 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Struggle with Academic Plagiarism: Approaches based on Semantic Similarity
Jun 02, 2021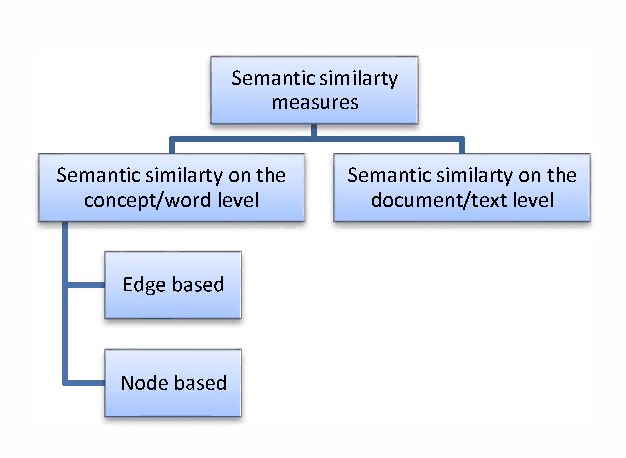
Academic plagiarism is a serious problem nowadays. Due to the existence of inexhaustible sources of digital information, today it is easier to plagiarize more than ever before. The good thing is that plagiarism detection techniques have improved and are powerful enough to detect attempts of plagiarism in education. We are now witnessing efficient plagiarism detection software in action, such as Turnitin, iThenticate or SafeAssign. In the introduction we explore software that is used within the Croatian academic community for plagiarism detection in universities and/or in scientific journals. The question is: is this enough? Current software has proven to be successful, however the problem of identifying paraphrasing or obfuscation plagiarism remains unresolved. In this paper we present a report of how semantic similarity measures can be used in the plagiarism detection task.
* 6 pages, 1 figure, 34 references
Corpus-Based Paraphrase Detection Experiments and Review
May 31, 2021



Paraphrase detection is important for a number of applications, including plagiarism detection, authorship attribution, question answering, text summarization, text mining in general, etc. In this paper, we give a performance overview of various types of corpus-based models, especially deep learning (DL) models, with the task of paraphrase detection. We report the results of eight models (LSI, TF-IDF, Word2Vec, Doc2Vec, GloVe, FastText, ELMO, and USE) evaluated on three different public available corpora: Microsoft Research Paraphrase Corpus, Clough and Stevenson and Webis Crowd Paraphrase Corpus 2011. Through a great number of experiments, we decided on the most appropriate approaches for text pre-processing: hyper-parameters, sub-model selection-where they exist (e.g., Skipgram vs. CBOW), distance measures, and semantic similarity/paraphrase detection threshold. Our findings and those of other researchers who have used deep learning models show that DL models are very competitive with traditional state-of-the-art approaches and have potential that should be further developed.
* 25 pages, 7 figures, 4 tables
Taxonomy of academic plagiarism methods
May 25, 2021
The article gives an overview of the plagiarism domain, with focus on academic plagiarism. The article defines plagiarism, explains the origin of the term, as well as plagiarism related terms. It identifies the extent of the plagiarism domain and then focuses on the plagiarism subdomain of text documents, for which it gives an overview of current classifications and taxonomies and then proposes a more comprehensive classification according to several criteria: their origin and purpose, technical implementation, consequence, complexity of detection and according to the number of linguistic sources. The article suggests the new classification of academic plagiarism, describes sorts and methods of plagiarism, types and categories, approaches and phases of plagiarism detection, the classification of methods and algorithms for plagiarism detection. The title of the article explicitly targets the academic community, but it is sufficiently general and interdisciplinary, so it can be useful for many other professionals like software developers, linguists and librarians.
* 18 pages, 3 figures, 1 table