 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnerQ: Hardware-aware Tuning-free Quantization of KV Cache for Large Language Models
Feb 26, 2026Reducing the hardware footprint of large language models (LLMs) during decoding is critical for efficient long-sequence generation. A key bottleneck is the key-value (KV) cache, whose size scales with sequence length and easily dominates the memory footprint of the model. Previous work proposed quantization methods that are focused on compressing the KV cache while maintaining its information. We introduce InnerQ, a hardware-aware KV-cache quantization scheme that lowers decode latency without sacrificing accuracy. InnerQ applies group-wise quantization while grouping the cache matrices over their inner dimension. Unlike previous work that group over the outer dimension, InnerQ aligns dequantization with the vector-matrix multiplication and enables scale factor reuse across GPU compute units. This reduces memory accesses and accelerates dequantization, yielding up to $22\%$ speedup over previous work and up to $88\%$ over half-precision vector-matrix multiplication. To preserve fidelity under aggressive compression, InnerQ incorporates (i) hybrid quantization, selecting symmetric or asymmetric quantization per group based on local statistics; (ii) high-precision windows for both the most recent tokens and the attention sink tokens to mitigate outlier leakage; and (iii) per-channel normalization of the key cache, computed once during prefill and folded into the query to avoid runtime overhead. Our evaluation experiments on Llama models shows that InnerQ maintains a few-shot GSM8K performance comparable to non-quantized KV caches and surpasses prior KV cache quantization methods.
Standard Deviation-Based Quantization for Deep Neural Networks
Feb 24, 2022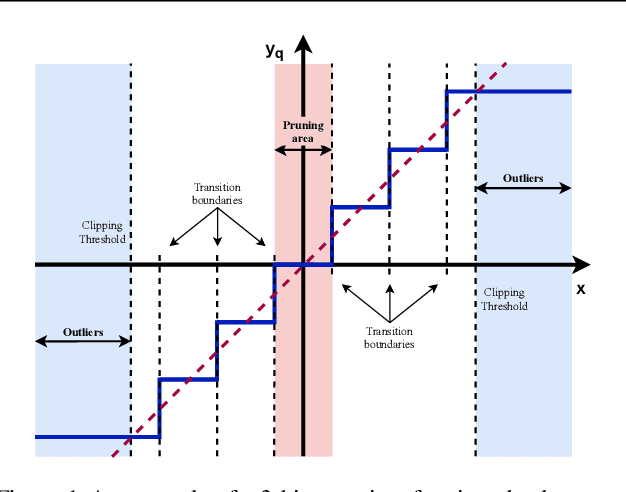
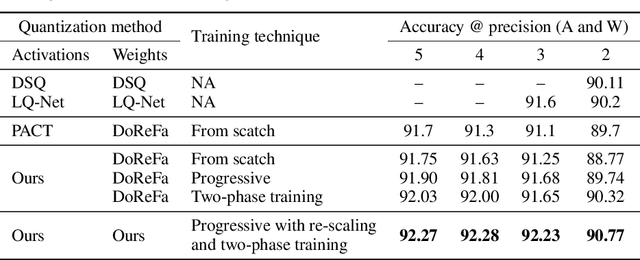
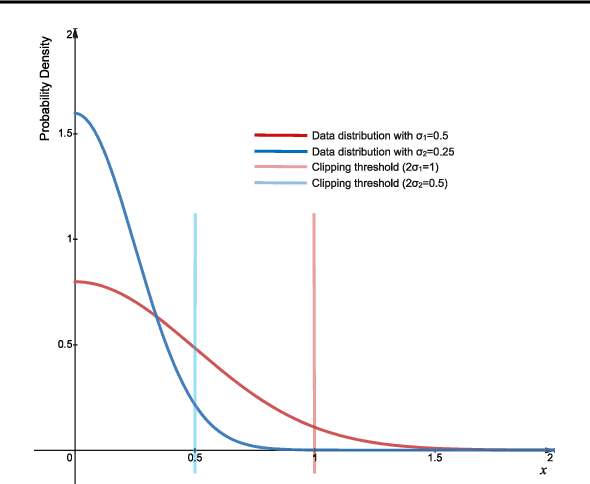
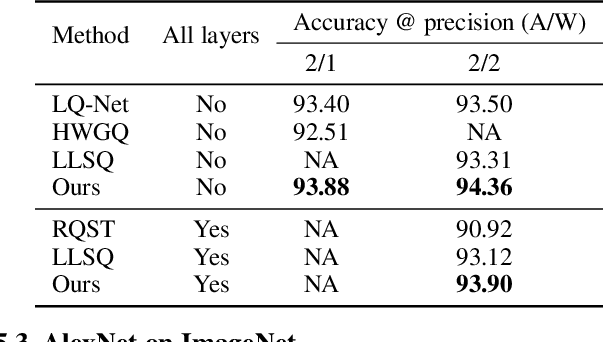
Quantization of deep neural networks is a promising approach that reduces the inference cost, making it feasible to run deep networks on resource-restricted devices. Inspired by existing methods, we propose a new framework to learn the quantization intervals (discrete values) using the knowledge of the network's weight and activation distributions, i.e., standard deviation. Furthermore, we propose a novel base-2 logarithmic quantization scheme to quantize weights to power-of-two discrete values. Our proposed scheme allows us to replace resource-hungry high-precision multipliers with simple shift-add operations. According to our evaluations, our method outperforms existing work on CIFAR10 and ImageNet datasets and even achieves better accuracy performance with 3-bit weights and activations when compared to the full-precision models. Moreover, our scheme simultaneously prunes the network's parameters and allows us to flexibly adjust the pruning ratio during the quantization process.