 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaTeCS an open-source JAva TExt Categorization System
Jun 21, 2017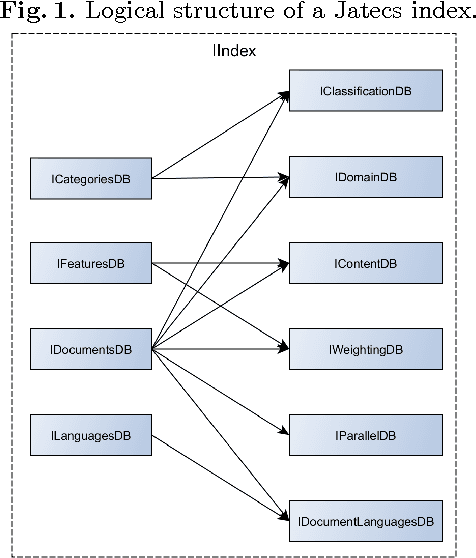
JaTeCS is an open source Java library that supports research on automatic text categorization and other related problems, such as ordinal regression and quantification, which are of special interest in opinion mining applications. It covers all the steps of an experimental activity, from reading the corpus to the evaluation of the experimental results. As JaTeCS is focused on text as the main input data, it provides the user with many text-dedicated tools, e.g.: data readers for many formats, including the most commonly used text corpora and lexical resources, natural language processing tools, multi-language support, methods for feature selection and weighting, the implementation of many machine learning algorithms as well as wrappers for well-known external software (e.g., SVM_light) which enable their full control from code. JaTeCS support its expansion by abstracting through interfaces many of the typical tools and procedures used in text processing tasks. The library also provides a number of "template" implementations of typical experimental setups (e.g., train-test, k-fold validation, grid-search optimization, randomized runs) which enable fast realization of experiments just by connecting the templates with data readers, learning algorithms and evaluation measures.
Exploring epoch-dependent stochastic residual networks
Apr 20, 2017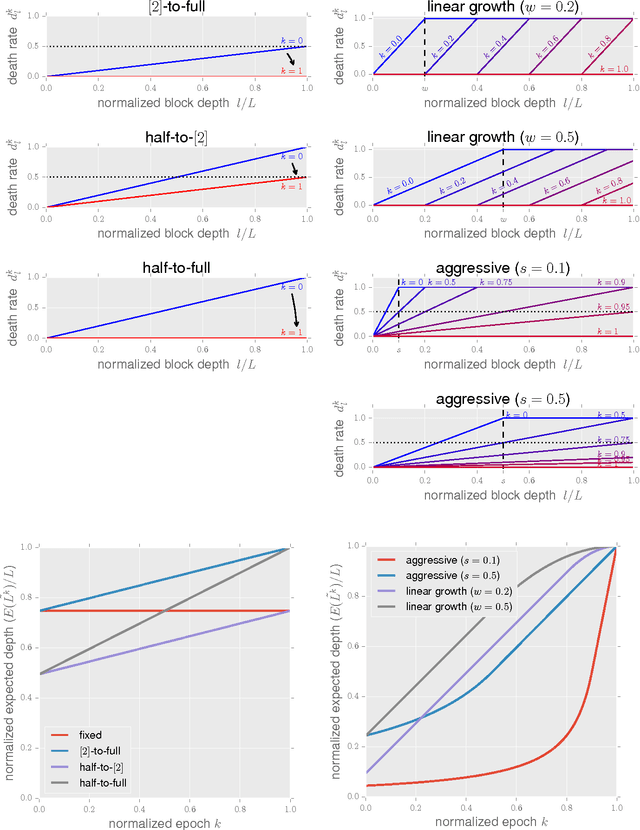
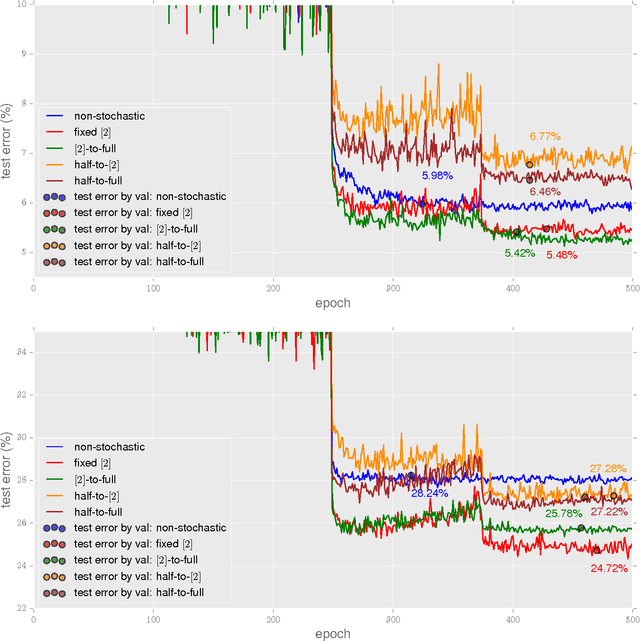
The recently proposed stochastic residual networks selectively activate or bypass the layers during training, based on independent stochastic choices, each of which following a probability distribution that is fixed in advance. In this paper we present a first exploration on the use of an epoch-dependent distribution, starting with a higher probability of bypassing deeper layers and then activating them more frequently as training progresses. Preliminary results are mixed, yet they show some potential of adding an epoch-dependent management of distributions, worth of further investigation.
Picture It In Your Mind: Generating High Level Visual Representations From Textual Descriptions
Jun 23, 2016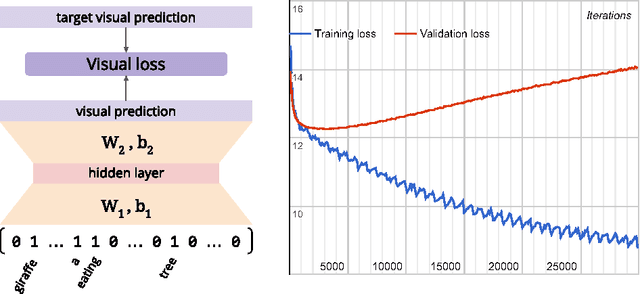
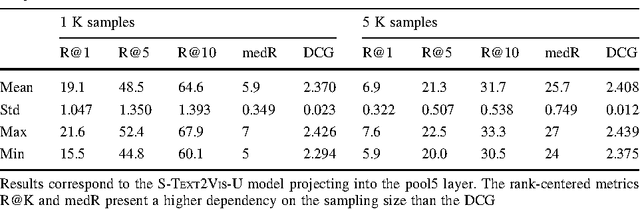
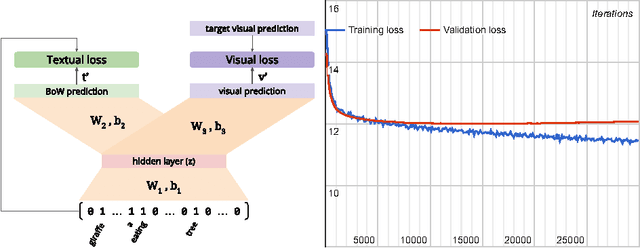
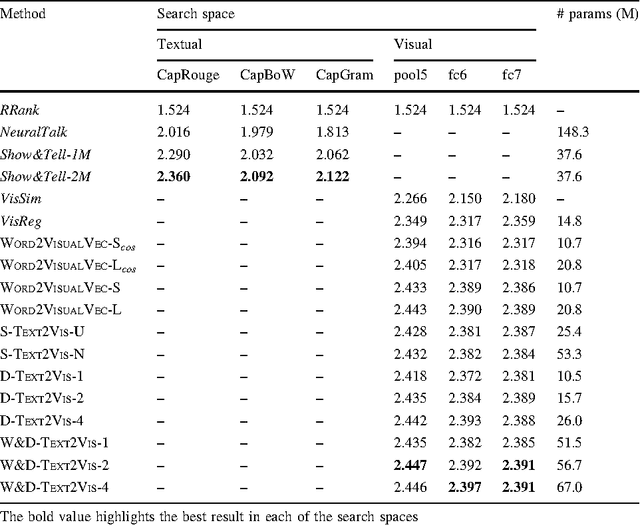
In this paper we tackle the problem of image search when the query is a short textual description of the image the user is looking for. We choose to implement the actual search process as a similarity search in a visual feature space, by learning to translate a textual query into a visual representation. Searching in the visual feature space has the advantage that any update to the translation model does not require to reprocess the, typically huge, image collection on which the search is performed. We propose Text2Vis, a neural network that generates a visual representation, in the visual feature space of the fc6-fc7 layers of ImageNet, from a short descriptive text. Text2Vis optimizes two loss functions, using a stochastic loss-selection method. A visual-focused loss is aimed at learning the actual text-to-visual feature mapping, while a text-focused loss is aimed at modeling the higher-level semantic concepts expressed in language and countering the overfit on non-relevant visual components of the visual loss. We report preliminary results on the MS-COCO dataset.
Optimizing Text Quantifiers for Multivariate Loss Functions
Apr 15, 2015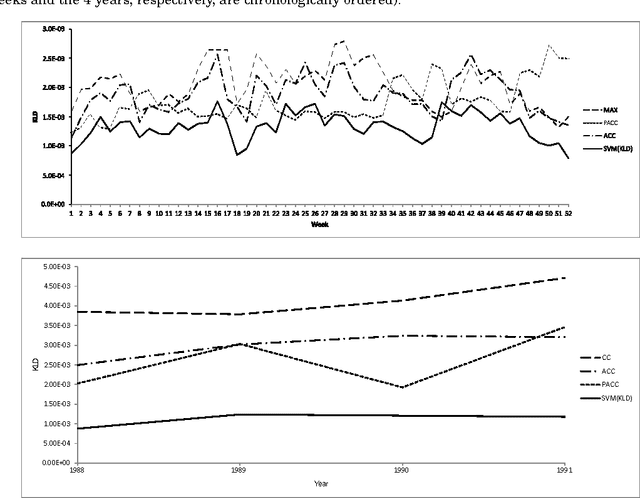
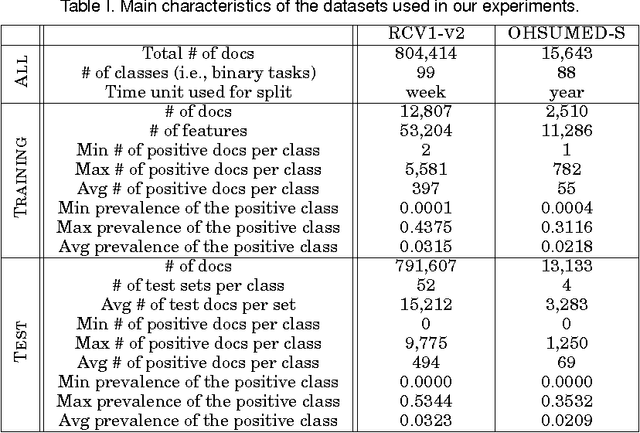
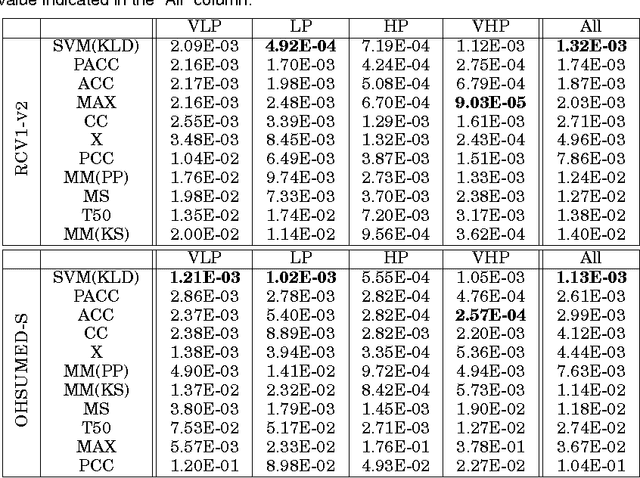
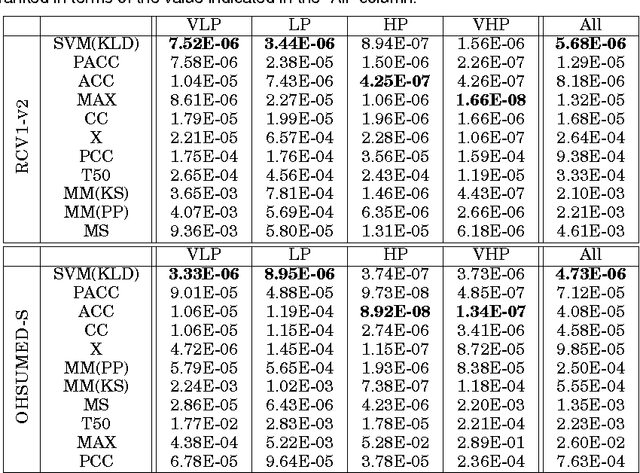
We address the problem of \emph{quantification}, a supervised learning task whose goal is, given a class, to estimate the relative frequency (or \emph{prevalence}) of the class in a dataset of unlabelled items. Quantification has several applications in data and text mining, such as estimating the prevalence of positive reviews in a set of reviews of a given product, or estimating the prevalence of a given support issue in a dataset of transcripts of phone calls to tech support. So far, quantification has been addressed by learning a general-purpose classifier, counting the unlabelled items which have been assigned the class, and tuning the obtained counts according to some heuristics. In this paper we depart from the tradition of using general-purpose classifiers, and use instead a supervised learning model for \emph{structured prediction}, capable of generating classifiers directly optimized for the (multivariate and non-linear) function used for evaluating quantification accuracy. The experiments that we have run on 5500 binary high-dimensional datasets (averaging more than 14,000 documents each) show that this method is more accurate, more stable, and more efficient than existing, state-of-the-art quantification methods.
Utility-Theoretic Ranking for Semi-Automated Text Classification
Mar 02, 2015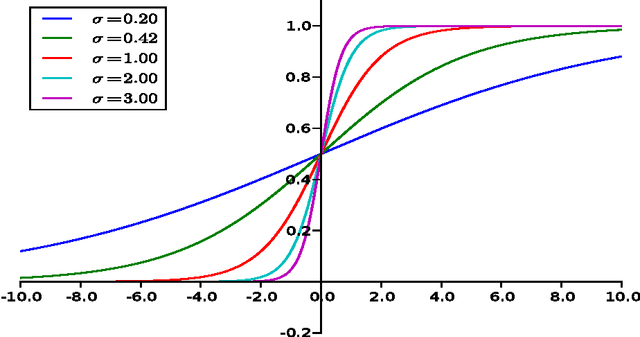
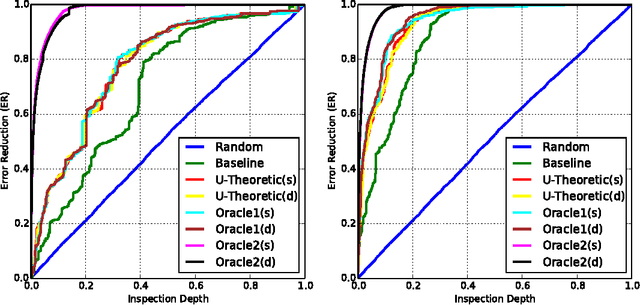
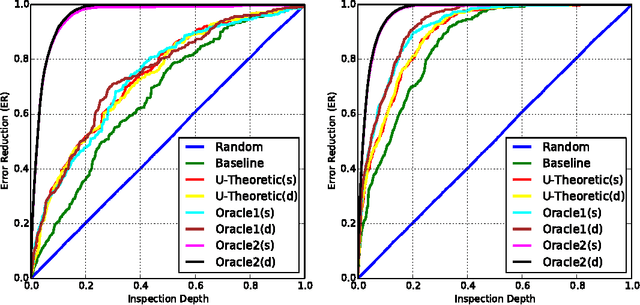
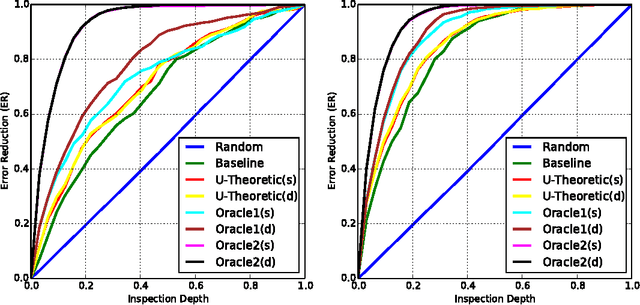
\emph{Semi-Automated Text Classification} (SATC) may be defined as the task of ranking a set $\mathcal{D}$ of automatically labelled textual documents in such a way that, if a human annotator validates (i.e., inspects and corrects where appropriate) the documents in a top-ranked portion of $\mathcal{D}$ with the goal of increasing the overall labelling accuracy of $\mathcal{D}$, the expected increase is maximized. An obvious SATC strategy is to rank $\mathcal{D}$ so that the documents that the classifier has labelled with the lowest confidence are top-ranked. In this work we show that this strategy is suboptimal. We develop new utility-theoretic ranking methods based on the notion of \emph{validation gain}, defined as the improvement in classification effectiveness that would derive by validating a given automatically labelled document. We also propose a new effectiveness measure for SATC-oriented ranking methods, based on the expected reduction in classification error brought about by partially validating a list generated by a given ranking method. We report the results of experiments showing that, with respect to the baseline method above, and according to the proposed measure, our utility-theoretic ranking methods can achieve substantially higher expected reductions in classification error.
The User Feedback on SentiWordNet
Jun 06, 2013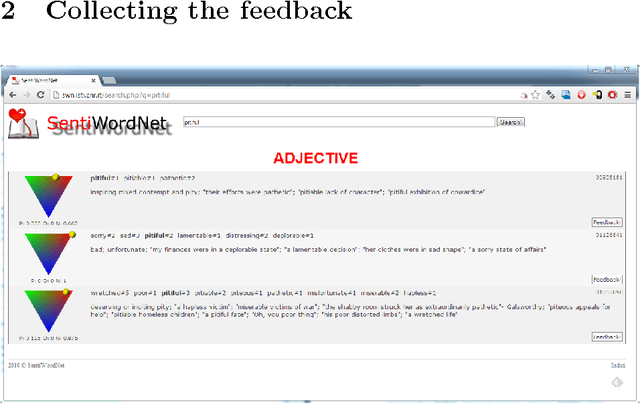
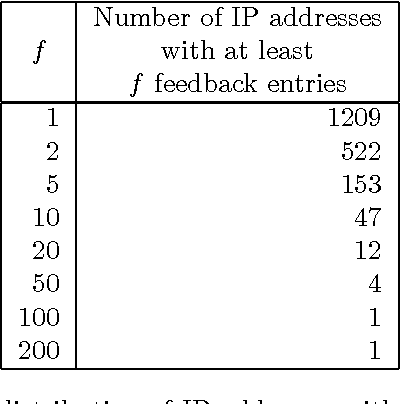
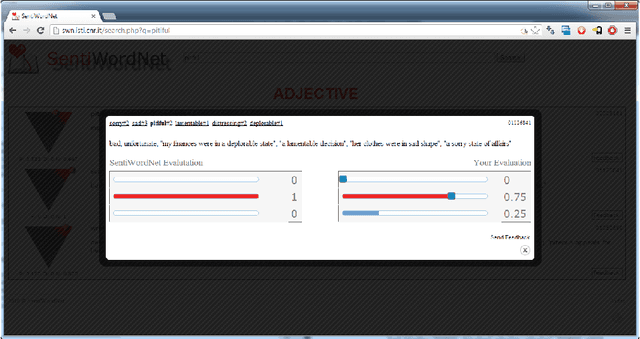
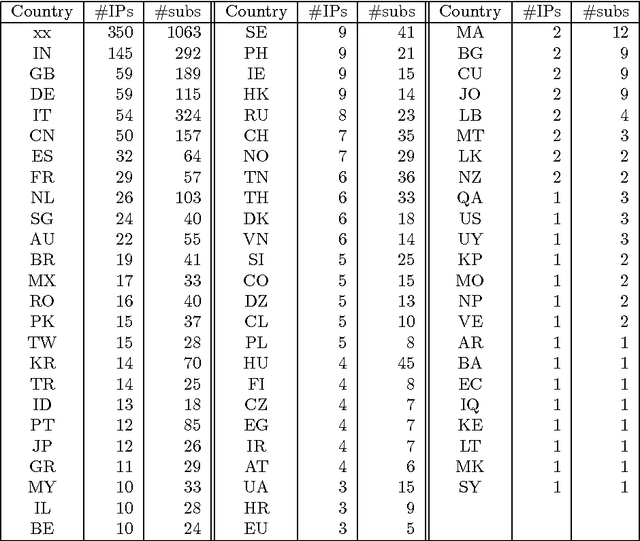
With the release of SentiWordNet 3.0 the related Web interface has been restyled and improved in order to allow users to submit feedback on the SentiWordNet entries, in the form of the suggestion of alternative triplets of values for an entry. This paper reports on the release of the user feedback collected so far and on the plans for the future.