 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHySem: A context length optimized LLM pipeline for unstructured tabular extraction
Aug 18, 2024Regulatory compliance reporting in the pharmaceutical industry relies on detailed tables, but these are often under-utilized beyond compliance due to their unstructured format and arbitrary content. Extracting and semantically representing tabular data is challenging due to diverse table presentations. Large Language Models (LLMs) demonstrate substantial potential for semantic representation, yet they encounter challenges related to accuracy and context size limitations, which are crucial considerations for the industry applications. We introduce HySem, a pipeline that employs a novel context length optimization technique to generate accurate semantic JSON representations from HTML tables. This approach utilizes a custom fine-tuned model specifically designed for cost- and privacy-sensitive small and medium pharmaceutical enterprises. Running on commodity hardware and leveraging open-source models, our auto-correcting agents rectify both syntax and semantic errors in LLM-generated content. HySem surpasses its peer open-source models in accuracy and provides competitive performance when benchmarked against OpenAI GPT-4o and effectively addresses context length limitations, which is a crucial factor for supporting larger tables.
A Factorized Recurrent Neural Network based architecture for medium to large vocabulary Language Modelling
Feb 04, 2016

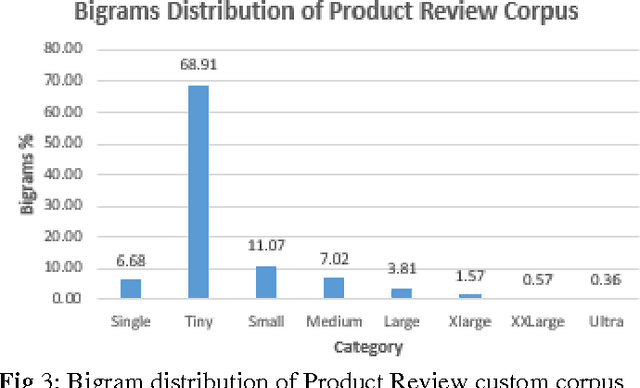

Statistical language models are central to many applications that use semantics. Recurrent Neural Networks (RNN) are known to produce state of the art results for language modelling, outperforming their traditional n-gram counterparts in many cases. To generate a probability distribution across a vocabulary, these models require a softmax output layer that linearly increases in size with the size of the vocabulary. Large vocabularies need a commensurately large softmax layer and training them on typical laptops/PCs requires significant time and machine resources. In this paper we present a new technique for implementing RNN based large vocabulary language models that substantially speeds up computation while optimally using the limited memory resources. Our technique, while building on the notion of factorizing the output layer by having multiple output layers, improves on the earlier work by substantially optimizing on the individual output layer size and also eliminating the need for a multistep prediction process.