 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Input Resolution on Retinal Vessel Segmentation Performance: An Empirical Study Across Five Datasets
Apr 03, 2026Most deep learning pipelines for retinal vessel segmentation resize fundus images to satisfy GPU memory constraints and enable uniform batch processing. However, the impact of this resizing on thin vessel detection remains underexplored. When high resolution images are downsampled, thin vessels are reduced to subpixel structures, causing irreversible information loss even before the data enters the network. Standard volumetric metrics such as the Dice score do not capture this loss because thick vessel pixels dominate the evaluation. We investigated this effect by training a baseline UNet at multiple downsampling ratios across five fundus datasets (DRIVE, STARE, CHASE_DB1, HRF, and FIVES) with native widths ranging from 565 to 3504 pixels, keeping all other settings fixed. We introduce a width-stratified sensitivity metric that evaluates thin (half-width <3 pixels), medium (3 to 7 pixels), and thick (>7 pixels) vessel detection separately, using native resolution width estimates derived from a Euclidean distance transform. Results show that for high-resolution datasets (HRF, FIVES), thin vessel sensitivity improves monotonically as images are downsampled toward the encoder's effective operating range, peaking at processed widths between 256 and 876 pixels. For low-to-mid resolution datasets (DRIVE, STARE, CHASE_DB1), thin vessel sensitivity is highest at or near native resolution and degrades with any downsampling. Across all five datasets, aggressive downsampling reduced thin vessel sensitivity by up to 15.8 percentage points (DRIVE) while Dice remained relatively stable, confirming that Dice alone is insufficient for evaluating microvascular segmentation.
HMS-VesselNet: Hierarchical Multi-Scale Attention Network with Topology-Preserving Loss for Retinal Vessel Segmentation
Mar 23, 2026Retinal vessel segmentation methods based on standard overlap losses tend to miss thin peripheral vessels because these structures occupy very few pixels and have low contrast against the background. We propose HMS-VesselNet, a hierarchical multi-scale network that processes fundus images across four parallel branches at different resolutions and combines their outputs using learned fusion weights. The training loss combines Dice, binary cross-entropy, and centerline Dice to jointly optimize area overlap and vessel continuity. Hard example mining is applied from epoch 20 onward to concentrate gradient updates on the most difficult training images. Tested on 68 images from DRIVE, STARE, and CHASE_DB1 using 5-fold cross-validation, the model achieves a mean Dice of 88.72 +/- 0.67%, Sensitivity of 90.78 +/- 1.42%, and AUC of 98.25 +/- 0.21%. In leave-one-dataset-out experiments, AUC remains above 95% on each unseen dataset. The largest improvement is in the recall of thin peripheral vessels, which are the structures most frequently missed by standard methods and most critical for early detection of diabetic retinopathy.
Word and character segmentation directly in run-length compressed handwritten document images
Aug 18, 2019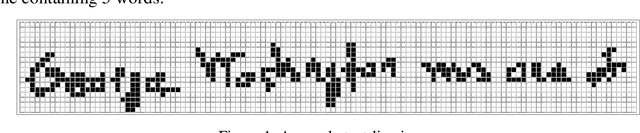
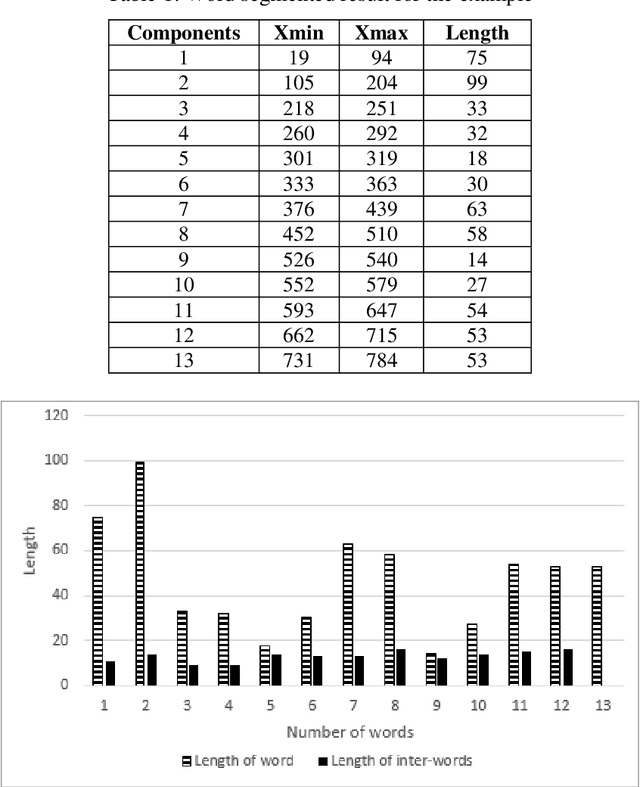
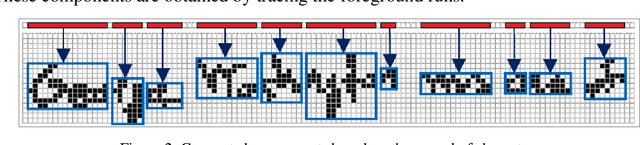
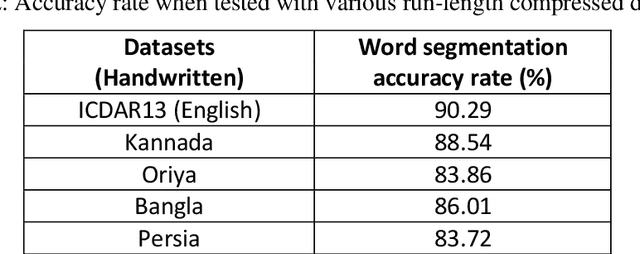
From the literature, it is demonstrated that performing text-line segmentation directly in the run-length compressed handwritten document images significantly reduces the computational time and memory space. In this paper, we investigate the issues of word and character segmentation directly on the run-length compressed document images. Primarily, the spreads of the characters are intelligently extracted from the foreground runs of the compressed data and subsequently connected components are established. The spacing between the connected components would be larger between the adjacent words when compared to that of intra-words. With this knowledge, a threshold is empirically chosen for inter-word separation. Every connected component within a word is further analysed for character segmentation. Here, min-cut graph concept is used for separating the touching characters. Over-segmentation and under-segmentation issues are addressed by insertion and deletion operations respectively. The approach has been developed particularly for compressed handwritten English document images. However, the model has been tested on non-English document images.
Spotting Separator Points at Line Terminals in Compressed Document Images for Text-line Segmentation
Aug 18, 2017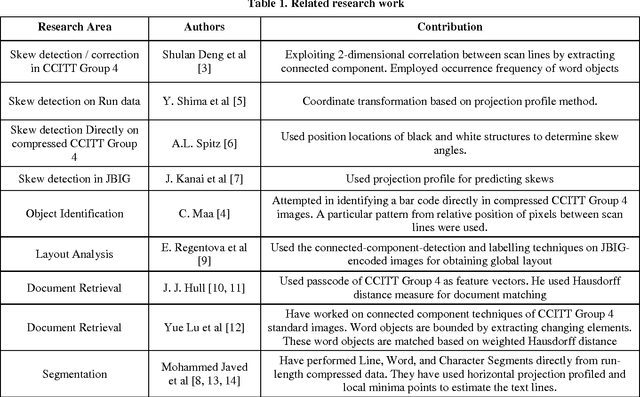
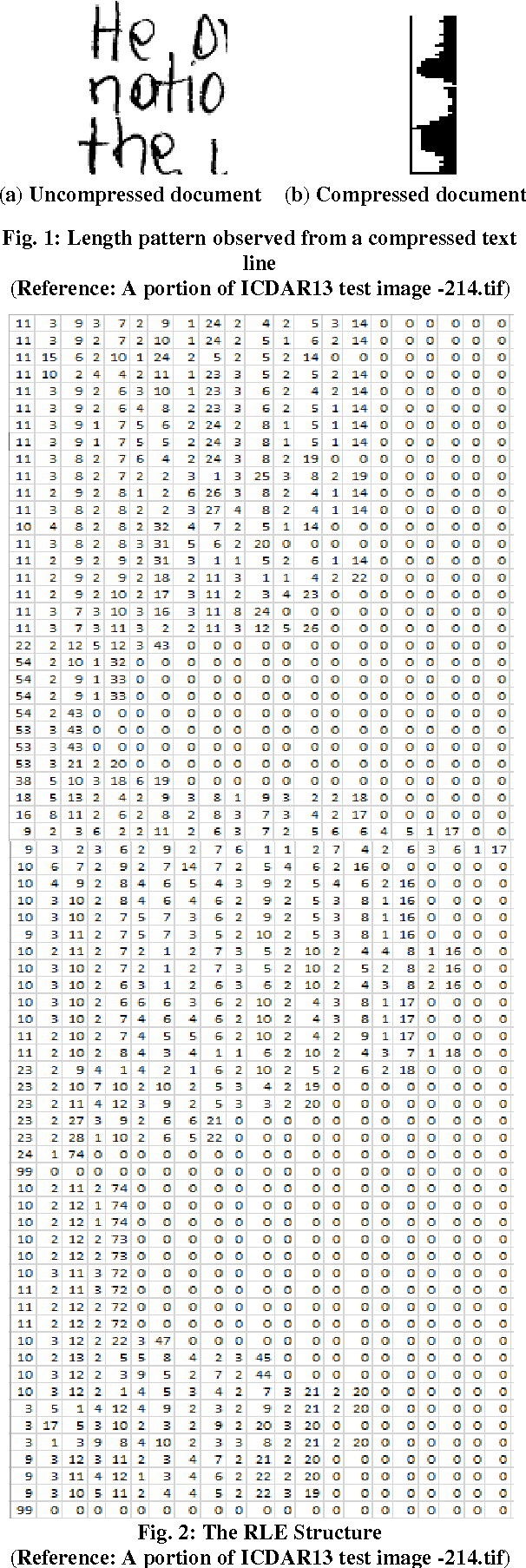
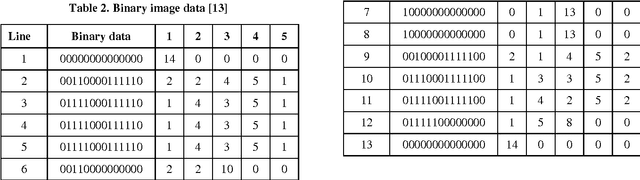
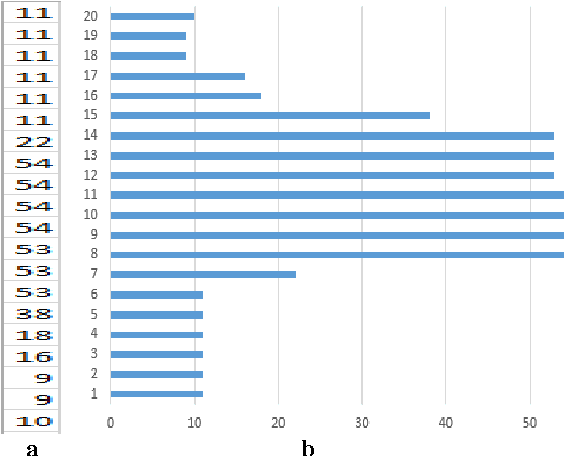
Line separators are used to segregate text-lines from one another in document image analysis. Finding the separator points at every line terminal in a document image would enable text-line segmentation. In particular, identifying the separators in handwritten text could be a thrilling exercise. Obviously it would be challenging to perform this in the compressed version of a document image and that is the proposed objective in this research. Such an effort would prevent the computational burden of decompressing a document for text-line segmentation. Since document images are generally compressed using run length encoding (RLE) technique as per the CCITT standards, the first column in the RLE will be a white column. The value (depth) in the white column is very low when a particular line is a text line and the depth could be larger at the point of text line separation. A longer consecutive sequence of such larger depth should indicate the gap between the text lines, which provides the separator region. In case of over separation and under separation issues, corrective actions such as deletion and insertion are suggested respectively. An extensive experimentation is conducted on the compressed images of the benchmark datasets of ICDAR13 and Alireza et al [17] to demonstrate the efficacy.
* Line separators, Document image analysis, Handwritten text, Compression and decompression, RLE, CCITT. Line separator points at every line terminal in a compressed handwritten document images enabling text line segmentation