 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Trace-Based Assurance Framework for Agentic AI Orchestration: Contracts, Testing, and Governance
Mar 18, 2026In Agentic AI, Large Language Models (LLMs) are increasingly used in the orchestration layer to coordinate multiple agents and to interact with external services, retrieval components, and shared memory. In this setting, failures are not limited to incorrect final outputs. They also arise from long-horizon interaction, stochastic decisions, and external side effects (such as API calls, database writes, and message sends). Common failures include non-termination, role drift, propagation of unsupported claims, and attacks via untrusted context or external channels. This paper presents an assurance framework for such Agentic AI systems. Executions are instrumented as Message-Action Traces (MAT) with explicit step and trace contracts. Contracts provide machine-checkable verdicts, localize the first violating step, and support deterministic replay. The framework includes stress testing, formulated as a budgeted counterexample search over bounded perturbations. It also supports structured fault injection at service, retrieval, and memory boundaries to assess containment under realistic operational faults and degraded conditions. Finally, governance is treated as a runtime component, enforcing per-agent capability limits and action mediation (allow, rewrite, block) at the language-to-action boundary. To support comparative evaluations across stochastic seeds, models, and orchestration configurations, the paper defines trace-based metrics for task success, termination reliability, contract compliance, factuality indicators, containment rate, and governance outcome distributions. More broadly, the framework is intended as a common abstraction to support testing and evaluation of multi-agent LLM systems, and to facilitate reproducible comparison across orchestration designs and configurations.
EvoBA: An Evolution Strategy as a Strong Baseline forBlack-Box Adversarial Attacks
Jul 12, 2021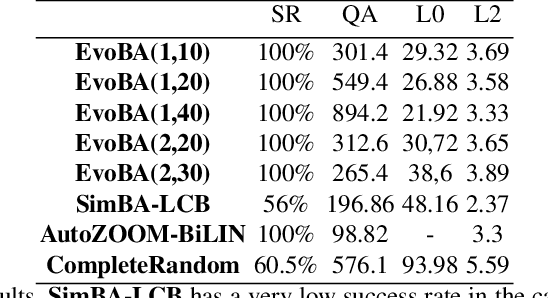
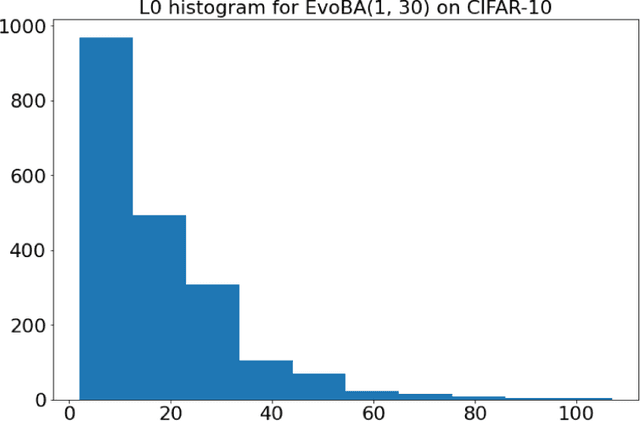
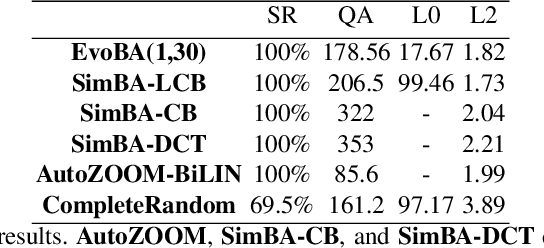
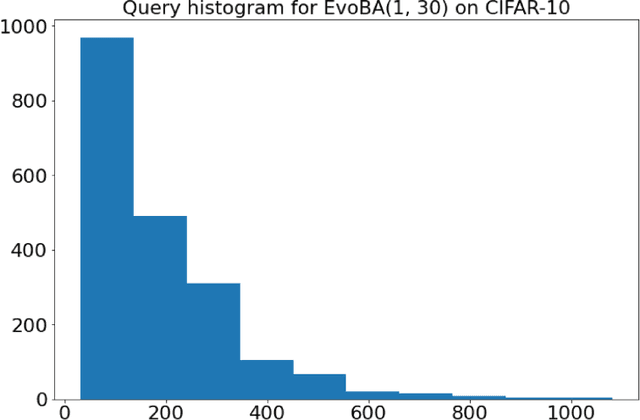
Recent work has shown how easily white-box adversarial attacks can be applied to state-of-the-art image classifiers. However, real-life scenarios resemble more the black-box adversarial conditions, lacking transparency and usually imposing natural, hard constraints on the query budget. We propose $\textbf{EvoBA}$, a black-box adversarial attack based on a surprisingly simple evolutionary search strategy. $\textbf{EvoBA}$ is query-efficient, minimizes $L_0$ adversarial perturbations, and does not require any form of training. $\textbf{EvoBA}$ shows efficiency and efficacy through results that are in line with much more complex state-of-the-art black-box attacks such as $\textbf{AutoZOOM}$. It is more query-efficient than $\textbf{SimBA}$, a simple and powerful baseline black-box attack, and has a similar level of complexity. Therefore, we propose it both as a new strong baseline for black-box adversarial attacks and as a fast and general tool for gaining empirical insight into how robust image classifiers are with respect to $L_0$ adversarial perturbations. There exist fast and reliable $L_2$ black-box attacks, such as $\textbf{SimBA}$, and $L_{\infty}$ black-box attacks, such as $\textbf{DeepSearch}$. We propose $\textbf{EvoBA}$ as a query-efficient $L_0$ black-box adversarial attack which, together with the aforementioned methods, can serve as a generic tool to assess the empirical robustness of image classifiers. The main advantages of such methods are that they run fast, are query-efficient, and can easily be integrated in image classifiers development pipelines. While our attack minimises the $L_0$ adversarial perturbation, we also report $L_2$, and notice that we compare favorably to the state-of-the-art $L_2$ black-box attack, $\textbf{AutoZOOM}$, and of the $L_2$ strong baseline, $\textbf{SimBA}$.