 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do the US West Coast Public Libraries Post on Twitter?
Sep 28, 2018
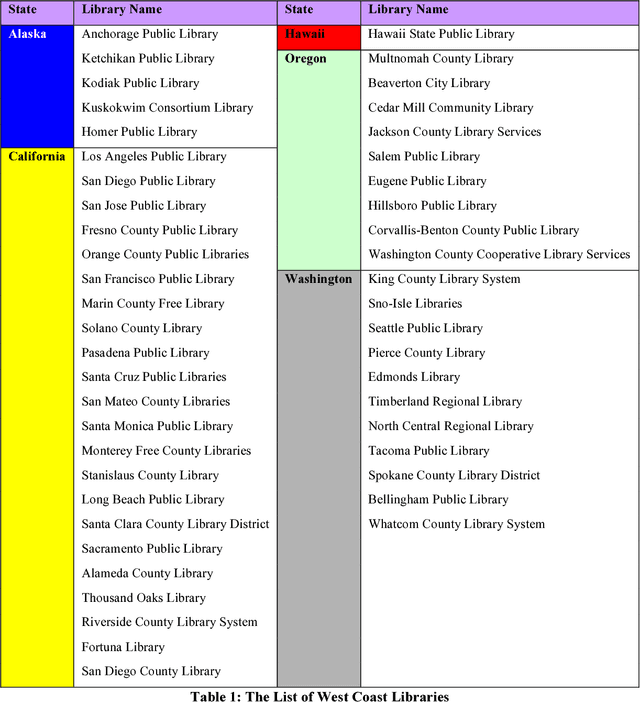
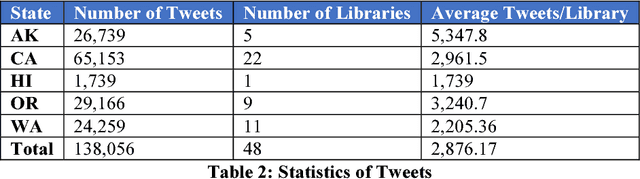
Twitter has provided a great opportunity for public libraries to disseminate information for a variety of purposes. Twitter data have been applied in different domains such as health, politics, and history. There are thousands of public libraries in the US, but no study has yet investigated the content of their social media posts like tweets to find their interests. Moreover, traditional content analysis of Twitter content is not an efficient task for exploring thousands of tweets. Therefore, there is a need for automatic methods to overcome the limitations of manual methods. This paper proposes a computational approach to collecting and analyzing using Twitter Application Programming Interfaces (API) and investigates more than 138,000 tweets from 48 US west coast libraries using topic modeling. We found 20 topics and assigned them to five categories including public relations, book, event, training, and social good. Our results show that the US west coast libraries are more interested in using Twitter for public relations and book-related events. This research has both practical and theoretical applications for libraries as well as other organizations to explore social media actives of their customer and themselves.
Characterizing Transgender Health Issues in Twitter
Sep 28, 2018

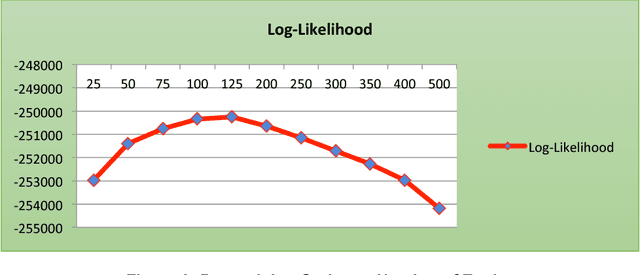
Although there are millions of transgender people in the world, a lack of information exists about their health issues. This issue has consequences for the medical field, which only has a nascent understanding of how to identify and meet this population's health-related needs. Social media sites like Twitter provide new opportunities for transgender people to overcome these barriers by sharing their personal health experiences. Our research employs a computational framework to collect tweets from self-identified transgender users, detect those that are health-related, and identify their information needs. This framework is significant because it provides a macro-scale perspective on an issue that lacks investigation at national or demographic levels. Our findings identified 54 distinct health-related topics that we grouped into 7 broader categories. Further, we found both linguistic and topical differences in the health-related information shared by transgender men (TM) as com-pared to transgender women (TW). These findings can help inform medical and policy-based strategies for health interventions within transgender communities. Also, our proposed approach can inform the development of computational strategies to identify the health-related information needs of other marginalized populations.
Computational Analysis of Insurance Complaints: GEICO Case Study
Jun 26, 2018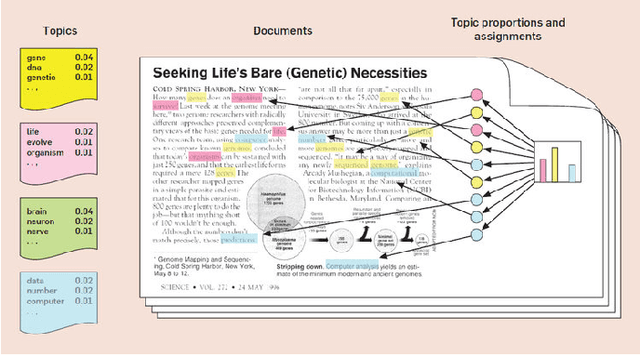
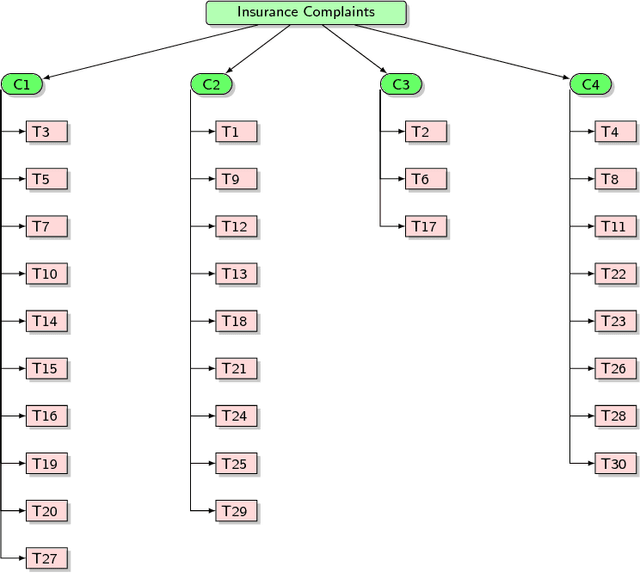
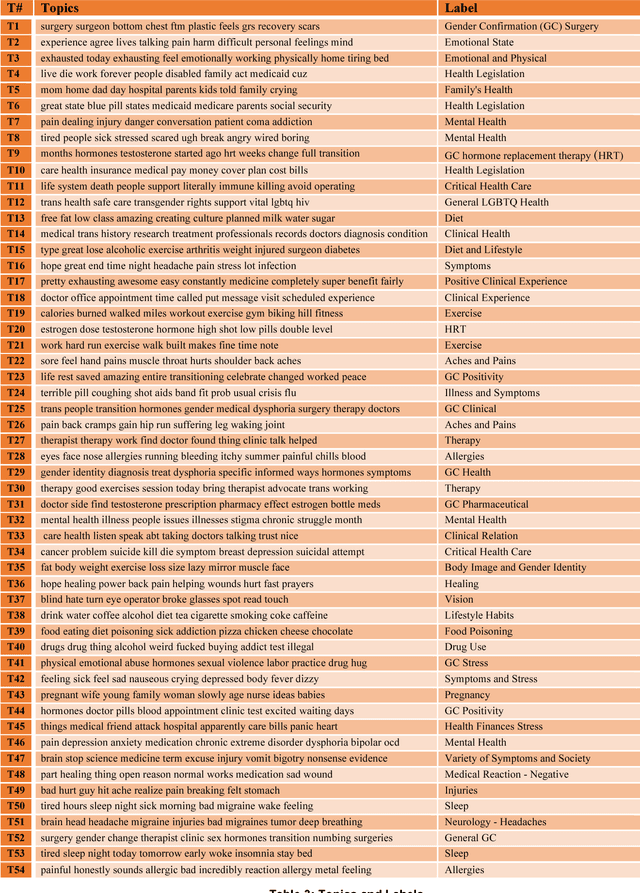
The online environment has provided a great opportunity for insurance policyholders to share their complaints with respect to different services. These complaints can reveal valuable information for insurance companies who seek to improve their services; however, analyzing a huge number of online complaints is a complicated task for human and must involve computational methods to create an efficient process. This research proposes a computational approach to characterize the major topics of a large number of online complaints. Our approach is based on using the topic modeling approach to disclose the latent semantic of complaints. The proposed approach deployed on thousands of GEICO negative reviews. Analyzing 1,371 GEICO complaints indicates that there are 30 major complains in four categories: (1) customer service, (2) insurance coverage, paperwork, policy, and reports, (3) legal issues, and (4) costs, estimates, and payments. This research approach can be used in other applications to explore a large number of reviews.
Characterizing Diseases and disorders in Gay Users' tweets
Mar 24, 2018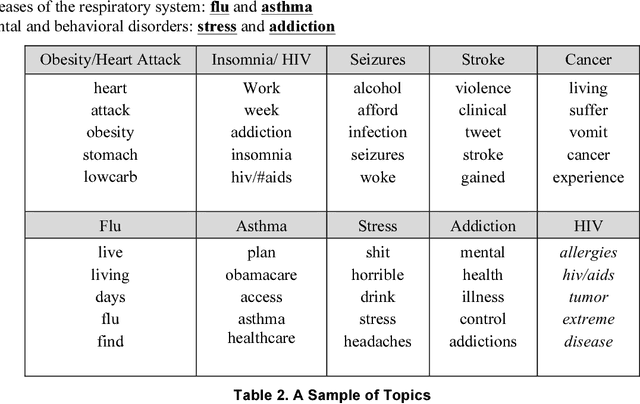
A lack of information exists about the health issues of lesbian, gay, bisexual, transgender, and queer (LGBTQ) people who are often excluded from national demographic assessments, health studies, and clinical trials. As a result, medical experts and researchers lack a holistic understanding of the health disparities facing these populations. Fortunately, publicly available social media data such as Twitter data can be utilized to support the decisions of public health policy makers and managers with respect to LGBTQ people. This research employs a computational approach to collect tweets from gay users on health-related topics and model these topics. To determine the nature of health-related information shared by men who have sex with men on Twitter, we collected thousands of tweets from 177 active users. We sampled these tweets using a framework that can be applied to other LGBTQ sub-populations in future research. We found 11 diseases in 7 categories based on ICD 10 that are in line with the published studies and official reports.
Social Media Analysis For Organizations: Us Northeastern Public And State Libraries Case Study
Mar 24, 2018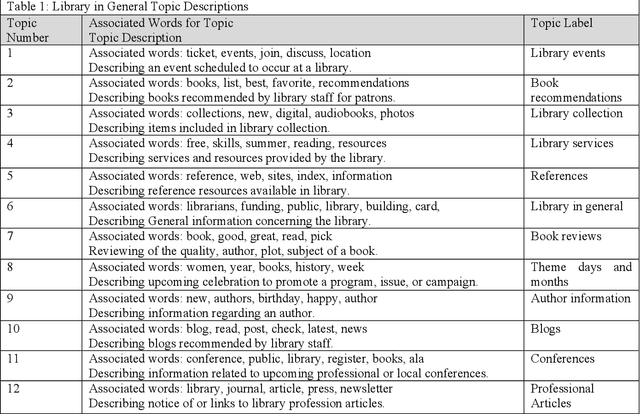
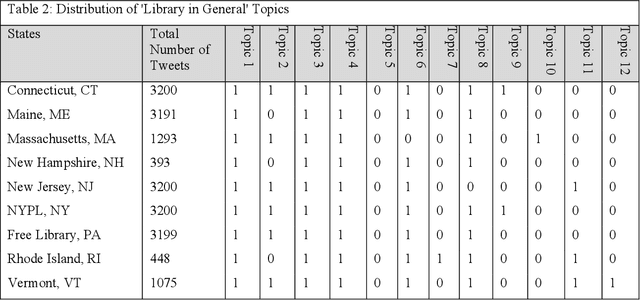
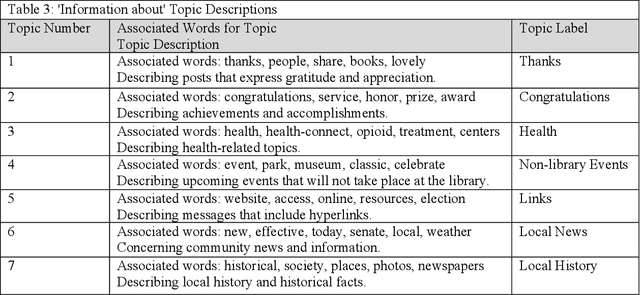
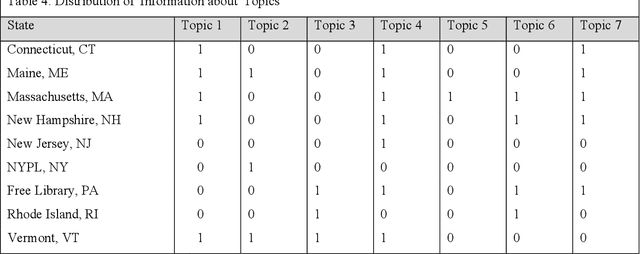
Social networking sites such as Twitter have provided a great opportunity for organizations such as public libraries to disseminate information for public relations purposes. However, there is a need to analyze vast amounts of social media data. This study presents a computational approach to explore the content of tweets posted by nine public libraries in the northeastern United States of America. In December 2017, this study extracted more than 19,000 tweets from the Twitter accounts of seven state libraries and two urban public libraries. Computational methods were applied to collect the tweets and discover meaningful themes. This paper shows how the libraries have used Twitter to represent their services and provides a starting point for different organizations to evaluate the themes of their public tweets.
Mining Public Opinion about Economic Issues: Twitter and the U.S. Presidential Election
Feb 06, 2018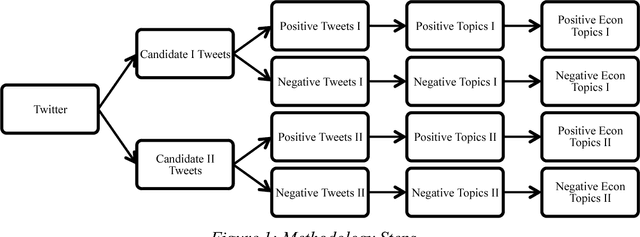
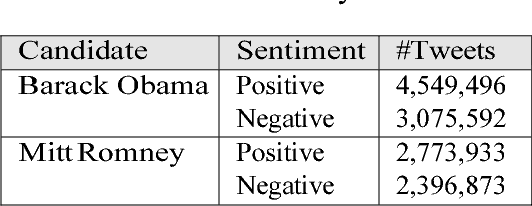
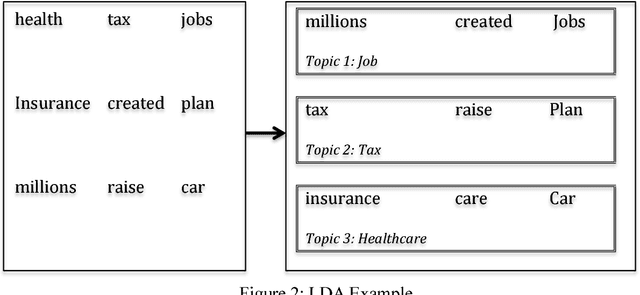
Opinion polls have been the bridge between public opinion and politicians in elections. However, developing surveys to disclose people's feedback with respect to economic issues is limited, expensive, and time-consuming. In recent years, social media such as Twitter has enabled people to share their opinions regarding elections. Social media has provided a platform for collecting a large amount of social media data. This paper proposes a computational public opinion mining approach to explore the discussion of economic issues in social media during an election. Current related studies use text mining methods independently for election analysis and election prediction; this research combines two text mining methods: sentiment analysis and topic modeling. The proposed approach has effectively been deployed on millions of tweets to analyze economic concerns of people during the 2012 US presidential election.
Taming Wild High Dimensional Text Data with a Fuzzy Lash
Dec 16, 2017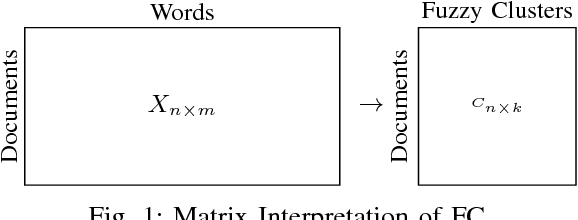

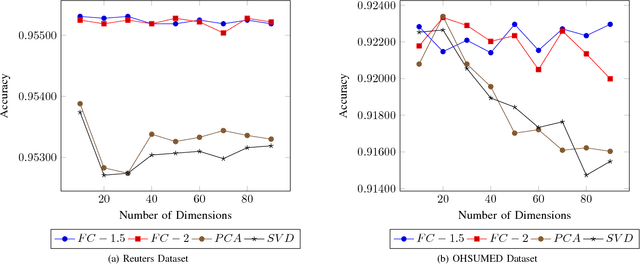

The bag of words (BOW) represents a corpus in a matrix whose elements are the frequency of words. However, each row in the matrix is a very high-dimensional sparse vector. Dimension reduction (DR) is a popular method to address sparsity and high-dimensionality issues. Among different strategies to develop DR method, Unsupervised Feature Transformation (UFT) is a popular strategy to map all words on a new basis to represent BOW. The recent increase of text data and its challenges imply that DR area still needs new perspectives. Although a wide range of methods based on the UFT strategy has been developed, the fuzzy approach has not been considered for DR based on this strategy. This research investigates the application of fuzzy clustering as a DR method based on the UFT strategy to collapse BOW matrix to provide a lower-dimensional representation of documents instead of the words in a corpus. The quantitative evaluation shows that fuzzy clustering produces superior performance and features to Principal Components Analysis (PCA) and Singular Value Decomposition (SVD), two popular DR methods based on the UFT strategy.
Characterizing Diabetes, Diet, Exercise, and Obesity Comments on Twitter
Sep 22, 2017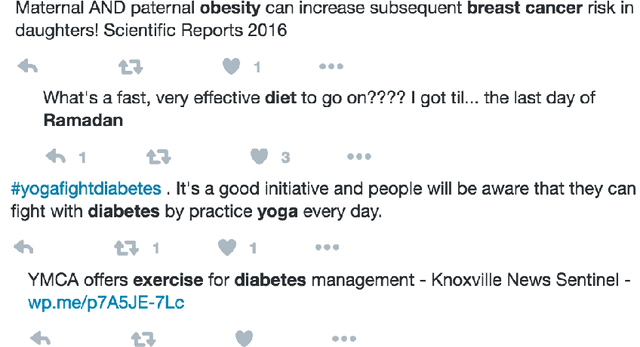

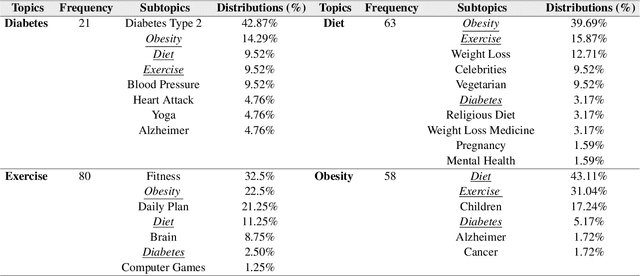
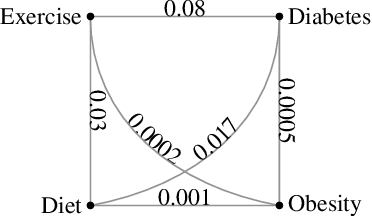
Social media provide a platform for users to express their opinions and share information. Understanding public health opinions on social media, such as Twitter, offers a unique approach to characterizing common health issues such as diabetes, diet, exercise, and obesity (DDEO), however, collecting and analyzing a large scale conversational public health data set is a challenging research task. The goal of this research is to analyze the characteristics of the general public's opinions in regard to diabetes, diet, exercise and obesity (DDEO) as expressed on Twitter. A multi-component semantic and linguistic framework was developed to collect Twitter data, discover topics of interest about DDEO, and analyze the topics. From the extracted 4.5 million tweets, 8% of tweets discussed diabetes, 23.7% diet, 16.6% exercise, and 51.7% obesity. The strongest correlation among the topics was determined between exercise and obesity. Other notable correlations were: diabetes and obesity, and diet and obesity DDEO terms were also identified as subtopics of each of the DDEO topics. The frequent subtopics discussed along with Diabetes, excluding the DDEO terms themselves, were blood pressure, heart attack, yoga, and Alzheimer. The non-DDEO subtopics for Diet included vegetarian, pregnancy, celebrities, weight loss, religious, and mental health, while subtopics for Exercise included computer games, brain, fitness, and daily plan. Non-DDEO subtopics for Obesity included Alzheimer, cancer, and children. With 2.67 billion social media users in 2016, publicly available data such as Twitter posts can be utilized to support clinical providers, public health experts, and social scientists in better understanding common public opinions in regard to diabetes, diet, exercise, and obesity.
Computational Content Analysis of Negative Tweets for Obesity, Diet, Diabetes, and Exercise
Sep 22, 2017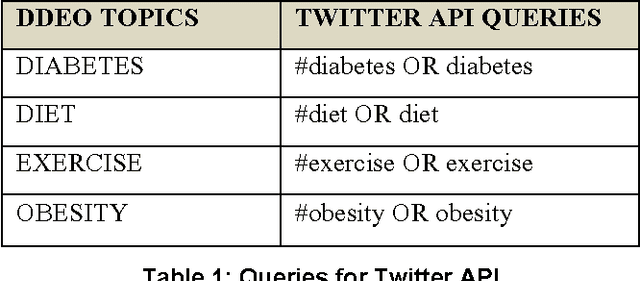
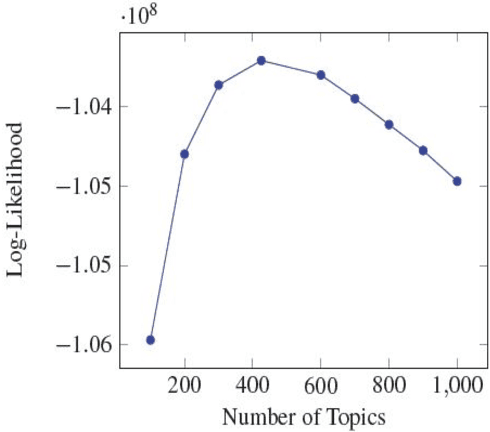
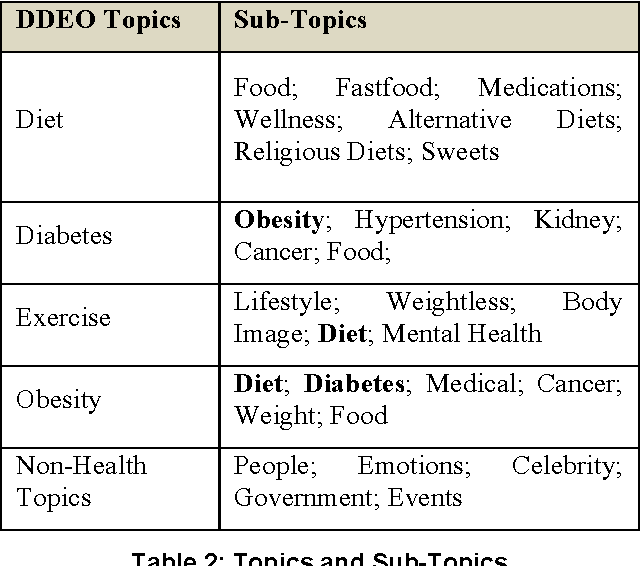
Social media based digital epidemiology has the potential to support faster response and deeper understanding of public health related threats. This study proposes a new framework to analyze unstructured health related textual data via Twitter users' post (tweets) to characterize the negative health sentiments and non-health related concerns in relations to the corpus of negative sentiments, regarding Diet Diabetes Exercise, and Obesity (DDEO). Through the collection of 6 million Tweets for one month, this study identified the prominent topics of users as it relates to the negative sentiments. Our proposed framework uses two text mining methods, sentiment analysis and topic modeling, to discover negative topics. The negative sentiments of Twitter users support the literature narratives and the many morbidity issues that are associated with DDEO and the linkage between obesity and diabetes. The framework offers a potential method to understand the publics' opinions and sentiments regarding DDEO. More importantly, this research provides new opportunities for computational social scientists, medical experts, and public health professionals to collectively address DDEO-related issues.
Fuzzy Approach Topic Discovery in Health and Medical Corpora
May 26, 2017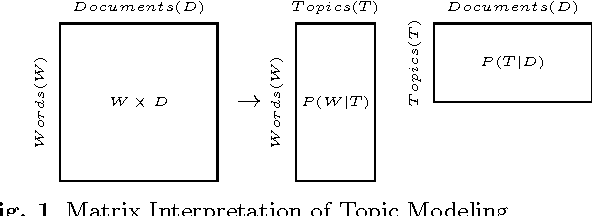
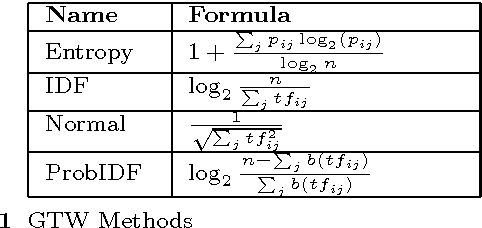
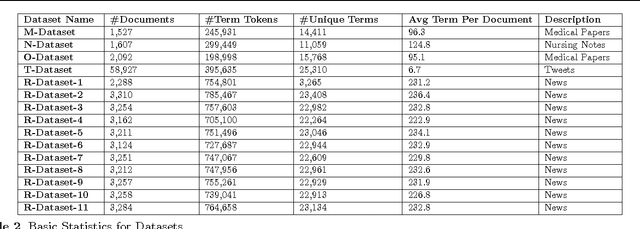
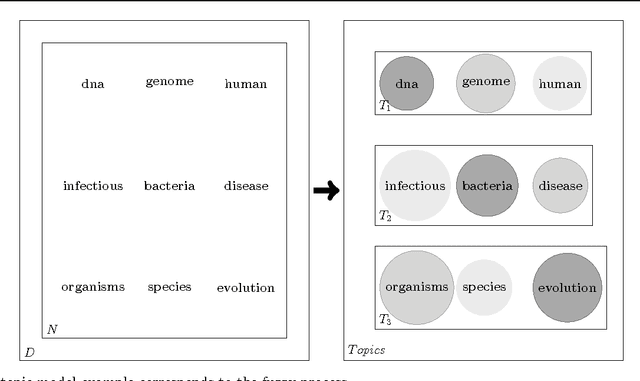
The majority of medical documents and electronic health records (EHRs) are in text format that poses a challenge for data processing and finding relevant documents. Looking for ways to automatically retrieve the enormous amount of health and medical knowledge has always been an intriguing topic. Powerful methods have been developed in recent years to make the text processing automatic. One of the popular approaches to retrieve information based on discovering the themes in health & medical corpora is topic modeling, however, this approach still needs new perspectives. In this research we describe fuzzy latent semantic analysis (FLSA), a novel approach in topic modeling using fuzzy perspective. FLSA can handle health & medical corpora redundancy issue and provides a new method to estimate the number of topics. The quantitative evaluations show that FLSA produces superior performance and features to latent Dirichlet allocation (LDA), the most popular topic model.