 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFT: From Robustness Gaps to Invariance Manifolds for AI-Generated Image Detection
Jun 05, 2026The rapid evolution of generative image models challenges existing AI-generated image detectors, particularly in open-world settings with unseen generators. Recent training-free approaches measure robustness gaps in frozen vision foundation models (VFMs), detecting fakes via perturbation-induced embedding drift. However, these methods rely on fixed invariance geometry inherited from pretraining and lack principled adaptation to the detection task. We instead formulate AI-generated image detection as learning a structured invariance manifold of real images under one-class supervision. Building upon a frozen VFM, we introduce lightweight projection heads that decompose representation space into complementary robust and fragile subspaces. The robust subspace is explicitly trained to suppress variations induced by physically plausible imaging transformations, approximating tangent directions of a real-image manifold, while the fragile subspace retains sensitivity to edit-like perturbations. A structured ordering margin enforces hierarchical separation between physical invariance and edit-induced variability, enabling detection as a margin-violation test relative to the learned manifold. At inference, multi-scale patch-wise drift under both transformation families yields a dual-channel invariance signature and interpretable localization. Extensive experiments demonstrate strong open-world generalization across unseen generators and resolutions, consistently outperforming training-free robustness-based baselines while providing interpretable invariance-violation maps.
Geodesic Flow Matching on a Riemannian Degradation Manifold for Blind Image Restoration
Jun 04, 2026Blind image restoration requires recovering clean images from observations corrupted by unknown and potentially mixed degradations. While recent deterministic flow-based methods model restoration as transport processes that map degraded images to clean ones, they typically rely on Euclidean interpolation, implicitly assuming linear degradation geometry. In this paper, we explicitly model degradations as points on a low-dimensional Riemannian manifold and formulate restoration as geodesic transport on the joint image-manifold space. Using a geodesic flow matching objective, we learn intrinsic transport dynamics that respect the curvature of degradation space. This framework generalizes linear flow matching, provides a principled treatment of mixed degradations as geodesic compositions, and yields a clean theoretical interpretation for generalization beyond observed degradations.
NanoSD: Edge Efficient Foundation Model for Real Time Image Restoration
Jan 16, 2026Latent diffusion models such as Stable Diffusion 1.5 offer strong generative priors that are highly valuable for image restoration, yet their full pipelines remain too computationally heavy for deployment on edge devices. Existing lightweight variants predominantly compress the denoising U-Net or reduce the diffusion trajectory, which disrupts the underlying latent manifold and limits generalization beyond a single task. We introduce NanoSD, a family of Pareto-optimal diffusion foundation models distilled from Stable Diffusion 1.5 through network surgery, feature-wise generative distillation, and structured architectural scaling jointly applied to the U-Net and the VAE encoder-decoder. This full-pipeline co-design preserves the generative prior while producing models that occupy distinct operating points along the accuracy-latency-size frontier (e.g., 130M-315M parameters, achieving real-time inference down to 20ms on mobile-class NPUs). We show that parameter reduction alone does not correlate with hardware efficiency, and we provide an analysis revealing how architectural balance, feature routing, and latent-space preservation jointly shape true on-device latency. When used as a drop-in backbone, NanoSD enables state-of-the-art performance across image super-resolution, image deblurring, face restoration, and monocular depth estimation, outperforming prior lightweight diffusion models in both perceptual quality and practical deployability. NanoSD establishes a general-purpose diffusion foundation model family suitable for real-time visual generation and restoration on edge devices.
CodeFormer++: Blind Face Restoration Using Deformable Registration and Deep Metric Learning
Oct 06, 2025



Blind face restoration (BFR) has attracted increasing attention with the rise of generative methods. Most existing approaches integrate generative priors into the restoration pro- cess, aiming to jointly address facial detail generation and identity preservation. However, these methods often suffer from a trade-off between visual quality and identity fidelity, leading to either identity distortion or suboptimal degradation removal. In this paper, we present CodeFormer++, a novel framework that maximizes the utility of generative priors for high-quality face restoration while preserving identity. We decompose BFR into three sub-tasks: (i) identity- preserving face restoration, (ii) high-quality face generation, and (iii) dynamic fusion of identity features with realistic texture details. Our method makes three key contributions: (1) a learning-based deformable face registration module that semantically aligns generated and restored faces; (2) a texture guided restoration network to dynamically extract and transfer the texture of generated face to boost the quality of identity-preserving restored face; and (3) the integration of deep metric learning for BFR with the generation of informative positive and hard negative samples to better fuse identity- preserving and generative features. Extensive experiments on real-world and synthetic datasets demonstrate that, the pro- posed CodeFormer++ achieves superior performance in terms of both visual fidelity and identity consistency.
Joint Flow And Feature Refinement Using Attention For Video Restoration
May 22, 2025Recent advancements in video restoration have focused on recovering high-quality video frames from low-quality inputs. Compared with static images, the performance of video restoration significantly depends on efficient exploitation of temporal correlations among successive video frames. The numerous techniques make use of temporal information via flow-based strategies or recurrent architectures. However, these methods often encounter difficulties in preserving temporal consistency as they utilize degraded input video frames. To resolve this issue, we propose a novel video restoration framework named Joint Flow and Feature Refinement using Attention (JFFRA). The proposed JFFRA is based on key philosophy of iteratively enhancing data through the synergistic collaboration of flow (alignment) and restoration. By leveraging previously enhanced features to refine flow and vice versa, JFFRA enables efficient feature enhancement using temporal information. This interplay between flow and restoration is executed at multiple scales, reducing the dependence on precise flow estimation. Moreover, we incorporate an occlusion-aware temporal loss function to enhance the network's capability in eliminating flickering artifacts. Comprehensive experiments validate the versatility of JFFRA across various restoration tasks such as denoising, deblurring, and super-resolution. Our method demonstrates a remarkable performance improvement of up to 1.62 dB compared to state-of-the-art approaches.
MOTS R-CNN: Cosine-margin-triplet loss for multi-object tracking
Feb 06, 2021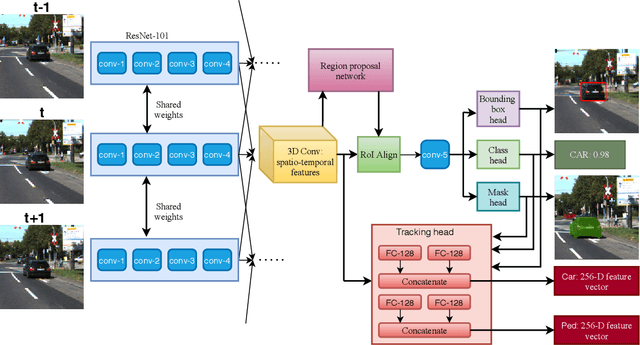



One of the central tasks of multi-object tracking involves learning a distance metric that is consistent with the semantic similarities of objects. The design of an appropriate loss function that encourages discriminative feature learning is among the most crucial challenges in deep neural network-based metric learning. Despite significant progress, slow convergence and a poor local optimum of the existing contrastive and triplet loss based deep metric learning methods necessitates a better solution. In this paper, we propose cosine-margin-contrastive (CMC) and cosine-margin-triplet (CMT) loss by reformulating both contrastive and triplet loss functions from the perspective of cosine distance. The proposed reformulation as a cosine loss is achieved by feature normalization which distributes the learned features on a hypersphere. We then propose the MOTS R-CNN framework for joint multi-object tracking and segmentation, particularly targeted at improving the tracking performance. Specifically, the tracking problem is addressed through deep metric learning based on the proposed loss functions. We propose a scale-invariant tracking by using a multi-layer feature aggregation scheme to make the model robust against object scale variations and occlusions. The MOTS R-CNN achieves the state-of-the-art tracking performance on the KITTI MOTS dataset. We show that the MOTS R-CNN reduces the identity switching by $62\%$ and $61\%$ on cars and pedestrians, respectively in comparison to Track R-CNN.