 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability Analysis of Optimal Adaptive Control using Value Iteration with Approximation Errors
Oct 23, 2017
Adaptive optimal control using value iteration initiated from a stabilizing control policy is theoretically analyzed in terms of stability of the system during the learning stage without ignoring the effects of approximation errors. This analysis includes the system operated using any single/constant resulting control policy and also using an evolving/time-varying control policy. A feature of the presented results is providing estimations of the \textit{region of attraction} so that if the initial condition is within the region, the whole trajectory will remain inside it and hence, the function approximation results remain valid.
Convergence Analysis of Policy Iteration
May 20, 2015Adaptive optimal control of nonlinear dynamic systems with deterministic and known dynamics under a known undiscounted infinite-horizon cost function is investigated. Policy iteration scheme initiated using a stabilizing initial control is analyzed in solving the problem. The convergence of the iterations and the optimality of the limit functions, which follows from the established uniqueness of the solution to the Bellman equation, are the main results of this study. Furthermore, a theoretical comparison between the speed of convergence of policy iteration versus value iteration is presented. Finally, the convergence results are extended to the case of multi-step look-ahead policy iteration.
Stabilizing Value Iteration with and without Approximation Errors
May 15, 2015Adaptive optimal control using value iteration (VI) initiated from a stabilizing policy is theoretically analyzed in various aspects including the continuity of the result, the stability of the system operated using any single/constant resulting control policy, the stability of the system operated using the evolving/time-varying control policy, the convergence of the algorithm, and the optimality of the limit function. Afterwards, the effect of presence of approximation errors in the involved function approximation processes is incorporated and another set of results for boundedness of the approximate VI as well as stability of the system operated under the results for both cases of applying a single policy or an evolving policy are derived. A feature of the presented results is providing estimations of the region of attraction so that if the initial condition is within the region, the whole trajectory will remain inside it and hence, the function approximation results will be reliable.
Theoretical and Numerical Analysis of Approximate Dynamic Programming with Approximation Errors
May 15, 2015

This study is aimed at answering the famous question of how the approximation errors at each iteration of Approximate Dynamic Programming (ADP) affect the quality of the final results considering the fact that errors at each iteration affect the next iteration. To this goal, convergence of Value Iteration scheme of ADP for deterministic nonlinear optimal control problems with undiscounted cost functions is investigated while considering the errors existing in approximating respective functions. The boundedness of the results around the optimal solution is obtained based on quantities which are known in a general optimal control problem and assumptions which are verifiable. Moreover, since the presence of the approximation errors leads to the deviation of the results from optimality, sufficient conditions for stability of the system operated by the result obtained after a finite number of value iterations, along with an estimation of its region of attraction, are derived in terms of a calculable upper bound of the control approximation error. Finally, the process of implementation of the method on an orbital maneuver problem is investigated through which the assumptions made in the theoretical developments are verified and the sufficient conditions are applied for guaranteeing stability and near optimality.
Optimal Triggering of Networked Control Systems
Dec 17, 2014


The problem of resource allocation of nonlinear networked control systems is investigated, where, unlike the well discussed case of triggering for stability, the objective is optimal triggering. An approximate dynamic programming approach is developed for solving problems with fixed final times initially and then it is extended to infinite horizon problems. Different cases including Zero-Order-Hold, Generalized Zero-Order-Hold, and stochastic networks are investigated. Afterwards, the developments are extended to the case of problems with unknown dynamics and a model-free scheme is presented for learning the (approximate) optimal solution. After detailed analyses of convergence, optimality, and stability of the results, the performance of the method is demonstrated through different numerical examples.
Feedback Solution to Optimal Switching Problems with Switching Cost
Nov 17, 2014
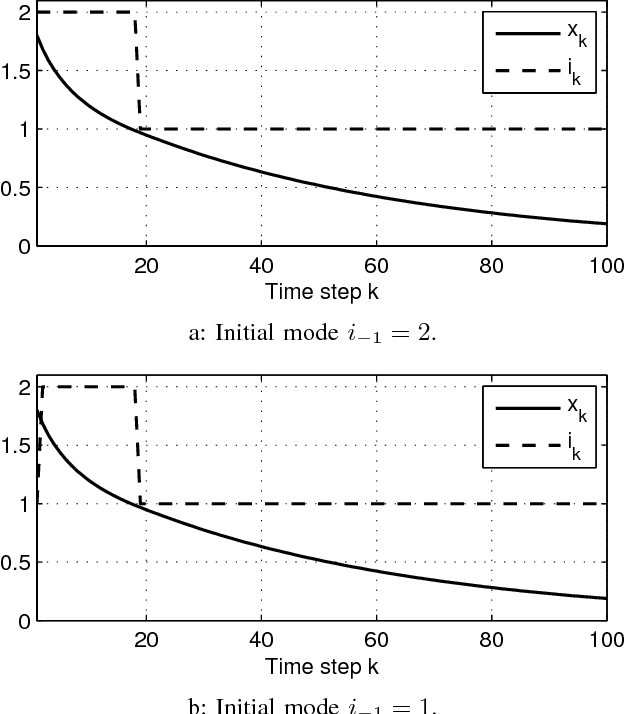
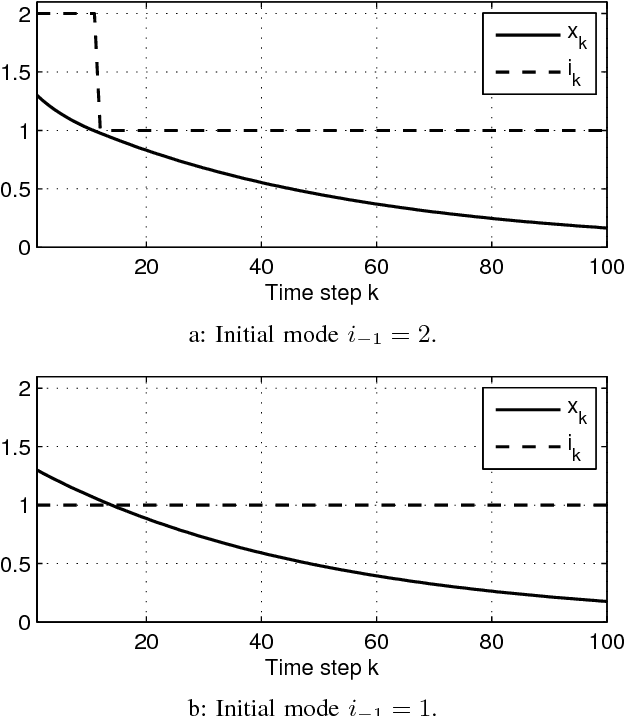
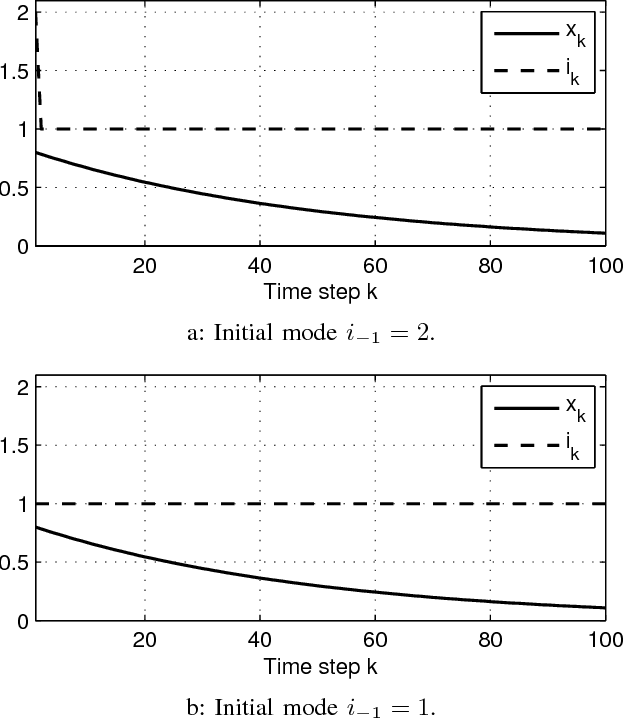
The problem of optimal switching between nonlinear autonomous subsystems is investigated in this study where the objective is not only bringing the states to close to the desired point, but also adjusting the switching pattern, in the sense of penalizing switching occurrences and assigning different preferences to utilization of different modes. The mode sequence is unspecified and a switching cost term is used in the cost function for penalizing each switching. It is shown that once a switching cost is incorporated, the optimal cost-to-go function depends on the already active subsystem, i.e., the subsystem which was engaged in the previous time step. Afterwards, an approximate dynamic programming based method is developed which provides an approximation of the optimal solution to the problem in a feedback form and for different initial conditions. Finally, the performance of the method is analyzed through numerical examples.