 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthorship Impersonation via LLM Prompting does not Evade Authorship Verification Methods
Mar 31, 2026Authorship verification (AV), the task of determining whether a questioned text was written by a specific individual, is a critical part of forensic linguistics. While manual authorial impersonation by perpetrators has long been a recognized threat in historical forensic cases, recent advances in large language models (LLMs) raise new challenges, as adversaries may exploit these tools to impersonate another's writing. This study investigates whether prompted LLMs can generate convincing authorial impersonations and whether such outputs can evade existing forensic AV systems. Using GPT-4o as the adversary model, we generated impersonation texts under four prompting conditions across three genres: emails, text messages, and social media posts. We then evaluated these outputs against both non-neural AV methods (n-gram tracing, Ranking-Based Impostors Method, LambdaG) and neural approaches (AdHominem, LUAR, STAR) within a likelihood-ratio framework. Results show that LLM-generated texts failed to sufficiently replicate authorial individuality to bypass established AV systems. We also observed that some methods achieved even higher accuracy when rejecting impersonation texts compared to genuine negative samples. Overall, these findings indicate that, despite the accessibility of LLMs, current AV systems remain robust against entry-level impersonation attempts across multiple genres. Furthermore, we demonstrate that this counter-intuitive resilience stems, at least in part, from the higher lexical diversity and entropy inherent in LLM-generated texts.
Authorship Verification based on the Likelihood Ratio of Grammar Models
Mar 13, 2024Authorship Verification (AV) is the process of analyzing a set of documents to determine whether they were written by a specific author. This problem often arises in forensic scenarios, e.g., in cases where the documents in question constitute evidence for a crime. Existing state-of-the-art AV methods use computational solutions that are not supported by a plausible scientific explanation for their functioning and that are often difficult for analysts to interpret. To address this, we propose a method relying on calculating a quantity we call $\lambda_G$ (LambdaG): the ratio between the likelihood of a document given a model of the Grammar for the candidate author and the likelihood of the same document given a model of the Grammar for a reference population. These Grammar Models are estimated using $n$-gram language models that are trained solely on grammatical features. Despite not needing large amounts of data for training, LambdaG still outperforms other established AV methods with higher computational complexity, including a fine-tuned Siamese Transformer network. Our empirical evaluation based on four baseline methods applied to twelve datasets shows that LambdaG leads to better results in terms of both accuracy and AUC in eleven cases and in all twelve cases if considering only topic-agnostic methods. The algorithm is also highly robust to important variations in the genre of the reference population in many cross-genre comparisons. In addition to these properties, we demonstrate how LambdaG is easier to interpret than the current state-of-the-art. We argue that the advantage of LambdaG over other methods is due to fact that it is compatible with Cognitive Linguistic theories of language processing.
Register Variation Remains Stable Across 60 Languages
Sep 20, 2022
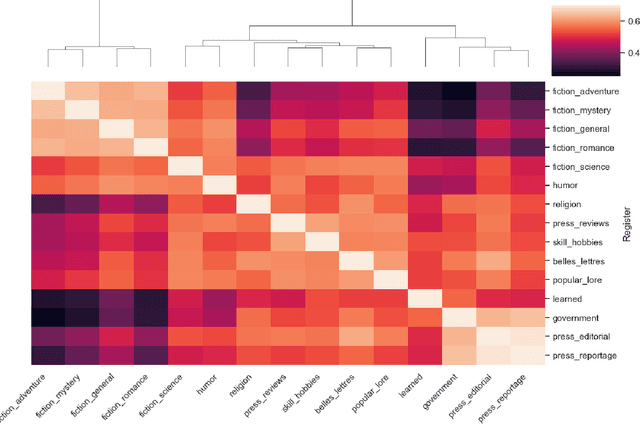
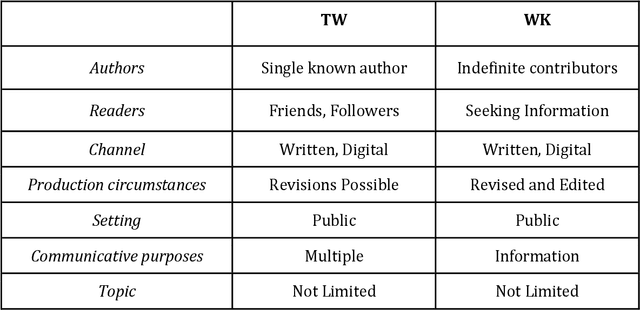
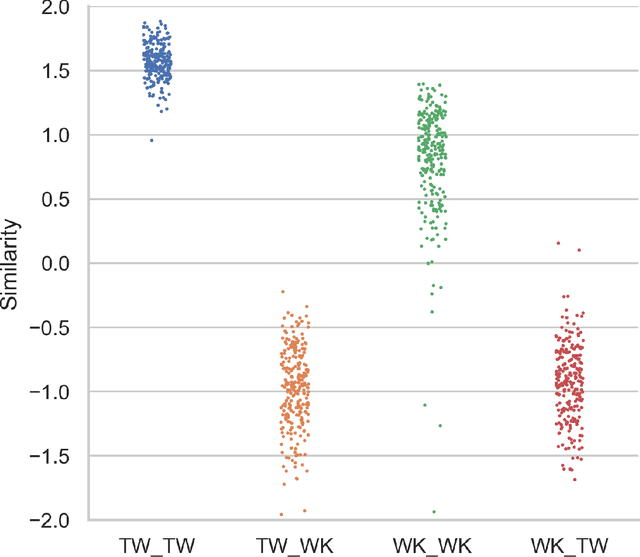
This paper measures the stability of cross-linguistic register variation. A register is a variety of a language that is associated with extra-linguistic context. The relationship between a register and its context is functional: the linguistic features that make up a register are motivated by the needs and constraints of the communicative situation. This view hypothesizes that register should be universal, so that we expect a stable relationship between the extra-linguistic context that defines a register and the sets of linguistic features which the register contains. In this paper, the universality and robustness of register variation is tested by comparing variation within vs. between register-specific corpora in 60 languages using corpora produced in comparable communicative situations: tweets and Wikipedia articles. Our findings confirm the prediction that register variation is, in fact, universal.
Production vs Perception: The Role of Individuality in Usage-Based Grammar Induction
Apr 19, 2021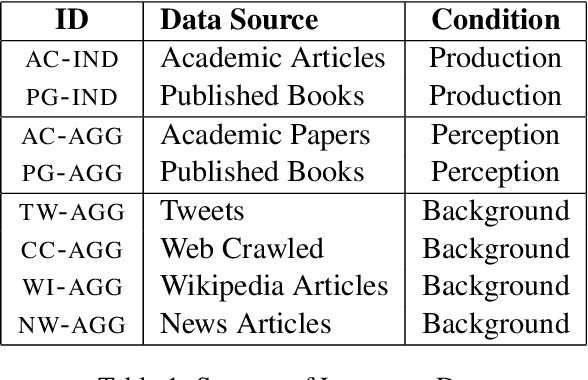
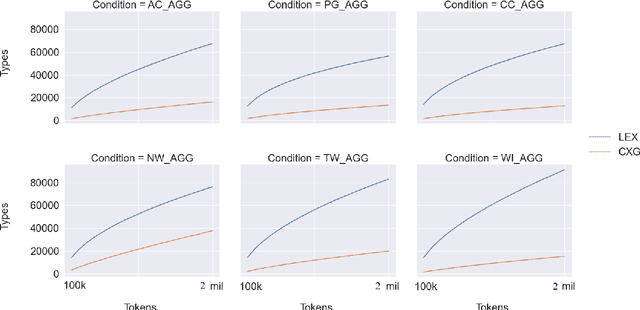
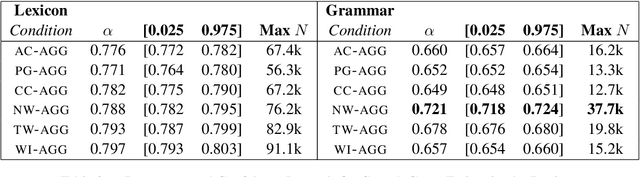
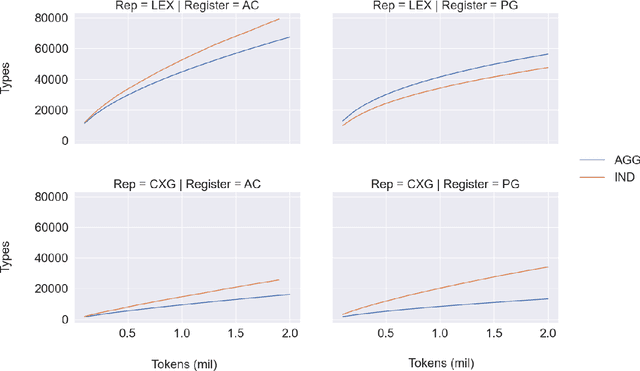
This paper asks whether a distinction between production-based and perception-based grammar induction influences either (i) the growth curve of grammars and lexicons or (ii) the similarity between representations learned from independent sub-sets of a corpus. A production-based model is trained on the usage of a single individual, thus simulating the grammatical knowledge of a single speaker. A perception-based model is trained on an aggregation of many individuals, thus simulating grammatical generalizations learned from exposure to many different speakers. To ensure robustness, the experiments are replicated across two registers of written English, with four additional registers reserved as a control. A set of three computational experiments shows that production-based grammars are significantly different from perception-based grammars across all conditions, with a steeper growth curve that can be explained by substantial inter-individual grammatical differences.