 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging AI to Accelerate Clinical Data Cleaning: A Comparative Study of AI-Assisted vs. Traditional Methods
Aug 07, 2025



Clinical trial data cleaning represents a critical bottleneck in drug development, with manual review processes struggling to manage exponentially increasing data volumes and complexity. This paper presents Octozi, an artificial intelligence-assisted platform that combines large language models with domain-specific heuristics to transform clinical data review. In a controlled experimental study with experienced clinical reviewers (n=10), we demonstrate that AI assistance increased data cleaning throughput by 6.03-fold while simultaneously decreasing cleaning errors from 54.67% to 8.48% (a 6.44-fold improvement). Crucially, the system reduced false positive queries by 15.48-fold, minimizing unnecessary site burden. These improvements were consistent across reviewers regardless of experience level, suggesting broad applicability. Our findings indicate that AI-assisted approaches can address fundamental inefficiencies in clinical trial operations, potentially accelerating drug development timelines and reducing costs while maintaining regulatory compliance. This work establishes a framework for integrating AI into safety-critical clinical workflows and demonstrates the transformative potential of human-AI collaboration in pharmaceutical clinical trials.
BAMAX: Backtrack Assisted Multi-Agent Exploration using Reinforcement Learning
Nov 13, 2024Autonomous robots collaboratively exploring an unknown environment is still an open problem. The problem has its roots in coordination among non-stationary agents, each with only a partial view of information. The problem is compounded when the multiple robots must completely explore the environment. In this paper, we introduce Backtrack Assisted Multi-Agent Exploration using Reinforcement Learning (BAMAX), a method for collaborative exploration in multi-agent systems which attempts to explore an entire virtual environment. As in the name, BAMAX leverages backtrack assistance to enhance the performance of agents in exploration tasks. To evaluate BAMAX against traditional approaches, we present the results of experiments conducted across multiple hexagonal shaped grids sizes, ranging from 10x10 to 60x60. The results demonstrate that BAMAX outperforms other methods in terms of faster coverage and less backtracking across these environments.
Reinforcement Learning approach for Real Time Strategy Games Battle city and S3
Feb 16, 2016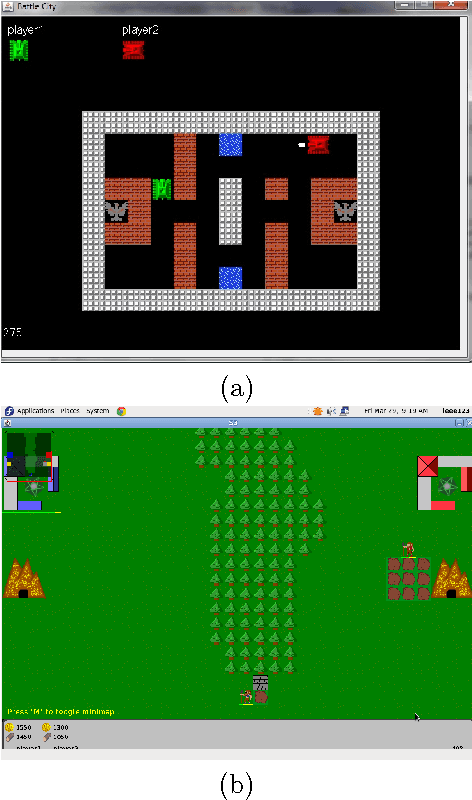
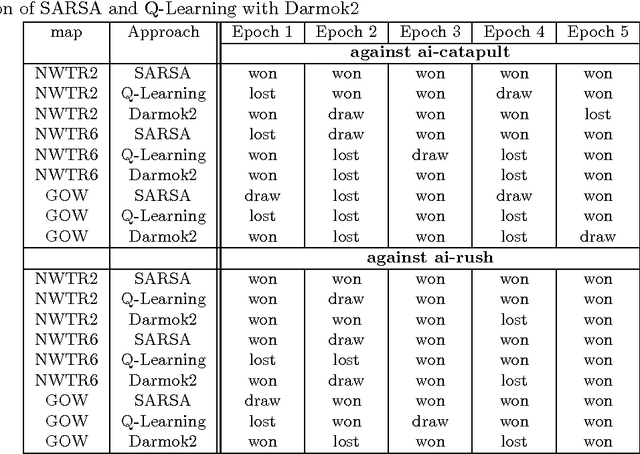
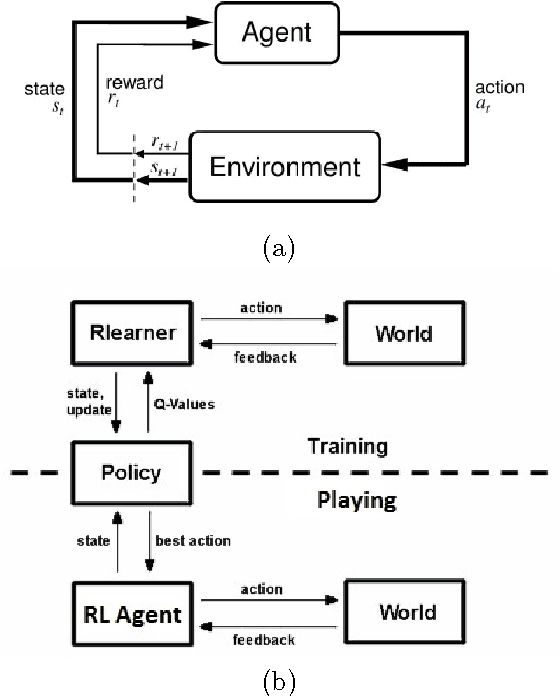
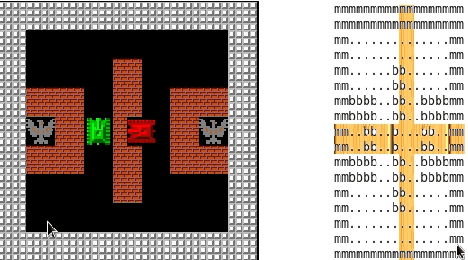
In this paper we proposed reinforcement learning algorithms with the generalized reward function. In our proposed method we use Q-learning and SARSA algorithms with generalised reward function to train the reinforcement learning agent. We evaluated the performance of our proposed algorithms on two real-time strategy games called BattleCity and S3. There are two main advantages of having such an approach as compared to other works in RTS. (1) We can ignore the concept of a simulator which is often game specific and is usually hard coded in any type of RTS games (2) our system can learn from interaction with any opponents and quickly change the strategy according to the opponents and do not need any human traces as used in previous works. Keywords : Reinforcement learning, Machine learning, Real time strategy, Artificial intelligence.