 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication without Interception: Defense against Deep-Learning-based Modulation Detection
Feb 27, 2019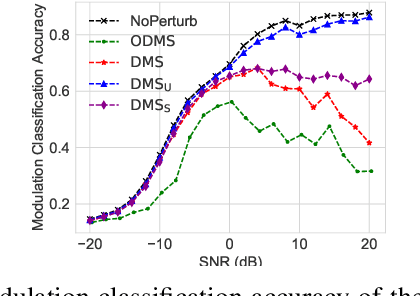
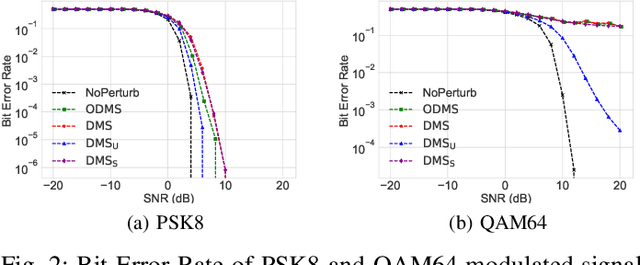
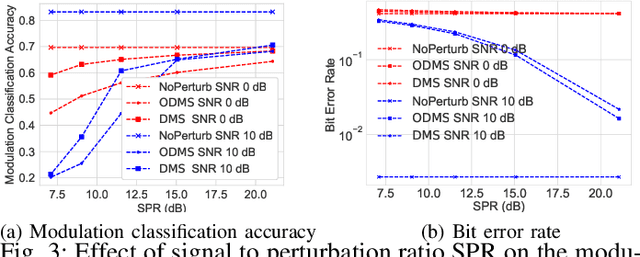
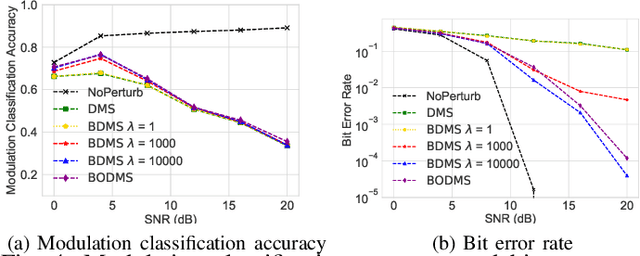
We consider a communication scenario, in which an intruder, employing a deep neural network (DNN), tries to determine the modulation scheme of the intercepted signal. Our aim is to minimize the accuracy of the intruder, while guaranteeing that the intended receiver can still recover the underlying message with the highest reliability. This is achieved by constellation perturbation at the encoder, similarly to adversarial attacks against DNN-based classifiers. In the latter perturbation is limited to be imperceptible to a human observer, while in our case perturbation is constrained so that the message can still be reliably decoded by the legitimate receiver which is oblivious to the perturbation. Simulation results demonstrate the viability of our approach to make wireless communication secure against DNN-based intruders with minimal sacrifice in the communication performance.
Learning from Delayed Outcomes with Intermediate Observations
Jul 24, 2018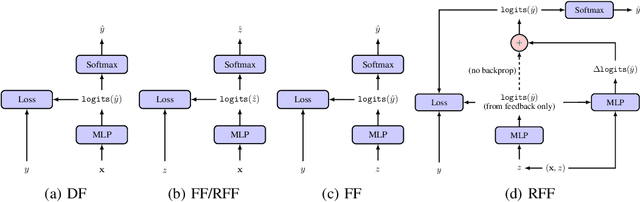

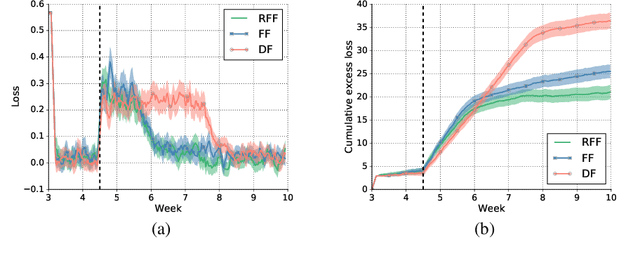
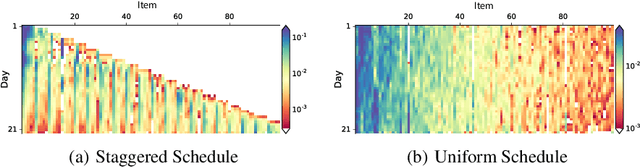
Optimizing for long term value is desirable in many practical applications, e.g. recommender systems. The most common approach for long term value optimization is supervised learning using long term value as the target. Unfortunately, long term metrics take a long time to measure (e.g., will customers finish reading an ebook?), and vanilla forecasters cannot learn from examples until the outcome is observed. In practical systems where new items arrive frequently, such delay can increase the training-serving skew, thereby negatively affecting the model's predictions for new products. We argue that intermediate observations (e.g., if customers read a third of the book in 24 hours) can improve a model's predictions. We formalize the problem as a semi-stochastic model, where instances are selected by an adversary but, given an instance, the intermediate observation and the outcome are sampled from a factored joint distribution. We propose an algorithm that exploits intermediate observations and theoretically quantify how much it can outperform any prediction method that ignores the intermediate observations. Motivated by the theoretical analysis, we propose two neural network architectures: Factored Forecaster (FF) which is ideal if our assumptions are satisfied, and Residual Factored Forecaster (RFF) that is more robust to model mis-specification. Experiments on two real world datasets, a dataset derived from GitHub repositories and another dataset from a popular marketplace, show that RFF outperforms both FF as well as an algorithm that ignores intermediate observations.
Detection of Adversarial Training Examples in Poisoning Attacks through Anomaly Detection
Feb 08, 2018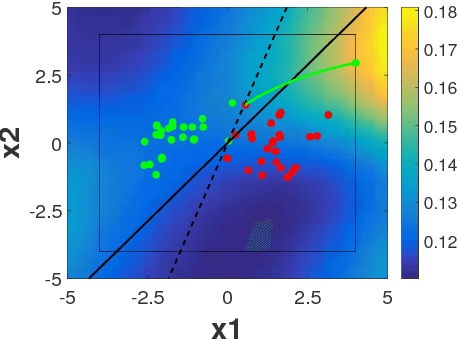
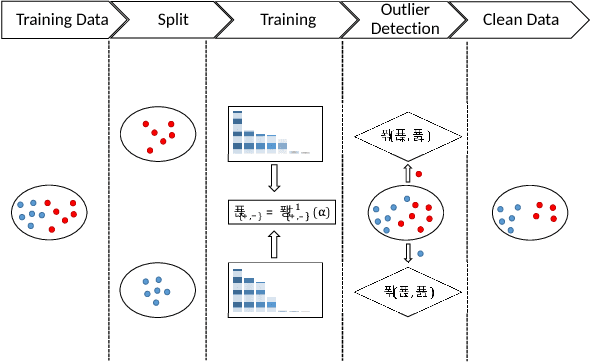
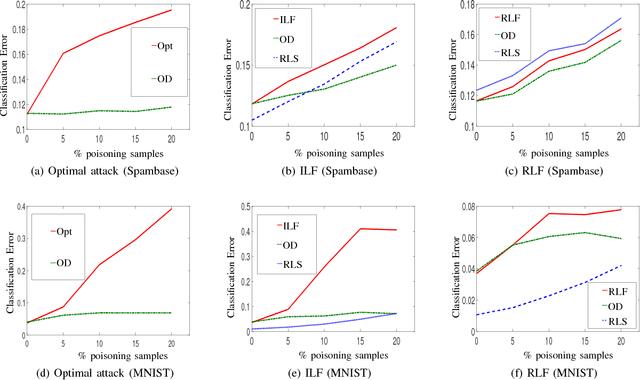

Machine learning has become an important component for many systems and applications including computer vision, spam filtering, malware and network intrusion detection, among others. Despite the capabilities of machine learning algorithms to extract valuable information from data and produce accurate predictions, it has been shown that these algorithms are vulnerable to attacks. Data poisoning is one of the most relevant security threats against machine learning systems, where attackers can subvert the learning process by injecting malicious samples in the training data. Recent work in adversarial machine learning has shown that the so-called optimal attack strategies can successfully poison linear classifiers, degrading the performance of the system dramatically after compromising a small fraction of the training dataset. In this paper we propose a defence mechanism to mitigate the effect of these optimal poisoning attacks based on outlier detection. We show empirically that the adversarial examples generated by these attack strategies are quite different from genuine points, as no detectability constrains are considered to craft the attack. Hence, they can be detected with an appropriate pre-filtering of the training dataset.
The on-line shortest path problem under partial monitoring
Apr 08, 2007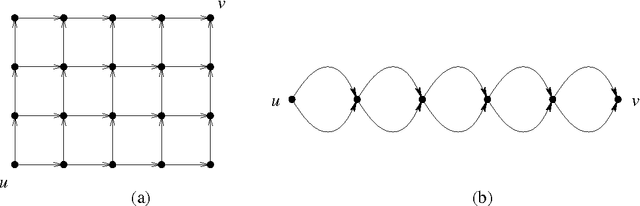

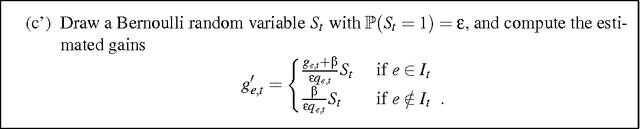

The on-line shortest path problem is considered under various models of partial monitoring. Given a weighted directed acyclic graph whose edge weights can change in an arbitrary (adversarial) way, a decision maker has to choose in each round of a game a path between two distinguished vertices such that the loss of the chosen path (defined as the sum of the weights of its composing edges) be as small as possible. In a setting generalizing the multi-armed bandit problem, after choosing a path, the decision maker learns only the weights of those edges that belong to the chosen path. For this problem, an algorithm is given whose average cumulative loss in n rounds exceeds that of the best path, matched off-line to the entire sequence of the edge weights, by a quantity that is proportional to 1/\sqrt{n} and depends only polynomially on the number of edges of the graph. The algorithm can be implemented with linear complexity in the number of rounds n and in the number of edges. An extension to the so-called label efficient setting is also given, in which the decision maker is informed about the weights of the edges corresponding to the chosen path at a total of m << n time instances. Another extension is shown where the decision maker competes against a time-varying path, a generalization of the problem of tracking the best expert. A version of the multi-armed bandit setting for shortest path is also discussed where the decision maker learns only the total weight of the chosen path but not the weights of the individual edges on the path. Applications to routing in packet switched networks along with simulation results are also presented.