 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunt Globally: Wide Search AI Agents for Drug Asset Scouting in Investing, Business Development, and Competitive Intelligence
Feb 17, 2026Bio-pharmaceutical innovation has shifted: many new drug assets now originate outside the United States and are disclosed primarily via regional, non-English channels. Recent data suggests that over 85% of patent filings originate outside the U.S., with China accounting for nearly half of the global total. A growing share of scholarly output is also non-U.S. Industry estimates put China at 30% of global drug development, spanning 1,200+ novel candidates. In this high-stakes environment, failing to surface "under-the-radar" assets creates multi-billion-dollar risk for investors and business development teams, making asset scouting a coverage-critical competition where speed and completeness drive value. Yet today's Deep Research AI agents still lag human experts in achieving high recall discovery across heterogeneous, multilingual sources without hallucination. We propose a benchmarking methodology for drug asset scouting and a tuned, tree-based self-learning Bioptic Agent aimed at complete, non-hallucinated scouting. We construct a challenging completeness benchmark using a multilingual multi-agent pipeline: complex user queries paired with ground-truth assets that are largely outside U.S.-centric radar. To reflect real-deal complexity, we collected screening queries from expert investors, BD, and VC professionals and used them as priors to conditionally generate benchmark queries. For grading, we use LLM-as-judge evaluation calibrated to expert opinions. On this benchmark, our Bioptic Agent achieves 79.7% F1 score, outperforming Claude Opus 4.6 (56.2%), Gemini 3 Pro + Deep Research (50.6%), OpenAI GPT-5.2 Pro (46.6%), Perplexity Deep Research (44.2%), and Exa Websets (26.9%). Performance improves steeply with additional compute, supporting the view that more compute yields better results.
STC speaker recognition systems for the NIST SRE 2021
Nov 03, 2021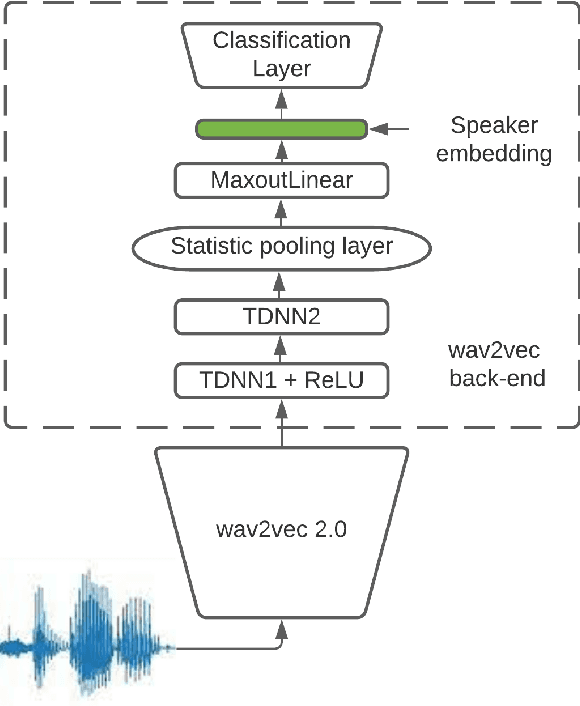
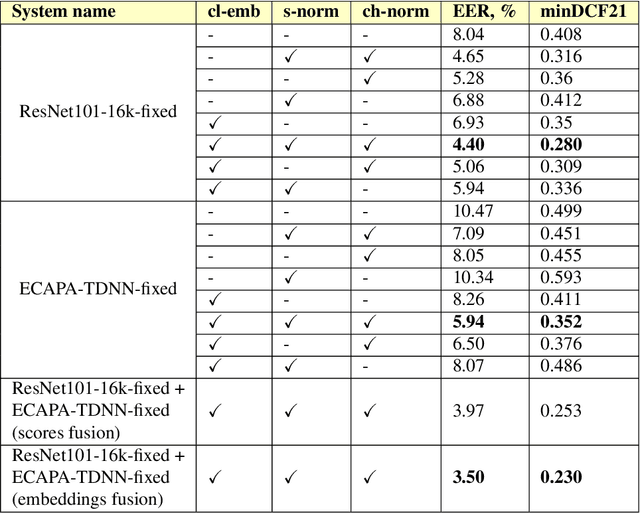
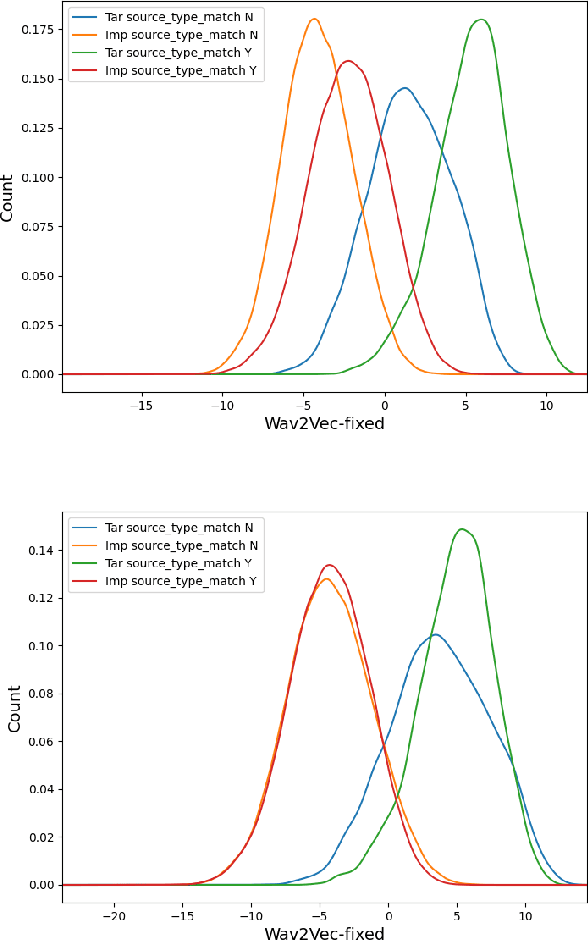
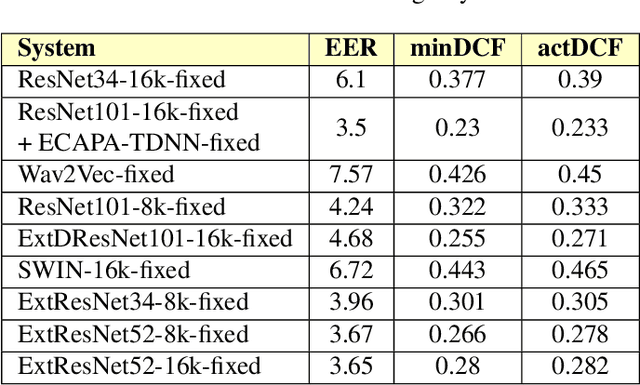
This paper presents a description of STC Ltd. systems submitted to the NIST 2021 Speaker Recognition Evaluation for both fixed and open training conditions. These systems consists of a number of diverse subsystems based on using deep neural networks as feature extractors. During the NIST 2021 SRE challenge we focused on the training of the state-of-the-art deep speaker embeddings extractors like ResNets and ECAPA networks by using additive angular margin based loss functions. Additionally, inspired by the recent success of the wav2vec 2.0 features in automatic speech recognition we explored the effectiveness of this approach for the speaker verification filed. According to our observation the fine-tuning of the pretrained large wav2vec 2.0 model provides our best performing systems for open track condition. Our experiments with wav2vec 2.0 based extractors for the fixed condition showed that unsupervised autoregressive pretraining with Contrastive Predictive Coding loss opens the door to training powerful transformer-based extractors from raw speech signals. For video modality we developed our best solution with RetinaFace face detector and deep ResNet face embeddings extractor trained on large face image datasets. The final results for primary systems were obtained by different configurations of subsystems fusion on the score level followed by score calibration.