 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Resource Multi-Dialectal Arabic Natural Language Understanding
Apr 14, 2021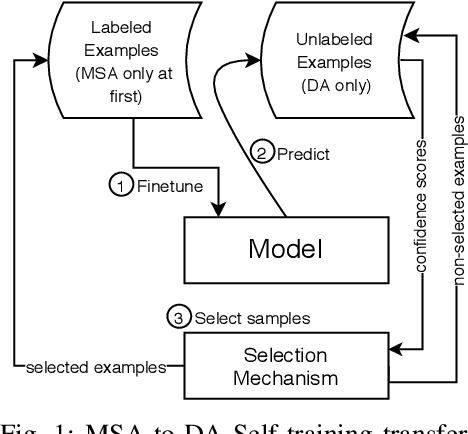
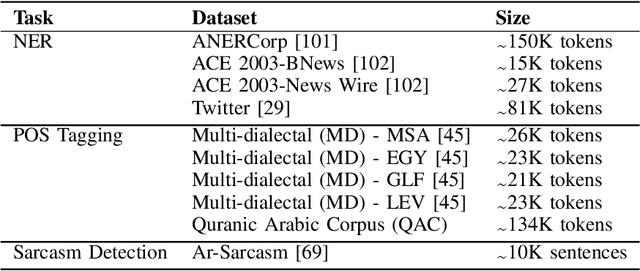
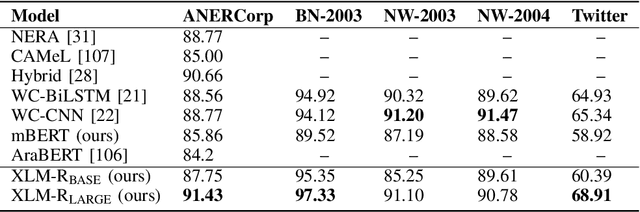
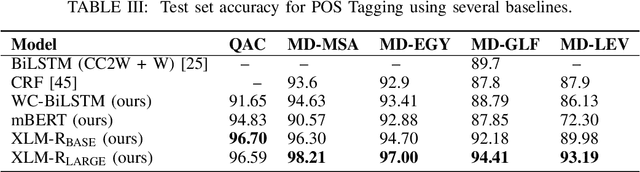
A reasonable amount of annotated data is required for fine-tuning pre-trained language models (PLM) on downstream tasks. However, obtaining labeled examples for different language varieties can be costly. In this paper, we investigate the zero-shot performance on Dialectal Arabic (DA) when fine-tuning a PLM on modern standard Arabic (MSA) data only -- identifying a significant performance drop when evaluating such models on DA. To remedy such performance drop, we propose self-training with unlabeled DA data and apply it in the context of named entity recognition (NER), part-of-speech (POS) tagging, and sarcasm detection (SRD) on several DA varieties. Our results demonstrate the effectiveness of self-training with unlabeled DA data: improving zero-shot MSA-to-DA transfer by as large as \texttildelow 10\% F$_1$ (NER), 2\% accuracy (POS tagging), and 4.5\% F$_1$ (SRD). We conduct an ablation experiment and show that the performance boost observed directly results from the unlabeled DA examples used for self-training. Our work opens up opportunities for leveraging the relatively abundant labeled MSA datasets to develop DA models for zero and low-resource dialects. We also report new state-of-the-art performance on all three tasks and open-source our fine-tuned models for the research community.
Sheep identity recognition, age and weight estimation datasets
Jun 08, 2018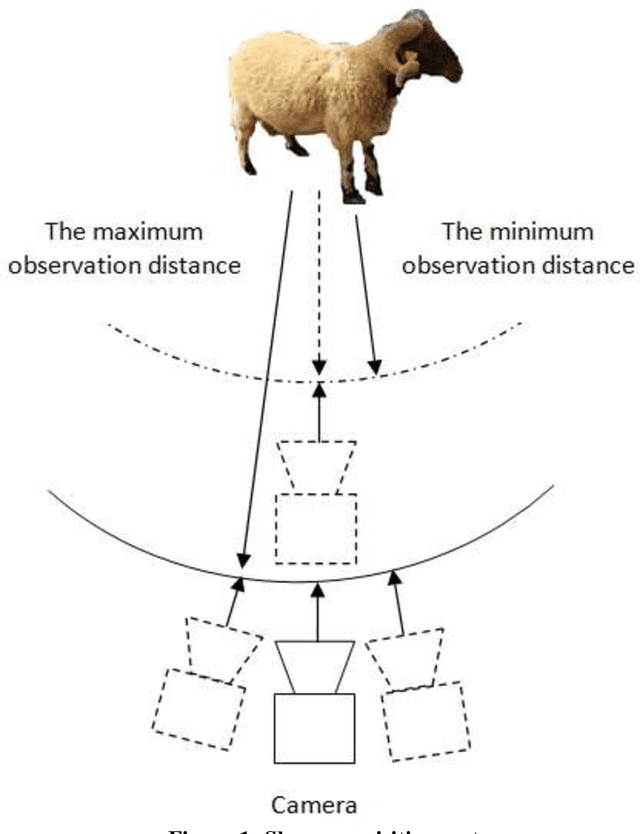
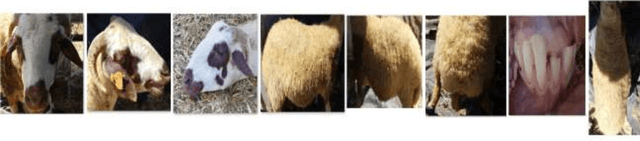

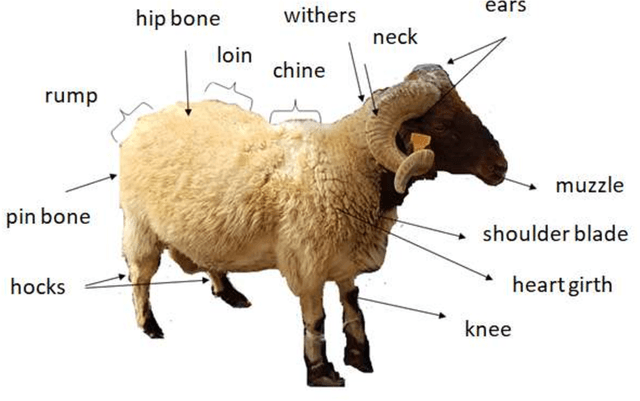
Increased interest of scientists, producers and consumers in sheep identification has been stimulated by the dramatic increase in population and the urge to increase productivity. The world population is expected to exceed 9.6 million in 2050. For this reason, awareness is raised towards the necessity of effective livestock production. Sheep is considered as one of the main of food resources. Most of the research now is directed towards developing real time applications that facilitate sheep identification for breed management and gathering related information like weight and age. Weight and age are key matrices in assessing the effectiveness of production. For this reason, visual analysis proved recently its significant success over other approaches. Visual analysis techniques need enough images for testing and study completion. For this reason, collecting sheep images database is a vital step to fulfill such objective. We provide here datasets for testing and comparing such algorithms which are under development. Our collected dataset consists of 416 color images for different features of sheep in different postures. Images were collected fifty two sheep at a range of year from three months to six years. For each sheep, two images were captured for both sides of the body, two images for both sides of the face, one image from the top view, one image for the hip and one image for the teeth. The collected images cover different illumination, quality levels and angle of rotation. The allocated data set can be used to test sheep identification, weigh estimation, and age detection algorithms. Such algorithms are crucial for disease management, animal assessment and ownership.
A Machine Learning Approach For Opinion Holder Extraction In Arabic Language
Apr 06, 2012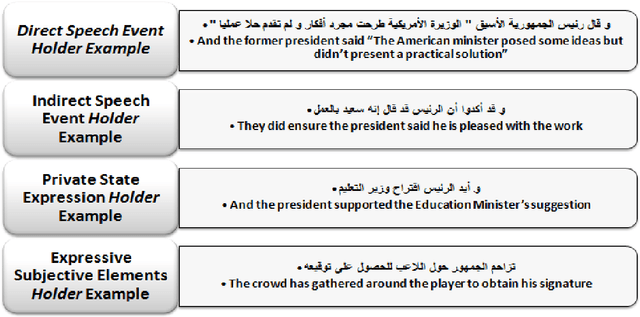
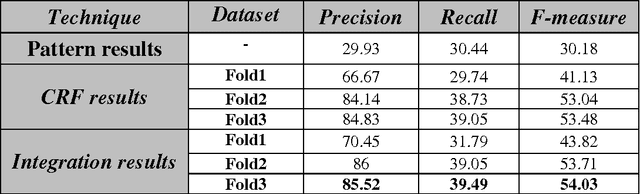

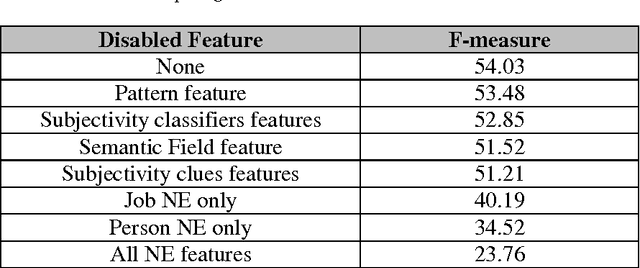
Opinion mining aims at extracting useful subjective information from reliable amounts of text. Opinion mining holder recognition is a task that has not been considered yet in Arabic Language. This task essentially requires deep understanding of clauses structures. Unfortunately, the lack of a robust, publicly available, Arabic parser further complicates the research. This paper presents a leading research for the opinion holder extraction in Arabic news independent from any lexical parsers. We investigate constructing a comprehensive feature set to compensate the lack of parsing structural outcomes. The proposed feature set is tuned from English previous works coupled with our proposed semantic field and named entities features. Our feature analysis is based on Conditional Random Fields (CRF) and semi-supervised pattern recognition techniques. Different research models are evaluated via cross-validation experiments achieving 54.03 F-measure. We publicly release our own research outcome corpus and lexicon for opinion mining community to encourage further research.