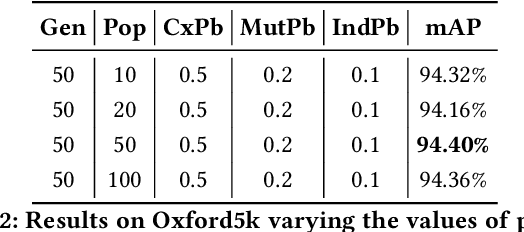
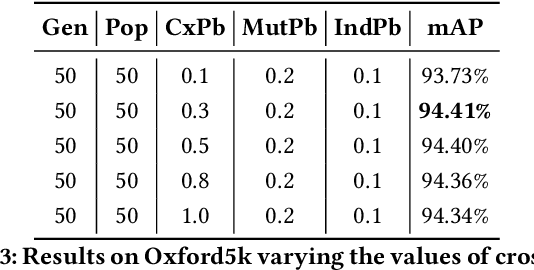
Several computer vision and artificial intelligence projects are nowadays exploiting the manifold data distribution using, e.g., the diffusion process. This approach has produced dramatic improvements on the final performance thanks to the application of such algorithms to the kNN graph. Unfortunately, this recent technique needs a manual configuration of several parameters, thus it is not straightforward to find the best configuration for each dataset. Moreover, the brute-force approach is computationally very demanding when used to optimally set the parameters of the diffusion approach. We propose to use genetic algorithms to find the optimal setting of all the diffusion parameters with respect to retrieval performance for each different dataset. Our approach is faster than others used as references (brute-force, random-search and PSO). A comparison with these methods has been made on three public image datasets: Oxford5k, Paris6k and Oxford105k.
An Efficient Approximate kNN Graph Method for Diffusion on Image Retrieval
Apr 18, 2019
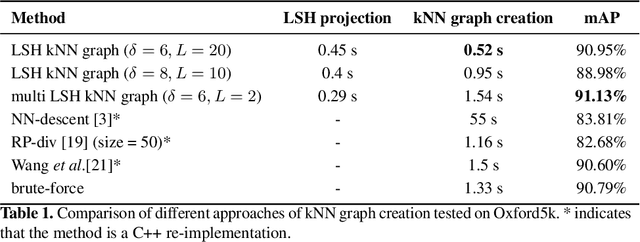
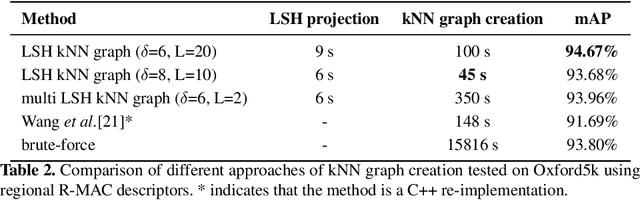

The application of the diffusion in many computer vision and artificial intelligence projects has been shown to give excellent improvements in performance. One of the main bottlenecks of this technique is the quadratic growth of the kNN graph size due to the high-quantity of new connections between nodes in the graph, resulting in long computation times. Several strategies have been proposed to address this, but none are effective and efficient. Our novel technique, based on LSH projections, obtains the same performance as the exact kNN graph after diffusion, but in less time (approximately 18 times faster on a dataset of a hundred thousand images). The proposed method was validated and compared with other state-of-the-art on several public image datasets, including Oxford5k, Paris6k, and Oxford105k.
A Dense-Depth Representation for VLAD descriptors in Content-Based Image Retrieval
Aug 15, 2018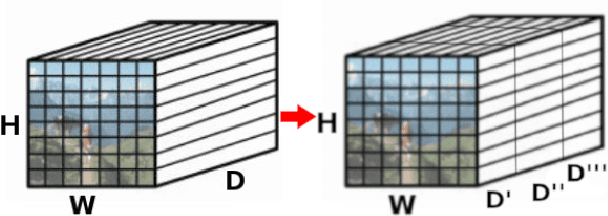
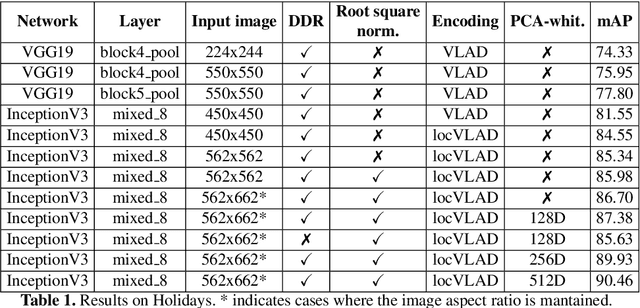
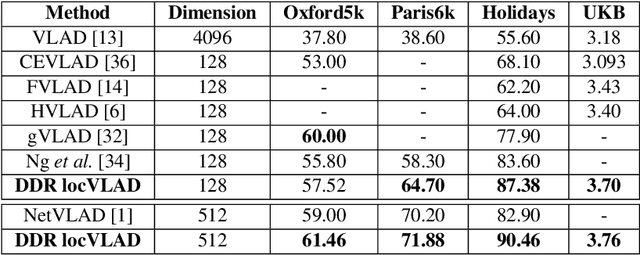
The recent advances brought by deep learning allowed to improve the performance in image retrieval tasks. Through the many convolutional layers, available in a Convolutional Neural Network (CNN), it is possible to obtain a hierarchy of features from the evaluated image. At every step, the patches extracted are smaller than the previous levels and more representative. Following this idea, this paper introduces a new detector applied on the feature maps extracted from pre-trained CNN. Specifically, this approach lets to increase the number of features in order to increase the performance of the aggregation algorithms like the most famous and used VLAD embedding. The proposed approach is tested on different public datasets: Holidays, Oxford5k, Paris6k and UKB.
An accurate retrieval through R-MAC+ descriptors for landmark recognition
Jun 22, 2018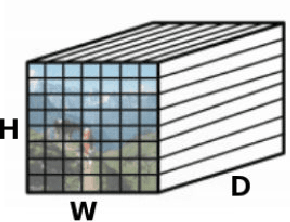
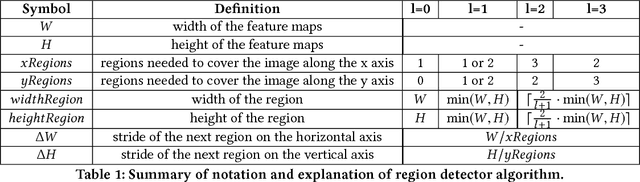
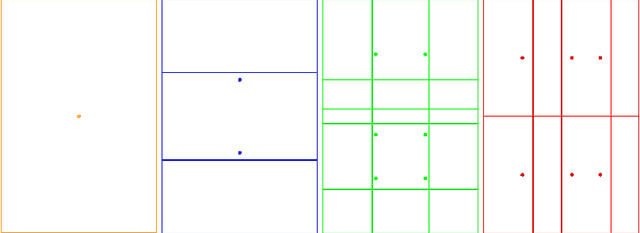
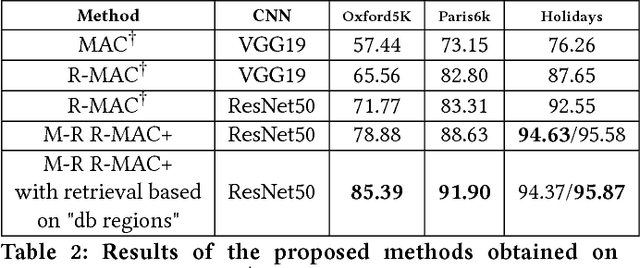
The landmark recognition problem is far from being solved, but with the use of features extracted from intermediate layers of Convolutional Neural Networks (CNNs), excellent results have been obtained. In this work, we propose some improvements on the creation of R-MAC descriptors in order to make the newly-proposed R-MAC+ descriptors more representative than the previous ones. However, the main contribution of this paper is a novel retrieval technique, that exploits the fine representativeness of the MAC descriptors of the database images. Using this descriptors called "db regions" during the retrieval stage, the performance is greatly improved. The proposed method is tested on different public datasets: Oxford5k, Paris6k and Holidays. It outperforms the state-of-the- art results on Holidays and reached excellent results on Oxford5k and Paris6k, overcame only by approaches based on fine-tuning strategies.
Efficient Nearest Neighbors Search for Large-Scale Landmark Recognition
Jun 15, 2018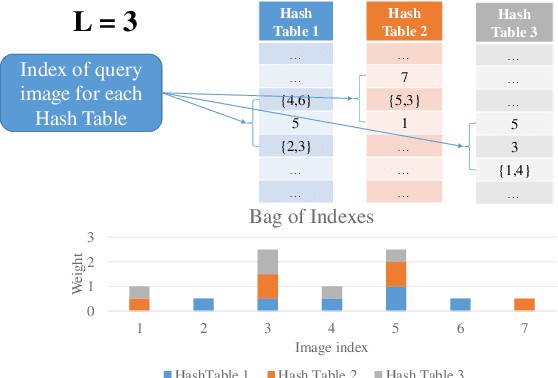
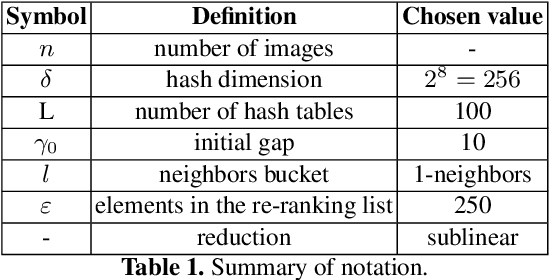
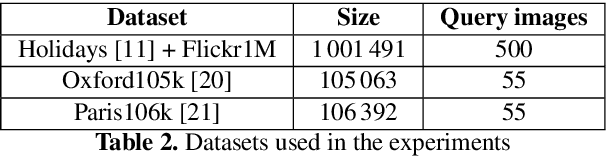
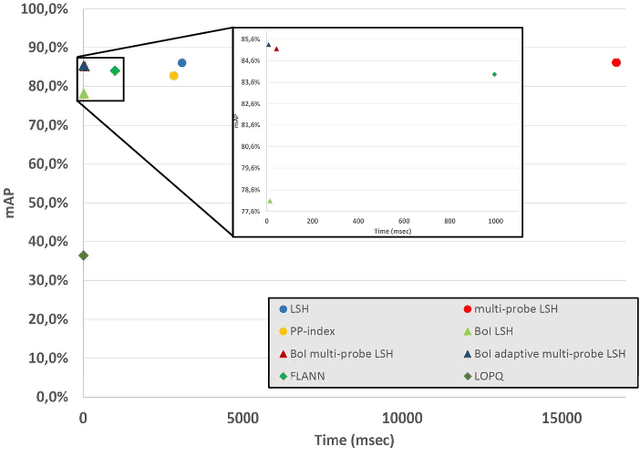
The problem of landmark recognition has achieved excellent results in small-scale datasets. When dealing with large-scale retrieval, issues that were irrelevant with small amount of data, quickly become fundamental for an efficient retrieval phase. In particular, computational time needs to be kept as low as possible, whilst the retrieval accuracy has to be preserved as much as possible. In this paper we propose a novel multi-index hashing method called Bag of Indexes (BoI) for Approximate Nearest Neighbors (ANN) search. It allows to drastically reduce the query time and outperforms the accuracy results compared to the state-of-the-art methods for large-scale landmark recognition. It has been demonstrated that this family of algorithms can be applied on different embedding techniques like VLAD and R-MAC obtaining excellent results in very short times on different public datasets: Holidays+Flickr1M, Oxford105k and Paris106k.
A complete hand-drawn sketch vectorization framework
Feb 16, 2018
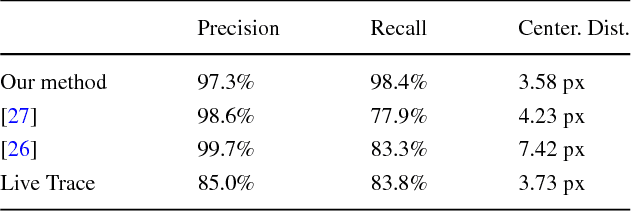

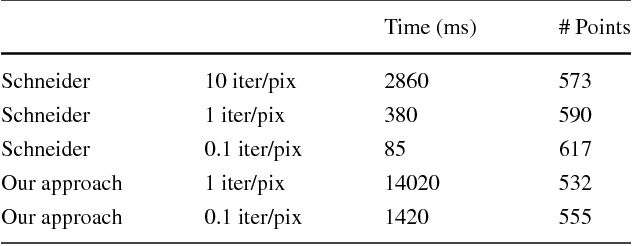
Vectorizing hand-drawn sketches is a challenging task, which is of paramount importance for creating CAD vectorized versions for the fashion and creative workflows. This paper proposes a complete framework that automatically transforms noisy and complex hand-drawn sketches with different stroke types in a precise, reliable and highly-simplified vectorized model. The proposed framework includes a novel line extraction algorithm based on a multi-resolution application of Pearson's cross correlation and a new unbiased thinning algorithm that can get rid of scribbles and variable-width strokes to obtain clean 1-pixel lines. Other contributions include variants of pruning, merging and edge linking procedures to post-process the obtained paths. Finally, a modification of the original Schneider's vectorization algorithm is designed to obtain fewer control points in the resulting Bezier splines. All the proposed steps of the framework have been extensively tested and compared with state-of-the-art algorithms, showing (both qualitatively and quantitatively) its outperformance.