 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Taxonomy of Explainable Bayesian Networks
Jan 28, 2021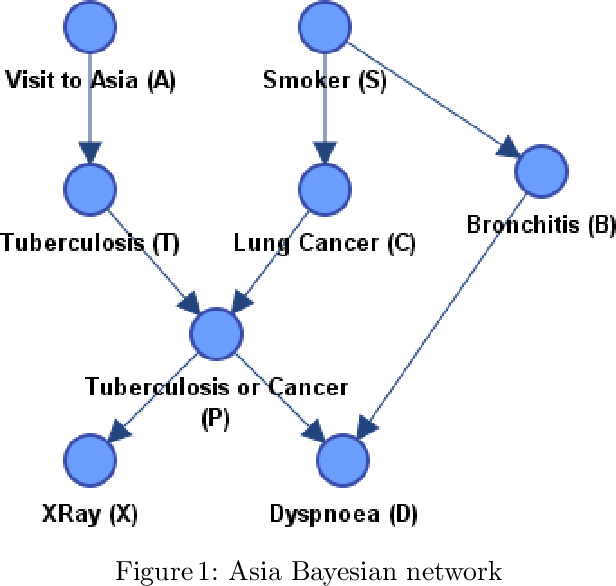
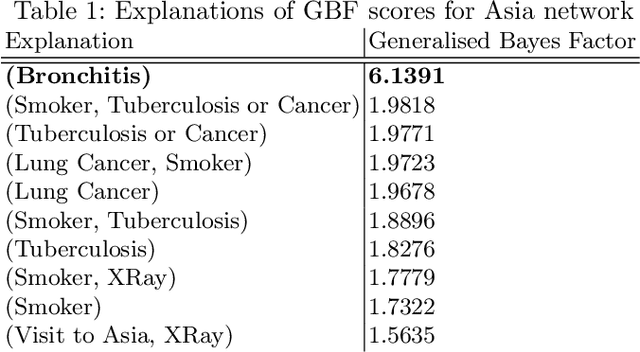
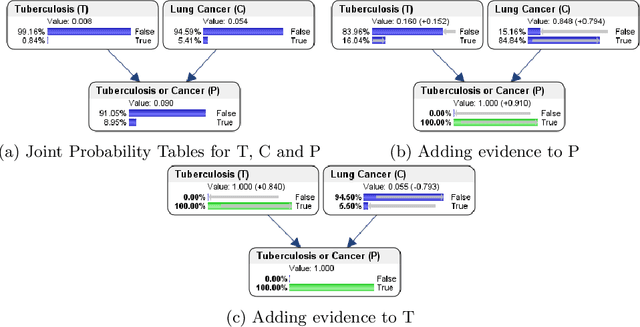
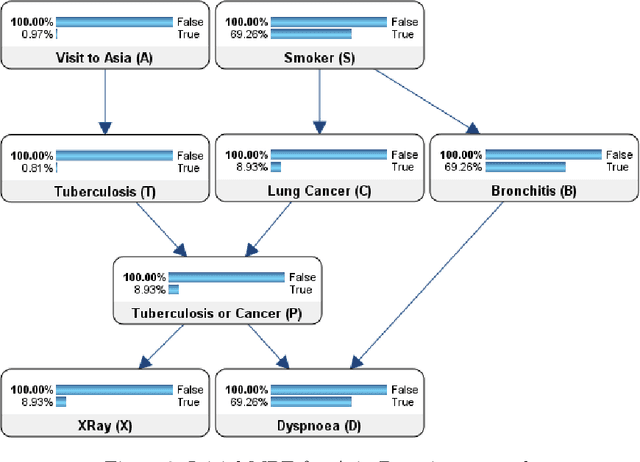
Artificial Intelligence (AI), and in particular, the explainability thereof, has gained phenomenal attention over the last few years. Whilst we usually do not question the decision-making process of these systems in situations where only the outcome is of interest, we do however pay close attention when these systems are applied in areas where the decisions directly influence the lives of humans. It is especially noisy and uncertain observations close to the decision boundary which results in predictions which cannot necessarily be explained that may foster mistrust among end-users. This drew attention to AI methods for which the outcomes can be explained. Bayesian networks are probabilistic graphical models that can be used as a tool to manage uncertainty. The probabilistic framework of a Bayesian network allows for explainability in the model, reasoning and evidence. The use of these methods is mostly ad hoc and not as well organised as explainability methods in the wider AI research field. As such, we introduce a taxonomy of explainability in Bayesian networks. We extend the existing categorisation of explainability in the model, reasoning or evidence to include explanation of decisions. The explanations obtained from the explainability methods are illustrated by means of a simple medical diagnostic scenario. The taxonomy introduced in this paper has the potential not only to encourage end-users to efficiently communicate outcomes obtained, but also support their understanding of how and, more importantly, why certain predictions were made.
A Gamma-Poisson Mixture Topic Model for Short Text
Apr 23, 2020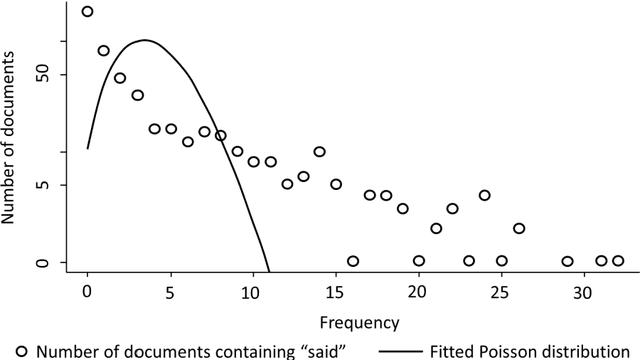

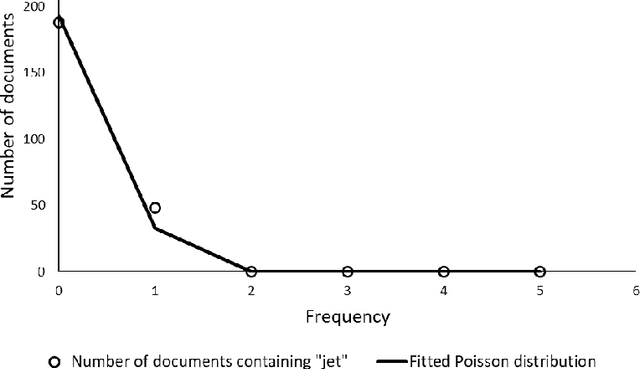
Most topic models are constructed under the assumption that documents follow a multinomial distribution. The Poisson distribution is an alternative distribution to describe the probability of count data. For topic modelling, the Poisson distribution describes the number of occurrences of a word in documents of fixed length. The Poisson distribution has been successfully applied in text classification, but its application to topic modelling is not well documented, specifically in the context of a generative probabilistic model. Furthermore, the few Poisson topic models in literature are admixture models, making the assumption that a document is generated from a mixture of topics. In this study, we focus on short text. Many studies have shown that the simpler assumption of a mixture model fits short text better. With mixture models, as opposed to admixture models, the generative assumption is that a document is generated from a single topic. One topic model, which makes this one-topic-per-document assumption, is the Dirichlet-multinomial mixture model. The main contributions of this work are a new Gamma-Poisson mixture model, as well as a collapsed Gibbs sampler for the model. The benefit of the collapsed Gibbs sampler derivation is that the model is able to automatically select the number of topics contained in the corpus. The results show that the Gamma-Poisson mixture model performs better than the Dirichlet-multinomial mixture model at selecting the number of topics in labelled corpora. Furthermore, the Gamma-Poisson mixture produces better topic coherence scores than the Dirichlet-multinomial mixture model, thus making it a viable option for the challenging task of topic modelling of short text.