 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimension Reduction by Mutual Information Feature Extraction
Jul 14, 2012
During the past decades, to study high-dimensional data in a large variety of problems, researchers have proposed many Feature Extraction algorithms. One of the most effective approaches for optimal feature extraction is based on mutual information (MI). However it is not always easy to get an accurate estimation for high dimensional MI. In terms of MI, the optimal feature extraction is creating a feature set from the data which jointly have the largest dependency on the target class and minimum redundancy. In this paper, a component-by-component gradient ascent method is proposed for feature extraction which is based on one-dimensional MI estimates. We will refer to this algorithm as Mutual Information Feature Extraction (MIFX). The performance of this proposed method is evaluated using UCI databases. The results indicate that MIFX provides a robust performance over different data sets which are almost always the best or comparable to the best ones.
Dimension Reduction by Mutual Information Discriminant Analysis
Jun 10, 2012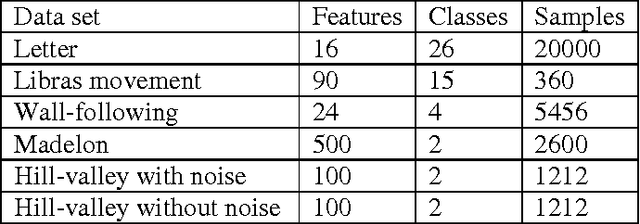
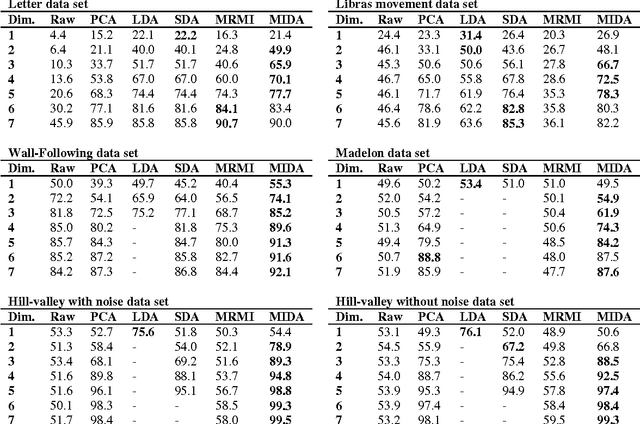
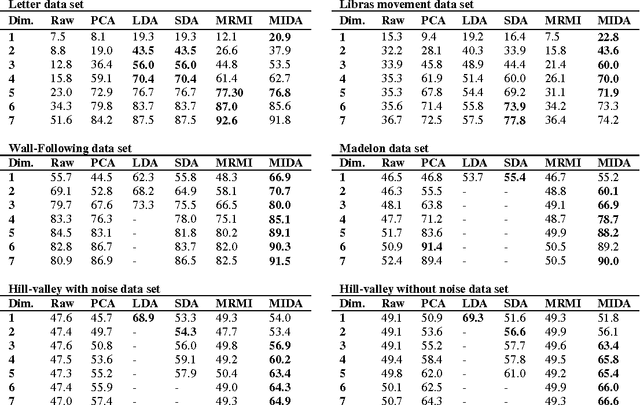
In the past few decades, researchers have proposed many discriminant analysis (DA) algorithms for the study of high-dimensional data in a variety of problems. Most DA algorithms for feature extraction are based on transformations that simultaneously maximize the between-class scatter and minimize the withinclass scatter matrices. This paper presents a novel DA algorithm for feature extraction using mutual information (MI). However, it is not always easy to obtain an accurate estimation for high-dimensional MI. In this paper, we propose an efficient method for feature extraction that is based on one-dimensional MI estimations. We will refer to this algorithm as mutual information discriminant analysis (MIDA). The performance of this proposed method was evaluated using UCI databases. The results indicate that MIDA provides robust performance over different data sets with different characteristics and that MIDA always performs better than, or at least comparable to, the best performing algorithms.