 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNurtureNet: A Multi-task Video-based Approach for Newborn Anthropometry
May 09, 2024Malnutrition among newborns is a top public health concern in developing countries. Identification and subsequent growth monitoring are key to successful interventions. However, this is challenging in rural communities where health systems tend to be inaccessible and under-equipped, with poor adherence to protocol. Our goal is to equip health workers and public health systems with a solution for contactless newborn anthropometry in the community. We propose NurtureNet, a multi-task model that fuses visual information (a video taken with a low-cost smartphone) with tabular inputs to regress multiple anthropometry estimates including weight, length, head circumference, and chest circumference. We show that visual proxy tasks of segmentation and keypoint prediction further improve performance. We establish the efficacy of the model through several experiments and achieve a relative error of 3.9% and mean absolute error of 114.3 g for weight estimation. Model compression to 15 MB also allows offline deployment to low-cost smartphones.
Predicting Treatment Adherence of Tuberculosis Patients at Scale
Nov 15, 2022



Tuberculosis (TB), an infectious bacterial disease, is a significant cause of death, especially in low-income countries, with an estimated ten million new cases reported globally in $2020$. While TB is treatable, non-adherence to the medication regimen is a significant cause of morbidity and mortality. Thus, proactively identifying patients at risk of dropping off their medication regimen enables corrective measures to mitigate adverse outcomes. Using a proxy measure of extreme non-adherence and a dataset of nearly $700,000$ patients from four states in India, we formulate and solve the machine learning (ML) problem of early prediction of non-adherence based on a custom rank-based metric. We train ML models and evaluate against baselines, achieving a $\sim 100\%$ lift over rule-based baselines and $\sim 214\%$ over a random classifier, taking into account country-wide large-scale future deployment. We deal with various issues in the process, including data quality, high-cardinality categorical data, low target prevalence, distribution shift, variation across cohorts, algorithmic fairness, and the need for robustness and explainability. Our findings indicate that risk stratification of non-adherent patients is a viable, deployable-at-scale ML solution. As the official AI partner of India's Central TB Division, we are working on multiple city and state-level pilots with the goal of pan-India deployment.
Interpretability of Epidemiological Models : The Curse of Non-Identifiability
Apr 30, 2021
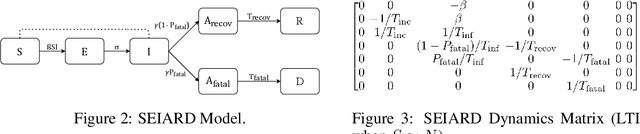


Interpretability of epidemiological models is a key consideration, especially when these models are used in a public health setting. Interpretability is strongly linked to the identifiability of the underlying model parameters, i.e., the ability to estimate parameter values with high confidence given observations. In this paper, we define three separate notions of identifiability that explore the different roles played by the model definition, the loss function, the fitting methodology, and the quality and quantity of data. We define an epidemiological compartmental model framework in which we highlight these non-identifiability issues and their mitigation.