 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning with Labeled and Unlabeled Tasks
Jun 08, 2017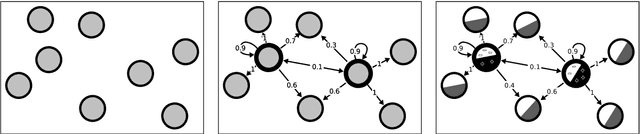
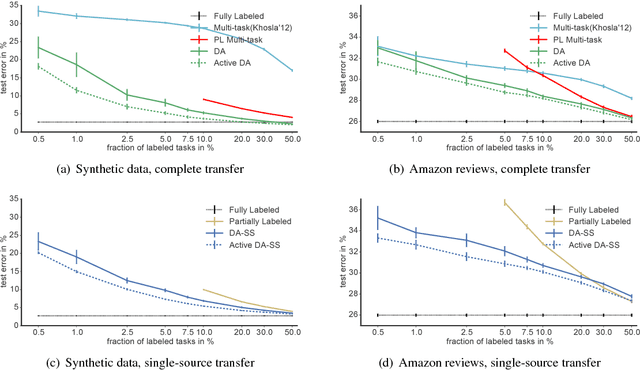
In multi-task learning, a learner is given a collection of prediction tasks and needs to solve all of them. In contrast to previous work, which required that annotated training data is available for all tasks, we consider a new setting, in which for some tasks, potentially most of them, only unlabeled training data is provided. Consequently, to solve all tasks, information must be transferred between tasks with labels and tasks without labels. Focusing on an instance-based transfer method we analyze two variants of this setting: when the set of labeled tasks is fixed, and when it can be actively selected by the learner. We state and prove a generalization bound that covers both scenarios and derive from it an algorithm for making the choice of labeled tasks (in the active case) and for transferring information between the tasks in a principled way. We also illustrate the effectiveness of the algorithm by experiments on synthetic and real data.
Multi-task and Lifelong Learning of Kernels
Aug 18, 2016We consider a problem of learning kernels for use in SVM classification in the multi-task and lifelong scenarios and provide generalization bounds on the error of a large margin classifier. Our results show that, under mild conditions on the family of kernels used for learning, solving several related tasks simultaneously is beneficial over single task learning. In particular, as the number of observed tasks grows, assuming that in the considered family of kernels there exists one that yields low approximation error on all tasks, the overhead associated with learning such a kernel vanishes and the complexity converges to that of learning when this good kernel is given to the learner.
Curriculum Learning of Multiple Tasks
Dec 03, 2014
Sharing information between multiple tasks enables algorithms to achieve good generalization performance even from small amounts of training data. However, in a realistic scenario of multi-task learning not all tasks are equally related to each other, hence it could be advantageous to transfer information only between the most related tasks. In this work we propose an approach that processes multiple tasks in a sequence with sharing between subsequent tasks instead of solving all tasks jointly. Subsequently, we address the question of curriculum learning of tasks, i.e. finding the best order of tasks to be learned. Our approach is based on a generalization bound criterion for choosing the task order that optimizes the average expected classification performance over all tasks. Our experimental results show that learning multiple related tasks sequentially can be more effective than learning them jointly, the order in which tasks are being solved affects the overall performance, and that our model is able to automatically discover the favourable order of tasks.
A PAC-Bayesian bound for Lifelong Learning
May 10, 2014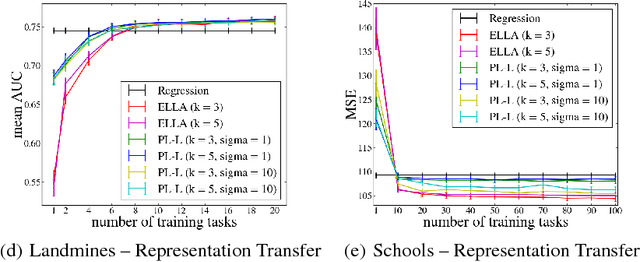
Transfer learning has received a lot of attention in the machine learning community over the last years, and several effective algorithms have been developed. However, relatively little is known about their theoretical properties, especially in the setting of lifelong learning, where the goal is to transfer information to tasks for which no data have been observed so far. In this work we study lifelong learning from a theoretical perspective. Our main result is a PAC-Bayesian generalization bound that offers a unified view on existing paradigms for transfer learning, such as the transfer of parameters or the transfer of low-dimensional representations. We also use the bound to derive two principled lifelong learning algorithms, and we show that these yield results comparable with existing methods.