 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Manually Annotated Image-Caption Dataset for Detecting Children in the Wild
Jun 11, 2025



Platforms and the law regulate digital content depicting minors (defined as individuals under 18 years of age) differently from other types of content. Given the sheer amount of content that needs to be assessed, machine learning-based automation tools are commonly used to detect content depicting minors. To our knowledge, no dataset or benchmark currently exists for detecting these identification methods in a multi-modal environment. To fill this gap, we release the Image-Caption Children in the Wild Dataset (ICCWD), an image-caption dataset aimed at benchmarking tools that detect depictions of minors. Our dataset is richer than previous child image datasets, containing images of children in a variety of contexts, including fictional depictions and partially visible bodies. ICCWD contains 10,000 image-caption pairs manually labeled to indicate the presence or absence of a child in the image. To demonstrate the possible utility of our dataset, we use it to benchmark three different detectors, including a commercial age estimation system applied to images. Our results suggest that child detection is a challenging task, with the best method achieving a 75.3% true positive rate. We hope the release of our dataset will aid in the design of better minor detection methods in a wide range of scenarios.
Dataset correlation inference attacks against machine learning models
Dec 16, 2021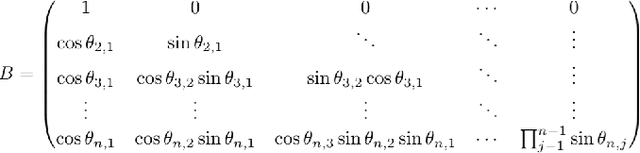
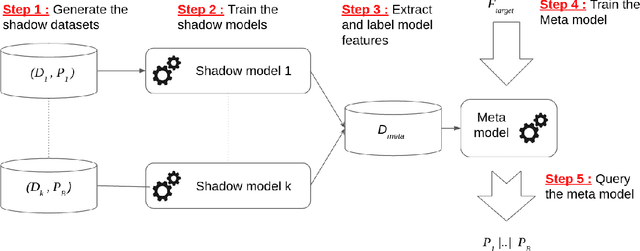
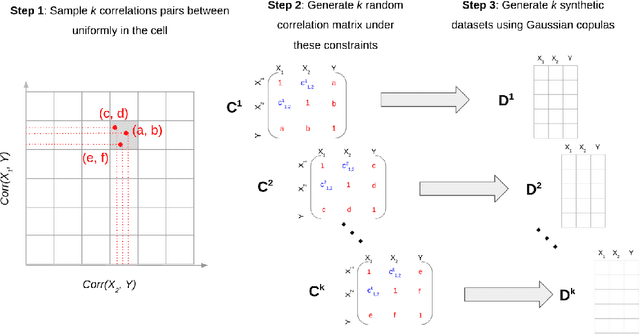
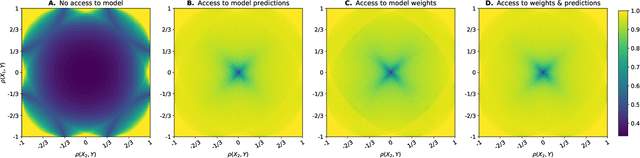
Machine learning models are increasingly used by businesses and organizations around the world to automate tasks and decision-making. Trained on potentially sensitive datasets, machine learning models have been shown to leak information about individuals in the dataset as well as global dataset information. We here take research in dataset property inference attacks one step further by proposing a new attack against ML models: a dataset correlation inference attack, where an attacker's goal is to infer the correlation between input variables of a model. We first show that an attacker can exploit the spherical parametrization of correlation matrices, to make an informed guess. This means that using only the correlation between the input variables and the target variable, an attacker can infer the correlation between two input variables much better than a random guess baseline. We propose a second attack which exploits the access to a machine learning model using shadow modeling to refine the guess. Our attack uses Gaussian copula-based generative modeling to generate synthetic datasets with a wide variety of correlations in order to train a meta-model for the correlation inference task. We evaluate our attack against Logistic Regression and Multi-layer perceptron models and show it to outperform the model-less attack. Our results show that the accuracy of the second, machine learning-based attack decreases with the number of variables and converges towards the accuracy of the model-less attack. However, correlations between input variables which are highly correlated with the target variable are more vulnerable regardless of the number of variables. Our work bridges the gap between what can be considered a global leakage about the training dataset and individual-level leakages. When coupled with marginal leakage attacks,it might also constitute a first step towards dataset reconstruction.