Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriving a Representative Vector for Ontology Classes with Instance Word Vector Embeddings
Jun 08, 2017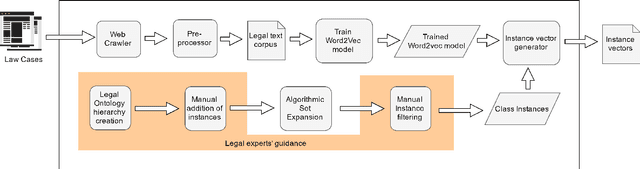
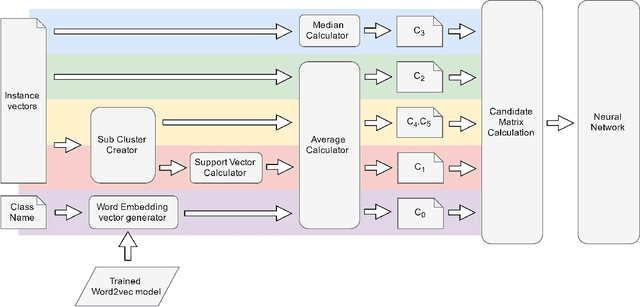
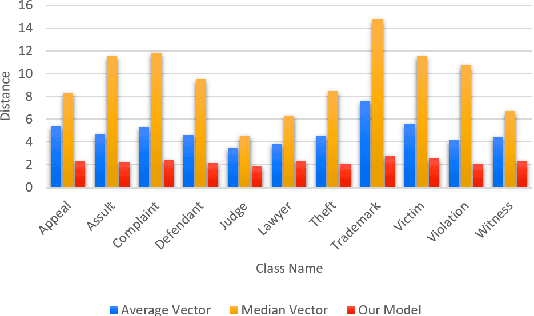
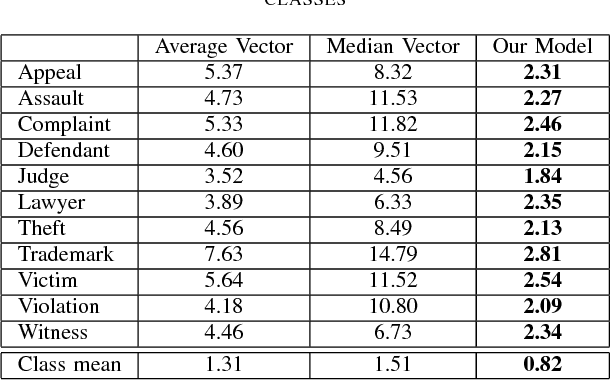
Selecting a representative vector for a set of vectors is a very common requirement in many algorithmic tasks. Traditionally, the mean or median vector is selected. Ontology classes are sets of homogeneous instance objects that can be converted to a vector space by word vector embeddings. This study proposes a methodology to derive a representative vector for ontology classes whose instances were converted to the vector space. We start by deriving five candidate vectors which are then used to train a machine learning model that would calculate a representative vector for the class. We show that our methodology out-performs the traditional mean and median vector representations.
Via