 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUBE: A Standard for Unifying Agent Benchmarks
Mar 16, 2026The proliferation of agent benchmarks has created critical fragmentation that threatens research productivity. Each new benchmark requires substantial custom integration, creating an "integration tax" that limits comprehensive evaluation. We propose CUBE (Common Unified Benchmark Environments), a universal protocol standard built on MCP and Gym that allows benchmarks to be wrapped once and used everywhere. By separating task, benchmark, package, and registry concerns into distinct API layers, CUBE enables any compliant platform to access any compliant benchmark for evaluation, RL training, or data generation without custom integration. We call on the community to contribute to the development of this standard before platform-specific implementations deepen fragmentation as benchmark production accelerates through 2026.
Just-in-time Episodic Feedback Hinter: Leveraging Offline Knowledge to Improve LLM Agents Adaptation
Oct 05, 2025



Large language model (LLM) agents perform well in sequential decision-making tasks, but improving them on unfamiliar domains often requires costly online interactions or fine-tuning on large expert datasets. These strategies are impractical for closed-source models and expensive for open-source ones, with risks of catastrophic forgetting. Offline trajectories offer reusable knowledge, yet demonstration-based methods struggle because raw traces are long, noisy, and tied to specific tasks. We present Just-in-time Episodic Feedback Hinter (JEF Hinter), an agentic system that distills offline traces into compact, context-aware hints. A zooming mechanism highlights decisive steps in long trajectories, capturing both strategies and pitfalls. Unlike prior methods, JEF Hinter leverages both successful and failed trajectories, extracting guidance even when only failure data is available, while supporting parallelized hint generation and benchmark-independent prompting. At inference, a retriever selects relevant hints for the current state, providing targeted guidance with transparency and traceability. Experiments on MiniWoB++, WorkArena-L1, and WebArena-Lite show that JEF Hinter consistently outperforms strong baselines, including human- and document-based hints.
Sensitivity of Generative VLMs to Semantically and Lexically Altered Prompts
Oct 16, 2024



Despite the significant influx of prompt-tuning techniques for generative vision-language models (VLMs), it remains unclear how sensitive these models are to lexical and semantic alterations in prompts. In this paper, we evaluate the ability of generative VLMs to understand lexical and semantic changes in text using the SugarCrepe++ dataset. We analyze the sensitivity of VLMs to lexical alterations in prompts without corresponding semantic changes. Our findings demonstrate that generative VLMs are highly sensitive to such alterations. Additionally, we show that this vulnerability affects the performance of techniques aimed at achieving consistency in their outputs.
SUGARCREPE++ Dataset: Vision-Language Model Sensitivity to Semantic and Lexical Alterations
Jun 17, 2024



Despite their remarkable successes, state-of-the-art large language models (LLMs), including vision-and-language models (VLMs) and unimodal language models (ULMs), fail to understand precise semantics. For example, semantically equivalent sentences expressed using different lexical compositions elicit diverging representations. The degree of this divergence and its impact on encoded semantics is not very well understood. In this paper, we introduce the SUGARCREPE++ dataset to analyze the sensitivity of VLMs and ULMs to lexical and semantic alterations. Each sample in SUGARCREPE++ dataset consists of an image and a corresponding triplet of captions: a pair of semantically equivalent but lexically different positive captions and one hard negative caption. This poses a 3-way semantic (in)equivalence problem to the language models. We comprehensively evaluate VLMs and ULMs that differ in architecture, pre-training objectives and datasets to benchmark the performance of SUGARCREPE++ dataset. Experimental results highlight the difficulties of VLMs in distinguishing between lexical and semantic variations, particularly in object attributes and spatial relations. Although VLMs with larger pre-training datasets, model sizes, and multiple pre-training objectives achieve better performance on SUGARCREPE++, there is a significant opportunity for improvement. We show that all the models which achieve better performance on compositionality datasets need not perform equally well on SUGARCREPE++, signifying that compositionality alone may not be sufficient for understanding semantic and lexical alterations. Given the importance of the property that the SUGARCREPE++ dataset targets, it serves as a new challenge to the vision-and-language community.
VISLA Benchmark: Evaluating Embedding Sensitivity to Semantic and Lexical Alterations
Apr 25, 2024



Despite their remarkable successes, state-of-the-art language models face challenges in grasping certain important semantic details. This paper introduces the VISLA (Variance and Invariance to Semantic and Lexical Alterations) benchmark, designed to evaluate the semantic and lexical understanding of language models. VISLA presents a 3-way semantic (in)equivalence task with a triplet of sentences associated with an image, to evaluate both vision-language models (VLMs) and unimodal language models (ULMs). An evaluation involving 34 VLMs and 20 ULMs reveals surprising difficulties in distinguishing between lexical and semantic variations. Spatial semantics encoded by language models also appear to be highly sensitive to lexical information. Notably, text encoders of VLMs demonstrate greater sensitivity to semantic and lexical variations than unimodal text encoders. Our contributions include the unification of image-to-text and text-to-text retrieval tasks, an off-the-shelf evaluation without fine-tuning, and assessing LMs' semantic (in)variance in the presence of lexical alterations. The results highlight strengths and weaknesses across diverse vision and unimodal language models, contributing to a deeper understanding of their capabilities. % VISLA enables a rigorous evaluation, shedding light on language models' capabilities in handling semantic and lexical nuances. Data and code will be made available at https://github.com/Sri-Harsha/visla_benchmark.
Breaking the Token Barrier: Chunking and Convolution for Efficient Long Text Classification with BERT
Oct 31, 2023



Transformer-based models, specifically BERT, have propelled research in various NLP tasks. However, these models are limited to a maximum token limit of 512 tokens. Consequently, this makes it non-trivial to apply it in a practical setting with long input. Various complex methods have claimed to overcome this limit, but recent research questions the efficacy of these models across different classification tasks. These complex architectures evaluated on carefully curated long datasets perform at par or worse than simple baselines. In this work, we propose a relatively simple extension to vanilla BERT architecture called ChunkBERT that allows finetuning of any pretrained models to perform inference on arbitrarily long text. The proposed method is based on chunking token representations and CNN layers, making it compatible with any pre-trained BERT. We evaluate chunkBERT exclusively on a benchmark for comparing long-text classification models across a variety of tasks (including binary classification, multi-class classification, and multi-label classification). A BERT model finetuned using the ChunkBERT method performs consistently across long samples in the benchmark while utilizing only a fraction (6.25\%) of the original memory footprint. These findings suggest that efficient finetuning and inference can be achieved through simple modifications to pre-trained BERT models.
Triage of Potential COVID-19 Patients from Chest X-ray Images using Hierarchical Convolutional Networks
Nov 01, 2020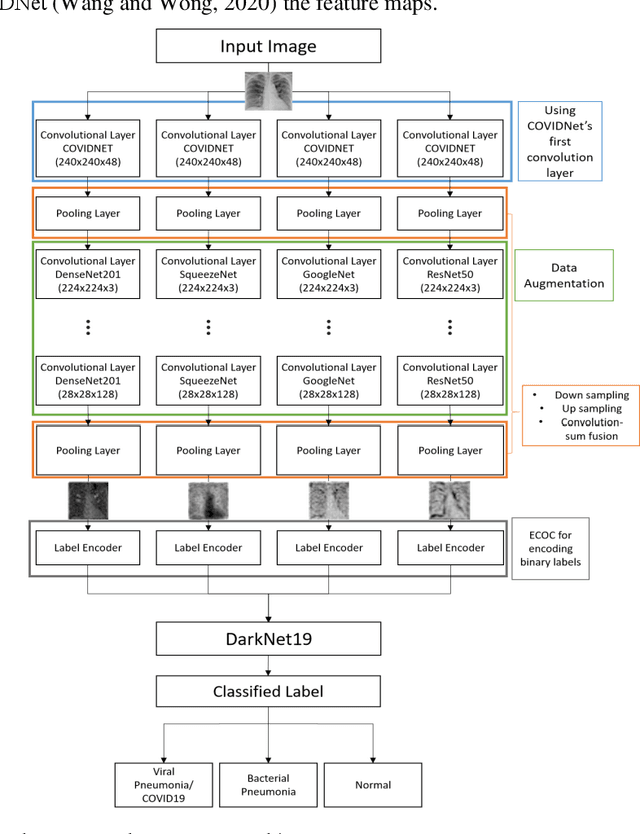
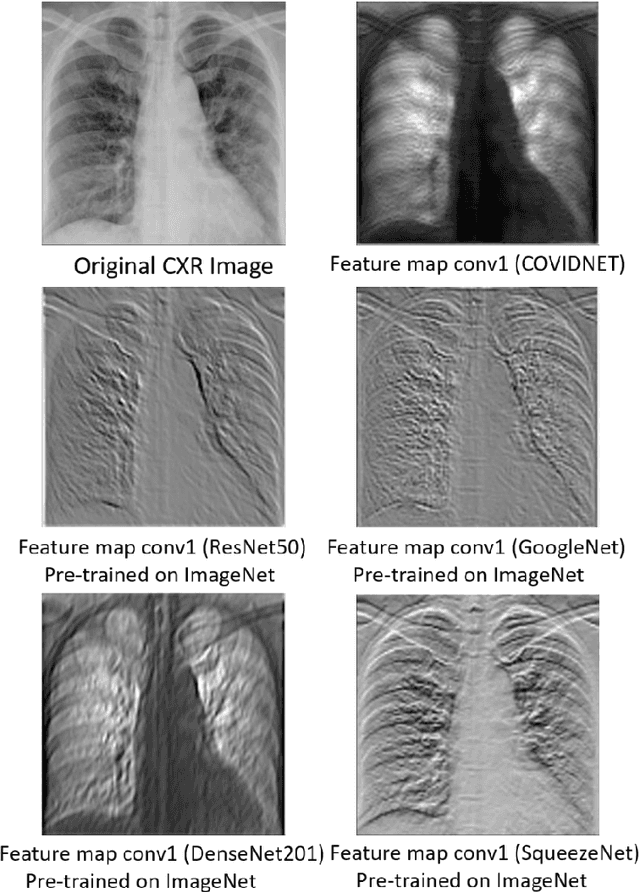

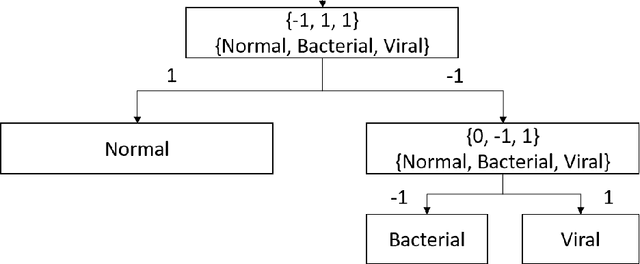
The current COVID-19 pandemic has motivated the researchers to use artificial intelligence techniques for potential alternatives to reverse transcription polymerase chain reaction (RT-PCR) due to the limited scale of testing. The chest X-ray (CXR) is one of the alternatives to achieve fast diagnosis but the unavailability of large scale annotated data makes the clinical implementation of machine learning-based COVID detection methods difficult. Another important issue is the usage of ImageNet pre-trained networks which does not guarantee to extract reliable feature representations. In this paper, we propose the use of hierarchical convolutional network (HCN) architecture to naturally augment the data along with diversified features. The HCN uses the first convolution layer from COVIDNet followed by the convolutional layers from well known pre-trained networks to extract the features. The use of the convolution layer from COVIDNet ensures the extraction of representations relevant to the CXR modality. We also propose the use of ECOC for encoding multiclass problems to binary classification for improving the recognition performance. Experimental results show that HCN architecture is capable of achieving better results in comparison to the existing studies. The proposed method can accurately triage potential COVID-19 patients through CXR images for sharing the testing load and increasing the testing capacity.