 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Few-Shot NMT Adaptation
Apr 06, 2020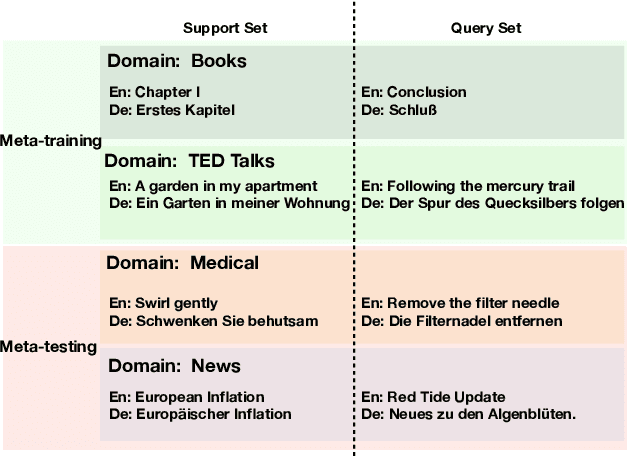
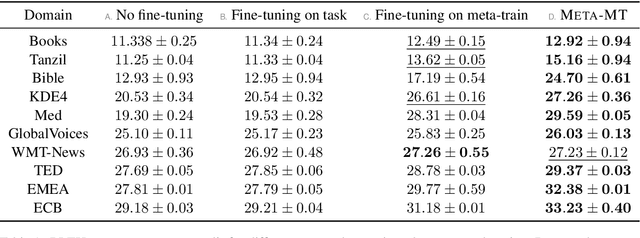

We present META-MT, a meta-learning approach to adapt Neural Machine Translation (NMT) systems in a few-shot setting. META-MT provides a new approach to make NMT models easily adaptable to many target domains with the minimal amount of in-domain data. We frame the adaptation of NMT systems as a meta-learning problem, where we learn to adapt to new unseen domains based on simulated offline meta-training domain adaptation tasks. We evaluate the proposed meta-learning strategy on ten domains with general large scale NMT systems. We show that META-MT significantly outperforms classical domain adaptation when very few in-domain examples are available. Our experiments shows that META-MT can outperform classical fine-tuning by up to 2.5 BLEU points after seeing only 4, 000 translated words (300 parallel sentences).
Meta-Learning for Contextual Bandit Exploration
Jan 23, 2019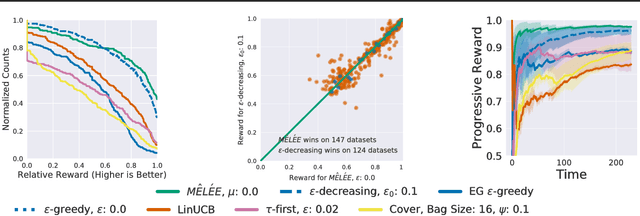
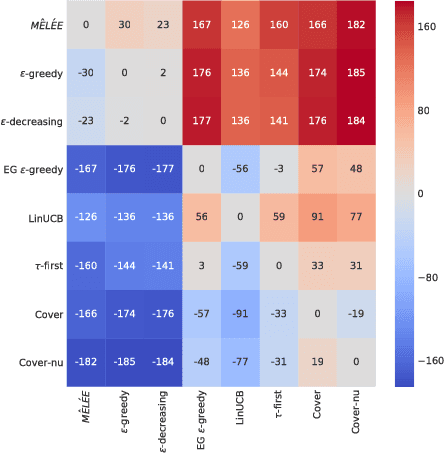
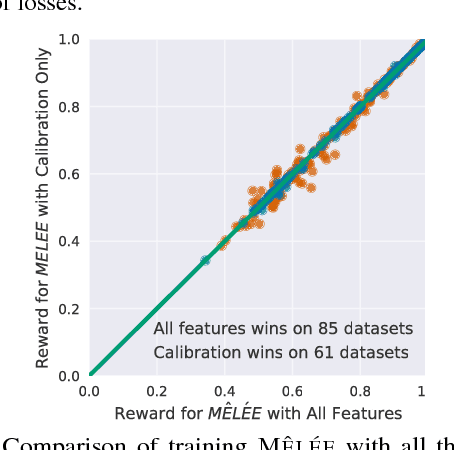
We describe MELEE, a meta-learning algorithm for learning a good exploration policy in the interactive contextual bandit setting. Here, an algorithm must take actions based on contexts, and learn based only on a reward signal from the action taken, thereby generating an exploration/exploitation trade-off. MELEE addresses this trade-off by learning a good exploration strategy for offline tasks based on synthetic data, on which it can simulate the contextual bandit setting. Based on these simulations, MELEE uses an imitation learning strategy to learn a good exploration policy that can then be applied to true contextual bandit tasks at test time. We compare MELEE to seven strong baseline contextual bandit algorithms on a set of three hundred real-world datasets, on which it outperforms alternatives in most settings, especially when differences in rewards are large. Finally, we demonstrate the importance of having a rich feature representation for learning how to explore.
Cross-Lingual Approaches to Reference Resolution in Dialogue Systems
Nov 27, 2018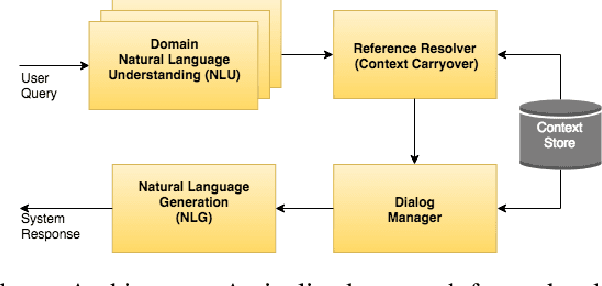
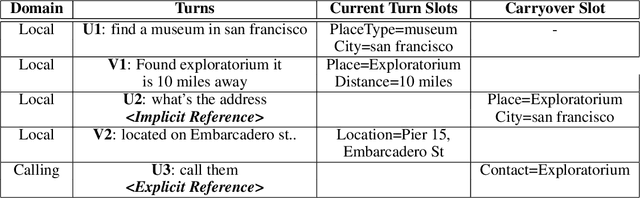
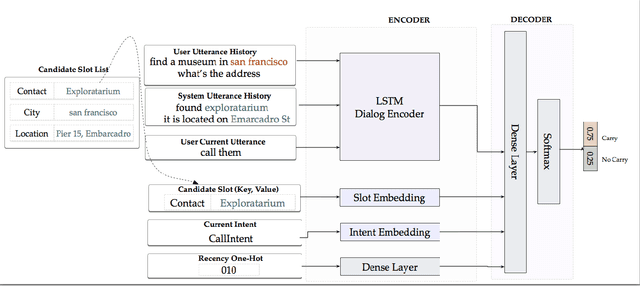

In the slot-filling paradigm, where a user can refer back to slots in the context during the conversation, the goal of the contextual understanding system is to resolve the referring expressions to the appropriate slots in the context. In this paper, we build on the context carryover system~\citep{Naik2018ContextualSC}, which provides a scalable multi-domain framework for resolving references. However, scaling this approach across languages is not a trivial task, due to the large demand on acquisition of annotated data in the target language. Our main focus is on cross-lingual methods for reference resolution as a way to alleviate the need for annotated data in the target language. In the cross-lingual setup, we assume there is access to annotated resources as well as a well trained model in the source language and little to no annotated data in the target language. In this paper, we explore three different approaches for cross-lingual transfer \textemdash~\ delexicalization as data augmentation, multilingual embeddings and machine translation. We compare these approaches both on a low resource setting as well as a large resource setting. Our experiments show that multilingual embeddings and delexicalization via data augmentation have a significant impact in the low resource setting, but the gains diminish as the amount of available data in the target language increases. Furthermore, when combined with machine translation we can get performance very close to actual live data in the target language, with only 25\% of the data projected into the target language.
The UMD Neural Machine Translation Systems at WMT17 Bandit Learning Task
Aug 07, 2017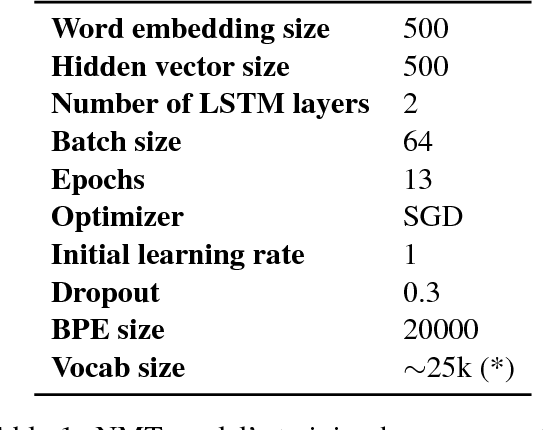
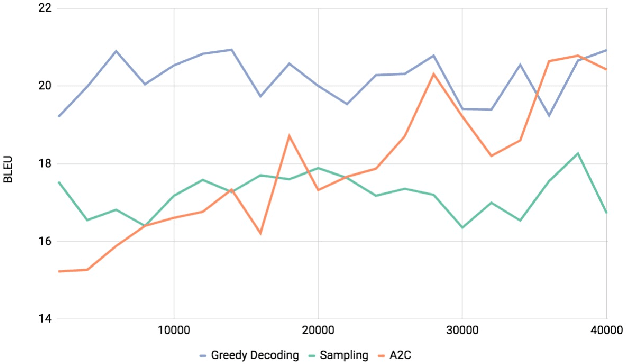
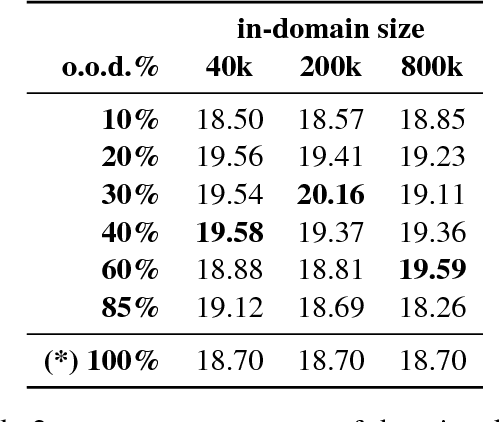

We describe the University of Maryland machine translation systems submitted to the WMT17 German-English Bandit Learning Task. The task is to adapt a translation system to a new domain, using only bandit feedback: the system receives a German sentence to translate, produces an English sentence, and only gets a scalar score as feedback. Targeting these two challenges (adaptation and bandit learning), we built a standard neural machine translation system and extended it in two ways: (1) robust reinforcement learning techniques to learn effectively from the bandit feedback, and (2) domain adaptation using data selection from a large corpus of parallel data.